第1章 绪论
深度学习是机器学习的一个分支,是指一类问题以及解决这类问题的方法。
首先,深度学习是一个机器学习问题,指从有限样例中通过算法总结出一般性的规律,并可以应用到新的未知数据上。
其次,深度学习采用的模型一般比较复杂,指样本的原始输入到输出目标之间的数据流经过多个线性或非线性的组件。
1.1 人工智能
简单地讲,人工智能就是让机器具有人类的只能,这也是人们长期追求的目标。
由于“智能”一词比较难以定义,图灵提出了著名的图灵测试:“一个人在不接触对方的情况下,通过一种特殊的方式和对方进行一系列的问答。如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么就可以认为这个计算机是智能的。”
人工智能这个学科的诞生有着明确的标志性事件,就是1956年的达特茅斯会议。在这次会议上,“人工智能”被提出并作为本研究领域的名称。
John McCarthy提出了人工智能的定义:人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。
1.1.1 人工智能的发展历史
人工智能从诞生至今,经历了一次又一次的繁荣与低谷,其发展历程大体上可以分为“推理期”、“知识期”和“学习期”。
1.1.1.1 推理期
在这个时期中,研究者开发了一系列的智能系统,比如几何定理证明器、语言翻译器等。这些初步的研究成功也使得研究者们对开发出具有人类智能的机器过于乐观,低估了实现人工智能的难度。随着研究的深入,研究者意识到这些推理规则过于简单,对项目难度评估不足,原来的乐观预期受到严重打击。人工智能的研究开始陷入低谷,很多人工智能项目的研究经费也被消减。
1.1.1.2 知识期
在这一时期,出现了各种各样的专家系统,并在特定的专业领域取得了很多成果。
1.1.1.3 学习期
此阶段就是机器学习阶段,机器学习的主要目的是设计和分析一些学习算法,让计算机可以从数据(经验)中自动分析获得规律,并利用学习到的规律对未知数据进行预测,从而帮助人们完成一些特定任务,提高开发效率。
下图给出了人工智能发展史上的重要事件。目前具备真正意义上的人工智能,这个目标看上去仍然遥遥无期。

1.1.2 人工智能的流派
(1)符号主义,又称逻辑主义、心理学派或计算机学派,是通过分析人类智能的功能,然后通过计算机来实现这些功能。
(2)连接主义,又称仿生学派或生理学派,是认知科学领域中的一类信息处理的方法和理论。
深度学习的主要模型神经网络就是一种连接主义模型。随着深度学习的发展,越来越多的研究者开始关注如何融合符号主义和连接主义,建立一种高效并且具有可解释性的模型。
1.2 机器学习
机器学习是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。机器学习可以看作是浅层学习,浅层学习的一个重要特点是不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。
机器学习模型一般会包含以下几个步骤:
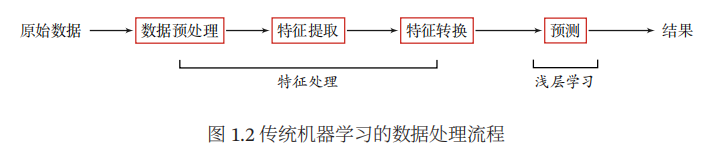
(1)数据预处理:经过数据的预处理,如去除噪声等。
(2)特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换特征等。
(3)特征转换:对特征进行一定的加工,比如降维和升维。降维包括特征抽取和特征选择两种途径。
(4)预测:机器学习的核心部分,学习一个函数进行过预测。
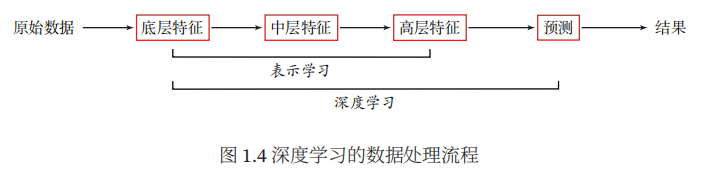
1.3 表示学习
为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性称为表示。如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就可以叫做表示学习。
在表示学习中,有两个核心问题:一是“什么是一个好的表示”;二是“如何学习到好的表示”。
1.3.1 局部表示和分布式表示
“好的表示”是一个非常主观的概念,没有一个明确的标准,但一般而言,一个好的表示具有以下几个优点:
(1)一个好的表示应该具有很强的表示能力,即同样大小的向量可以表示更多信息。
(2)一个好的表示应该使后续的学习任务变得简单,即需要包含更高层的语义信息。
(3)一个好的表示应该具有一般性,是任务或领域独立的。虽然目前的大部分表示学习方法还是基于某个任务来学习,但我们期望学到的表示可以比较容易地迁移到其他任务上。
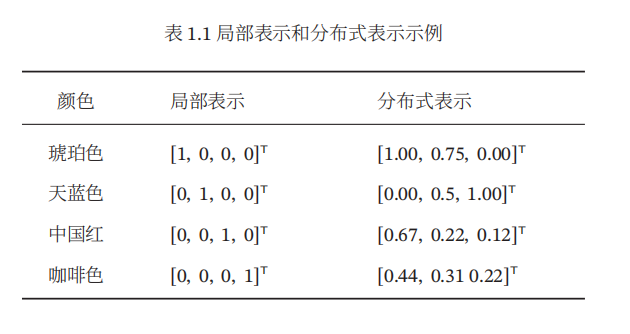
一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫做局部表示,也称为离散表示或符号表示。局部表示通常可以表示为one-hot向量的形式。
局部表示有两个优点:(1)这种离散的表示方式具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程。
(2)通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常高。
另一种表示颜色的方法是用RGN值来表示颜色,不同颜色对应到R、G、B三维空间中一个点,这种表示方式叫做分布式表示。
下表列出了4种颜色的局部表示和分布式表示
1.3.2 表示学习
表示学习的关键是构建具有一定深度的多层次特征表示。
1.4 深度学习
深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。
1.4.1 端到端学习
端到端学习,也称端到端训练,是指在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标。端到端学习和深度学习一样,都是要解决贡献度分配问题。目前,大部分采用神经网络模型的深度学习也可以看作是一种端到端的学习。
1.5 神经网络
受到人脑神经系统的启发,早期的神经科学家构造了一种模仿人脑神经系统的数学模型,称为人工神经网络,简称神经网络。
1.5.1 人脑神经网络
典型的神经元结构大致可分为细胞体和细胞突起。
(1)细胞体中的神经细胞膜上有各种受体和离子通道,胞膜的受体可与相应的化学物质神经递质结合,引起离子通透性及膜内外电位差发生改变,产生相应的生理活动:兴奋或抑制。
(2)细胞突起是由细胞体延伸出来的细长部分,又可分为树突和轴突。
1.5.2 人工神经网络
人工神经网络是为模拟人脑神经网络而设计的一种计算模型,它从结构、实现机理和功能上模拟人脑神经网络。人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模。
1.5.3 神经网络的发展历史
神经网络的发展大致经过五个阶段。
第一阶段:模型提出。第一个阶段为1943年~1969年,是神经网络发展的第一个高潮期。在此期间,科学家们提出了许多神经元模型和学习规则。
第二阶段:冰河期。第二阶段为1969年~1983年,是神经网络发展的第一个低谷期。在此期间,神经网络的研究处于长年停滞及低潮状态。
第三阶段:反向传播算法引起的复兴。第三阶段为1983年~1995年,是神经网络发展的第二个高潮期。这个时期中,反向传播算法重新激发了人们对神经网络的兴趣。
第四阶段:流行度降低。第四个阶段为1995~2006年,在此期间,支持向量机和其他更简单的方法在机器学习领域的流行度逐渐超过了神经网络。
第五阶段:深度学习的崛起。通过逐层预训练来学习一个深度信念网络,并将其权重作为一个多层前馈神经网络的初始化权重,再用反向传播算法进行精调。
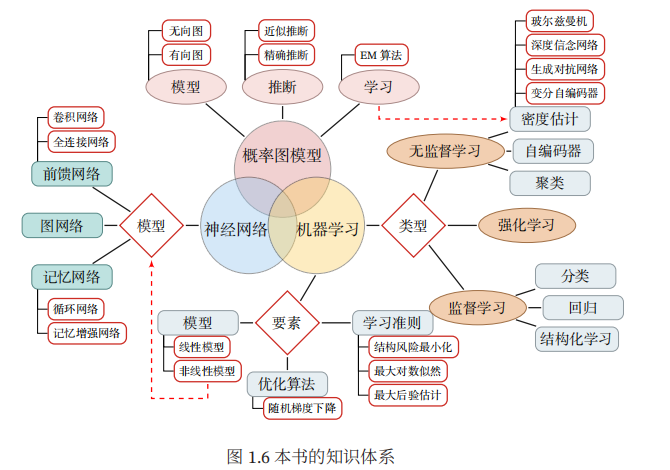
1.6 本书的知识体系
本书主要对神经网络和深度学习所涉及的知识提出一个较全面的基础性的介绍。本书的知识体系如下图所示,可以分为三大块:机器学习、神经网络和概率图模型。
1.7 常用的深度学习框架
比较有代表性的框架包括:Theano、Caffe、TensorFlow、Pytorch等。
1.8 总结和深入阅读