本文首发于个人微信公众号:coder小黑
服务拆分的痛
服务拆分之后,前后端同学之间关于 API 粒度的争吵越来越常见:
「前端同学请求两个接口,聚合一下数据不就行了?」后端同学想只提供业务领域基础 API 服务能力,数据组装处理则希望由前端同学完成。
「后端聚合一下,前端可以少一次请求,只负责页面渲染!」前端同学希望只负责页面渲染,而 H5、APP、小程序同一个聚合逻辑可能会出现在三端,后端聚合则只需要一次。
接口聚合服务就是我们的一个解决思路。
接口聚合服务是什么?
接口聚合服务就是一个搬运工,只是帮助前端同学聚合多个接口的返回数据,聚合之后一次性返回相应请求的结果给客户端。我们希望通过接口聚合服务这个中间层,做到可以让前端直接获取数据,而后端也能继续专心于提供基础业务领域 API 服务能力。
场景分析
- 场景一:串行获取数据。多个请求,有关联关系。
- 例如:通过商品 ID 获取评论信息,通过评论中的 uid 获取用户信息
- 场景二:并行获取数据。多个请求,无关联关系。
- 例如:通过商品 ID 获取商品信息、获取商品活动信息、获取当前用户已购信息
方案调研
| 方案 A | 方案 B | |
|---|---|---|
| 调用者 | 客户端 | 客户端 |
| API-Server | 自研 | GraphQL |
| Payload | 约定 | GraphQL |
| Response | 约定 | GraphQL |
| 容错 | 约定 | 约定 |
| 动态选取字段 | 是 | 是 |
最终我们选择了方案 A,通过自研一套简单的接口聚合中间层来解决这个问题。
于是,就有了接口聚合服务:api-aggregator。该框架有如下几个特点:
-
核心代码在千行左右,轻量级实现。
-
对现有代码无侵入性,无需对现有服务和代码做改造适配,现有接口可直接使用。
-
提供了 ApiAggregatePostProcessor 拓展点来干预接口聚合的各个阶段,可拓展性强。
-
对前端友好,前端同学可以自定义返回数据结构,支持字段动态选取。
-
接口聚合逻辑直接通过配置文件和 api-aggregator 交流,新增聚合接口,无需发布。
api-aggregator:接口聚合服务

api-aggregator 认为一个聚合接口应该是由若干个接口的返回结果聚合而成的,因此在设计时,我们将其被划分为两个部分:接口元信息和接口之间的聚合逻辑。
ApiDefinition:接口元信息
ApiDefinition 不仅定义了接口的元信息,同时也描述了接口所需参数的来源。
api-aggregator 认为在一次接口聚合中,元信息接口的参数可能有以下一些来源:
- 直接由客户端传递过来,即直接从 HttpRequest 中获取参数。
- 从上个接口的返回值中获取。例如:通过商品 ID 获取评论信息,通过评论中的 uid 获取用户信息。此时 uid 参数就需要从上个接口的返回值中获取。
ResponseDefinition:接口间聚合逻辑
ResponseDefinition 描述了接口间的聚合逻辑,通过 ResponseDefinition 前端同学可以自定义接口返回的数据结构,也可以动态选取所需字段。

如果没有 ResponseDefinition,则 api-aggregator 只能简单的将两个接口的数据平级的聚合在一起(如上左图所示)。而现在,可以通过 ResponseDefinition 来定义返回结构体,给前端同学更好的开发体验(如上右图所示)。
简单聊聊设计
配置文件预加载
接口聚合配置信息是由前端开发同学在管理后台配置的。
前端同学在提交配置文件之后,api-aggregator 就会对配置文件做一些静态分析:分析接口的依赖情况,是否存在循环依赖等问题。
为了提高性能,api-aggregator 将相关的配置信息解析好之后,会直接缓存在内存中,以减少对同一份配置文件的反复解析,同时,再通过定时刷新和 MQ 的 pub/sub 来保证数据的一致性。
简化 http 请求模型

api-aggregator 抽象了 HttpMethodInvoker 来发起 HTTP 请求。通过 Supplier 来获取返回结果,屏蔽了不同 Http Client 之间的 API 差异。
还记得前文提到的场景吗?
场景一:串行获取数据。多个请求,有关联关系。
场景二:并行获取数据。多个请求,无关联关系。
在 api-aggregator 中,将这两个场景进行了简化合一。
首先, api-aggregator 在解析配置文件分析接口依赖时,会根据接口的依赖情况给出一个 api-aggregator 认为是最优的 HTTP 请求流程,而不是根据配置文件定义的接口顺序依次请求。
举个例子:
假设在一次接口聚合中,需要请求接口 A、B、C,而接口 B 的数据依赖于接口 A,接口 A 和接口 C 的请求参数均可直接从 HttpRequest 中获取参数。
那么,在实际的接口聚合过程中,api-aggregator 会先请求接口 A 和接口 C,然后阻塞获取接口 A 的返回结果,最后请求接口 B。
提供扩展点
api-aggregator 提供了 ApiAggregatePostProcessor 来方便后续扩展。
通过 ApiAggregatePostProcessor,api-aggregator 可以干预一个接口聚合的整个流程,例如:缓存接口信息、增加监控日志等等。
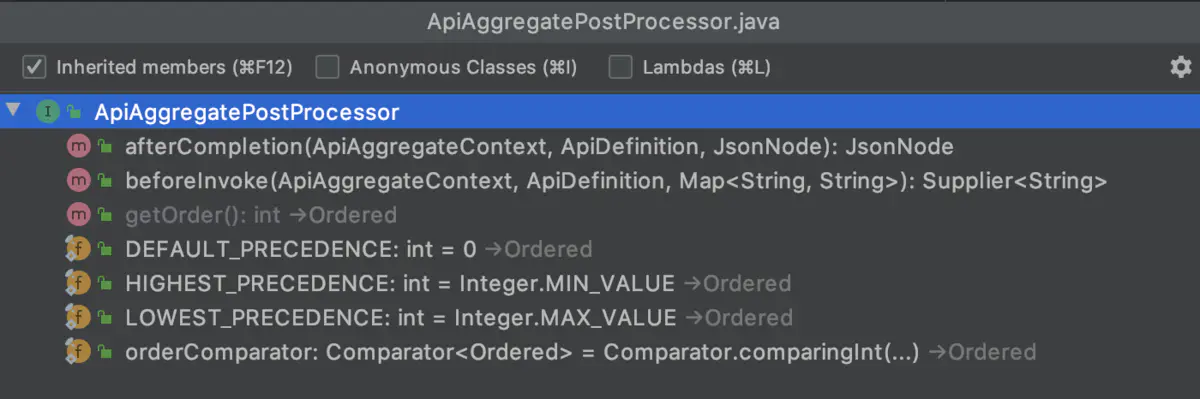
虽然通过 ApiAggregatePostProcessor 可以来干预接口的聚合流程,但是想要添加新的 Processor 时还是需要重启api-aggregator。而 api-aggregator 作为接口聚合点,和网关相似,也是流量的集中点,在后续的版本中,可能会考虑引入 Groovy 脚本,来支持动态的开启和停用 Processor。
最后,欢迎大家在评论区一起留言讨论,感谢你的阅读~~
欢迎关注个人公众号:
