数据挖掘作业,要实现决策树,现记录学习过程
win10系统,Python 3.7.0
构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier:
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris() X = iris.data[:,2:] y = iris.target tree_clf = DecisionTreeClassifier(max_depth=2) tree_clf.fit(X,y)
要将决策树可视化,首先,使用export_graphviz()方法输出一个图形定义文件,命名为iris_tree.dot
这里需要安装graphviz
安装方式:
① conda install python-graphviz
② pip install graphviz
在当前目录下新建images/decision_trees目录
不然会报错
Traceback (most recent call last):
File "decisiontree.py", line 21, in <module>
filled=True)
File "E:Anacondalibsite-packagessklearn reeexport.py", line 762, in export_graphviz
out_file = open(out_file, "w", encoding="utf-8")
FileNotFoundError: [Errno 2] No such file or directory: '.\images\decision_trees\iris_tree.dot'
from sklearn.tree import export_graphviz import os PROJECT_ROOT_DIR = "." CHAPTER_ID = "decision_trees" def image_path(fig_id): return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
export_graphviz(tree_clf, out_file=image_path("iris_tree.dot"), feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True)
运行过后生成了一个dot文件

使用命令dot -Tpng iris_tree.dot -o iris_tree.png 将dot文件转换为png文件方便显示
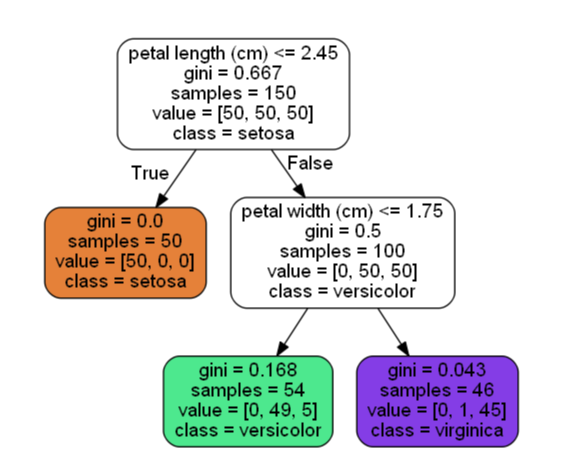
决策树如上图所示
petal length:花瓣长度 petal 花瓣宽度
samples:统计出它应用于多少个训练样本实例
value:这个节点对于每一个类别的样例有多少个  这个叶结点显示包含0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica
这个叶结点显示包含0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica
Gini:用于测量它的纯度,如果一个节点包含的所有训练样例全都是同一类别的,我们就说这个节点是纯的( Gini=0 )
Gini公式:
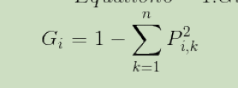 Pik是第i个节点上,类别为k的训练实例占比
Pik是第i个节点上,类别为k的训练实例占比
进行预测
当找到了一朵鸢尾花并且想对它进行分类时,从根节点开始,询问花朵的花瓣长度是否小于2.45厘米。如果是,将向下移动到根的左侧子节点,在这种情况下,它是一片叶子节点,它不会再继续问任何问题,决策树预测你的花是iris-setosa
假设你找到了另一朵花,但这次的花瓣长度是大于2.45厘米的。必须向下移动到根的右侧子节点,而这个节点不是叶节点,它会问另一个问题,花瓣宽度是否小于1.75厘米?如果是,则将这朵花分类成iris-versicolor ,不是,则分类成iris-versicolor
注意:scikit-learn使用的是CART算法,该算法仅生成二叉树;非叶节点永远只有两个子节点。
估计分类概率
新样本:花瓣长5厘米,花瓣宽1.5厘米,预测具体的类
print(tree_clf.predict_proba([[5,1.5]])) print(tree_clf.predict([[5,1.5]]))

此处说明分类为iris-setosa的概率为0,分类为iris-versicolor的概率为0.90740741,分类为iris-virginica的概率为0.09259259
通过predict预测该花为iris-versicolor
完整代码
#在鸢尾花数据集上进行一个决策树分类器的训练 from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_graphviz import os PROJECT_ROOT_DIR = "." CHAPTER_ID = "decision_trees" def image_path(fig_id): return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id) iris = load_iris() X = iris.data[:,2:] y = iris.target tree_clf = DecisionTreeClassifier(max_depth=2) tree_clf.fit(X,y) export_graphviz(tree_clf, out_file=image_path("iris_tree.dot"), feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True) print(tree_clf.predict_proba([[5,1.5]])) #[0]:iris-setosa, [1]:iris-versicolor, [2]:iris-virginica" print(tree_clf.predict([[5,1.5]]))
CART训练算法原理介绍:
