6. 为领域模型Permission编码
现在我们为账户子系统(AccountSubsystem)设计领域对象并编码实现细节。
账号、角色、权限是账户子系统里已知的3个事物,而一个子系统里面可以有多个内聚模型,所以我们首先要思考的问题是:以谁为聚合根创建第一个内聚模型?
与划分子系统的思路一样,我们以最简单、最独立的事物作为突破口。简单是指事物在特定领域里的特征比较少,没有那么复杂。很明显,权限是最简单、最独立的,它不依赖于账号、角色而独立存在,而且从目前收集到的需求来看,权限的特征只需要有名称即可。所以我们尝试以权限(Permission)为聚合根创建第一个内聚模型。请各位注意,我在这里用“尝试”一词表达要做的工作,因为我们并不能保证当前做的决策100%是对的,但是勇敢的去尝试总比畏首畏尾、不敢迈出第一个步子、始终原地踏步要好的多。所以各位在实践的时候,如果有了灵感、有了大致的思路,就算思路还不够全面、不够清晰,你也可以大胆的去尝试,CA可以保证即便设计有误也能及时修正。使用CA开发项目的过程就是不断的在分析、设计、实践、修正中反复迭代的过程,最终你会提炼出与事物本质特征相符的领域模型。
在考虑将Permission作为聚合根后,我们依然要对这一决策提出质疑,要反问自己Permission是值对象还是实体对象。如果Permission是值对象,那么它就不能作为聚合根了,因为聚合根必须是实体对象。使用CA做开发,我们要善于使用这种思考技巧:先根据脑海的“嗅觉”做出设计上的判断,再反问自己各类问题以便验证或推翻这项判断。这种先做决策再试图推翻的思考方式会带给你意想不到的惊喜,如果你推翻不了它,证明所做的决策就是对的,反之就需要改进这项决策,然后再去想办法推翻新的决策,一直到你找到无法推翻的决策为止。
判断Permission是否为实体对象的依据之一就是外部事物是否需要直接找到它。这里的外部事物是指"应用层"和"领域模型层里除Permission以外的领域对象"。首先,要判断角色是否拥有某项权限,我们肯定需要建立角色和权限的引用关系,由此可以推断出,权限应该是需要被外部对象角色所直接引用的(注意,由于角色这一事物还没有开始设计,所以这里我们只是做的假设,辅助我们判断Permission的设计)。另外,权限的名称、描述等信息需要由系统的使用者去直接填写或更改,所以我们可以想象得到,应用层需要根据标识符获取Permission对象,将其读取后呈现相关信息给系统使用者查看(注意,我们这里是借助UI操作的方式来辅助我们判断Permission是否为实体对象,再次声明,领域模型的建立不仅仅是为了满足UI操作,但是正确的领域模型一定可以完全满足UI操作,因此,借助它来帮助我们分析领域对象如何设计是可以的,只是注意要适度,不要局限于某一种UI操作来设计对象。)。所以我们判定Permission是实体对象,它具有成为聚合根的基本条件。
然后我们再思考,Permission是聚合根还是内聚成员?很明显,Permission只能是聚合根,因为我们还无法从权限事物里找出第二个相关的事物,Permission只能作为聚合根存在。至此,对Permission的初步分析工作就完成了,下面贴出Permission的初期代码并作出详细说明:
1 using System; 2 3 using CodeArt.DomainDriven; 4 5 namespace AccountSubsystem 6 { 7 /// <summary> 8 /// 权限对象 9 /// </summary> 10 [ObjectRepository(typeof(IPermissionRepository))] 11 [ObjectValidator(typeof(PermissionSpecification))] 12 public class Permission : AggregateRoot<Permission, Guid> 13 { 14 internal static readonly DomainProperty NameProperty = DomainProperty.Register<string, Permission>("Name"); 15 16 /// <summary> 17 /// 权限名称 18 /// </summary> 19 [PropertyRepository()] 20 [NotEmpty()] 21 [StringLength(2, 25)] 22 public string Name 23 { 24 get 25 { 26 return GetValue<string>(NameProperty); 27 } 28 set 29 { 30 SetValue(NameProperty, value); 31 } 32 } 33 34 35 internal static readonly DomainProperty MarkedCodeProperty = DomainProperty.Register<string, Permission>("MarkedCode"); 36 37 38 /// <summary> 39 /// <para>权限的唯一标示,可以由用户设置</para> 40 /// <para>可以通过唯一标示找到权限对象</para> 41 /// <para>该属性可以为空</para> 42 /// </summary> 43 [PropertyRepository()] 44 [StringLength(0, 50)] 45 public string MarkedCode 46 { 47 get 48 { 49 return GetValue<string>(MarkedCodeProperty); 50 } 51 set 52 { 53 SetValue(MarkedCodeProperty, value); 54 } 55 } 56 57 /// <summary> 58 /// 是否定义了标识码 59 /// </summary> 60 public bool DeclareMarkedCode 61 { 62 get 63 { 64 return !string.IsNullOrEmpty(this.MarkedCode); 65 } 66 } 67 68 69 private static readonly DomainProperty DescriptionProperty = DomainProperty.Register<string, Permission>("Description"); 70 71 /// <summary> 72 /// <para>描述</para> 73 /// </summary> 74 [PropertyRepository()] 75 [StringLength(0, 200)] 76 public string Description 77 { 78 get 79 { 80 return GetValue<string>(DescriptionProperty); 81 } 82 set 83 { 84 SetValue(DescriptionProperty, value); 85 } 86 } 87 88 [ConstructorRepository()] 89 public Permission(Guid id) 90 : base(id) 91 { 92 this.OnConstructed(); 93 } 94 95 #region 空对象 96 97 private class PermissionEmpty : Permission 98 { 99 public PermissionEmpty() 100 : base(Guid.Empty) 101 { 102 this.OnConstructed(); 103 } 104 105 public override bool IsEmpty() 106 { 107 return true; 108 } 109 } 110 111 public static readonly Permission Empty = new PermissionEmpty(); 112 113 #endregion 114 } 115 }
这是我们第一个代码示例,旨在让各位熟领域对象的基本写法。所以此处并没有涉及到领域行为、对象引用关系、领域事件、移动领域对象等高级话题。
1)using CodeArt.DomainDriven; 表示引入CodeArt.DomainDriven命名空间,该命名空间提供了领域设计的技术支持。要使用该命名空间你需要在账户子系统中引用CodeArt.DomainDriven的程序集:

2)namespace AccountSubsystem 表示Permission对象处于账户子系统内。请注意子系统的命名约定:在子系统的实际名称上追加Subsystem后缀组成。例如:UserSubsystem(用户子系统)、CarSubsystem(车辆子系统)。
3)我们在Permission的类定义里标记了特性标签 [ObjectRepository(typeof(IPermissionRepository))] 指示对象是可以被仓储的,并且Permission的仓储接口是IPermissionRepository。但是请大家一定注意,我们已经决定了Permission是根对象,因此这个对象继承自AggregateRoot<Permission, Guid>(这段代码后文会有详细说明),所以就算Permission没有标记ObjectRepository特性,只要Permission继承了AggregateRoot<Permission, Guid>这个基类,就表示Permission是聚合根,那么它就是一定可以被仓储保存的。那么这个特性的意义何在?意义在于提高开发效率,缩短开发时间。只要当你对聚合根标记了ObjectRepository,那么你就可以使用CA内置的ORM工具,自动化存储Permission,你不需要写一行代码就可以实现保存Permission,甚至连表都不需要设计,CA的内置模块会帮你搞定这一切。要使用ObjectRepository特性请引用程序集CodeArt.DomainDriven.DataAccess:

CodeArt.DomainDriven.DataAccess是CodeArt 3.0提供的新组件。与使用CA 2.0版本相比,程序员的工作量降低了50%。当然,你也可以不使用CA提供的ORM特性,自行编码如何存储对象,这点后文会有介绍。但是强烈建议你使用这一特性,随着CA的发展,我们会逐步提升DataAccess的各项指标,你的项目同步更新CA新版本就可以享受我们的工作成果。
4)紧接着我们为Permission类又标记了[ObjectValidator(typeof(PermissionSpecification))]。正如其名,ObjectValidator表示对象验证器,还记得我们在前文里说过“每个领域对象都具有验证固定规则的能力”这个领域规则吗?ObjectValidator就是用于对象验证的,为对象标记这个特性并且传入参数PermissionSpecification,就表示Permission对象需要满足类型名称为PermissionSpecification的规格。在PermissionSpecification的代码里,我们会编码定义规格的细节。CA强调每个对象都应该满足1个或者多个需要满足的规格,所以你可以传入多个规格类型给ObjectValidator特性。当对象被提交给仓储的时候,这些规格会被自动验证。PermissionSpecification的代码如下:
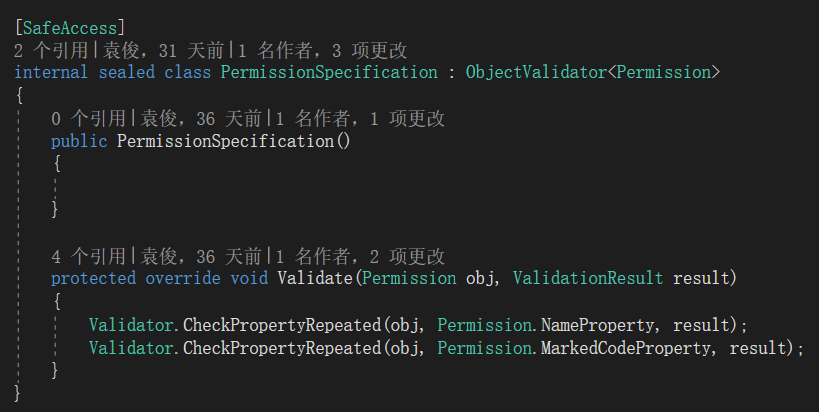
我们稍后会结合属性规则验证详细讲解PermissionSpecification里代码的含义,现在请将思路放回到Permission代码段里。
5)public class Permission : AggregateRoot<Permission, Guid>,这段代码定义了Permission类,该类继承自AggregateRoot<Permission, Guid>,这是一个泛型基类,第一个泛型参数传入Permission类型即可,第二个泛型参数表示Permission这个聚合根的标识符类型,我们在这里定义为Guid。由于聚合根也是实体对象,所以必须为聚合根指定标识符的类型。另外,使用CA做开发,聚合根都需要继承自AggregateRoot<TRoot, TIdentity>基类,它实现了多项有关聚合根的技术细节,大家不必自己去实现IAggreateRoot接口。
6)internal static readonly DomainProperty NameProperty = DomainProperty.Register<string, Permission>("Name");这句代码很关键,这是CA里注册领域属性定义的方式,从概念上讲领域属性是指能够反映事物在某一领域本质特征的属性。从代码实现上来说,与普通属性相比,领域对象要对领域属性有更强的控制性,这体现在属性什么时候被更改、属性是否为脏的(与数据仓储里的数据不一样就是脏的)、能够以不破坏原有对象的代码情况下扩展一个领域属性、重写或追加属性的GET或SET方法等。这些CA都已经做了充分的支持,你只需要按照语法编写定义领域属性的代码即可。
在说明该代码之前,大家先搞清楚“领域属性定义”和“领域属性”的区别,定义是对领域属性的特征描述,比如领域属性的名称为Name,这就是定义的一部分。我们这里的代码是说明如何定义领域属性的。至于领域属性的使用在后面的代码段中会有说明。
首先,请注意访问修饰符internal,这表示该领域属性仅程序集内部可见,你也可以根据需要设置成为public、private,我们建议你在不知道如何选择的时候就填写private,确保领域属性的定义仅对象内部可见。这里补充一个对象思想的小技巧:不论是方法还是属性使用私有定义意味着该对象不对外作出任何承诺,仅内部使用。对外承诺的越多(public修饰符)对象需要履行的义务就越多,就越复杂,复杂就容易出错。因此尽可能的使用private,只在必要的时候使用public是一个良好的编程习惯。我们为Permission设计的领域属性Name是internal而不是private是因为PermissionSpecification这个规格需要用到它(详见之前的代码贴图),所以将原本私有的访问修饰变为了程序集内部可见的。
static readonly 是必备的修饰符,表示领域属性是静态且不可改变的。定义它为静态的是因为领域属性是对事物某项特征的描述,学生的年龄就是属于学生这个事物“按年计算存在的时间”的特征,是所有的学生实例都会有的特征,而不是某个学生独有的。因此年龄的领域属性为静态的。
领域属性的定义一旦给出就不可改变,我们可以扩展它的职责但不能抹去它的存在(改变属性定义的指向也算是抹去之前属性定义的存在)。因为事物的本质特征是不会被抹去的( 比如说,一个学生的年龄今天会有,难道明天就不见了?)。当然,也有可能由于我们设计上的错误造成了一个领域属性不该存在,这时候你删除该领域属性相关的代码就可以了,所以只要是设计好了的领域属性定义就一定是静态只读的。
DomainProperty NameProperty 是领域属性定义的声明,DomainProperty是领域属性定义的类型,所有领域属性定义都应该使用这个类型。请注意领域属性定义名称NameProperty,CA规定所有的领域属性定义必须在真实的属性名后追加Porperty,也就是XXXProperty的格式表示XXX领域属性的定义,这是使用CA做开发需要遵守的原则之一。
NameProperty = DomainProperty.Register<string, Permission>("Name"); Register是DomainProperty提供的静态泛型方法,该方法的返回值是DomainProperty的实例。第一个泛型参数string,表示属性值的类型为string,第二个泛型参数Permission表示该领域属性属于类型为Permission的领域对象。参数“Name”表示属性的名称为Name。
通俗的讲,我们使用 internal static readonly DomainProperty NameProperty = DomainProperty.Register<string, Permission>("Name"); 这句代码为领域对象Permission注册了一个Name属性的定义,这个定义里说明了领域属性的名称为Name,领域属性的值类型为字符串,领域属性属于领域对象Permission。关于这方面更多细节的讨论请继续看后文。
7)下面来看代码段:
/// <summary>
/// 权限名称
/// </summary>
[PropertyRepository()]
[NotEmpty()]
[StringLength(2, 25)]
public string Name
{
get
{
return GetValue<string>(NameProperty);
}
set
{
SetValue(NameProperty, value);
}
}
仅描述事物的特征但不去运用它是没有意义的。上述代码就将领域属性定义NameProperty应用到了Permission实例上。令Permission类型一旦实例化了,就具备提供自身名称的能力。Name就是Permission的领域属性。请注意Name属性的Get和Set方法,由于我们使用了领域属性的概念,所以当你为领域对象编写领域属性代码的时候,请直接使用语法GetValue<T>(DomainProperty) 和 SetValue(DomainProperty, value) 来实现领域属性的Get和Set方法,不要在这两个方法里编写其他的代码,这也是使用CA的原则之一。GetValue的泛型参数T表示需要获取属性的值的类型,DomainProperty参数表示领域属性定义(在这里是之前编写的NameProperty)。SetValue这个方法的调用比较简单,在此不过多的说明。
我们再来讨论这项属性被标记的3个特性。请注意,这3个特性都是用来定义Name的,我们之前提到过,我们使用DomainProperty类型来表达领域属性的定义,那么为什么这里的3个特性被标记在Name上,而不是直接标记在NameProperty上呢?例如:
/// <summary>
/// 权限名称
/// </summary>
[PropertyRepository()]
[NotEmpty()]
[StringLength(2, 25)]
internal static readonly DomainProperty NameProperty = DomainProperty.Register<string, Permission>("Name");
事实上你完全可以这样做,这也是CA提供的标准写法。只是考虑到程序员们在其他框架里习惯对属性直接打特性了,所以CA才提供了兼容性的写法,即:直接在属性上标记特性以便更详细的描述领域属性的定义。在某些情况下,你只能将特性标记在领域属性定义上,比如在为对象静态扩展属性时。因为我们第一个代码示例还未涉及到这方面的话题,所以我们的代码里是按照程序员的习惯将特性写在领域属性上,而非领域属性定义上。
[PropertyRepository()]特性,与之前提到的ObjectRepository类似,该特性由CodeArt.DomainDriven.DataAccess提供,表示该属性是可以被仓储的。也就是说你为属性打上这个特性,CA的ORM模块在存储对象的时候就会考虑将该属性的值存入到仓储里。该特性不是领域模型必备特性,如果你要自己实现对象的持久化操作可以不必标记该特性,但这往往没有必要。
[NotEmpty()]该特性指示属性的值是不能为空的,请注意,之前我们讨论过Not Null的话题,在CA的领域世界里,所有领域对象以及领域属性值都不能有null值,所以就算你不写NotEmpty也表示Name属性不能有null值,但是NotEmpty表示的意思是不允许为空值,对于字符串来说""或者string.Empty表示的就是空值。因此这里的意思是字符串属性Name不允许是空的,必须有至少1个或1个以上的字符。
[StringLength(2, 25)]这个特性大家肯定都能理解,表示字符串的最小长度和最大长度。
这里的NotEmpty和StringLength特性,都是之前提到的固定规则的一种体现,在CA里,你可以为对象标记ObjectValidator特性并为这个特性传入多项规格标准(实现IObjectValidator的接口就可以成为规格标准)来验证对象级别的合法性,也可以对领域属性直接以标记特性的方式定义属性需要满足的规则。为属性打特性实现属性验证这点并不是CA特有的方式,许多其他框架也有类似的机制,因此不再过多说明。
8)以上介绍了领域属性的相关话题,现在我们回头看看之前提到的对象规格的代码实现:
[SafeAccess]
internal sealed class PermissionSpecification : ObjectValidator<Permission>
{
public PermissionSpecification()
{
}
protected override void Validate(Permission obj, ValidationResult result)
{
Validator.CheckPropertyRepeated(obj, Permission.NameProperty, result);
Validator.CheckPropertyRepeated(obj, Permission.MarkedCodeProperty, result);
}
}
[SafeAccess]由命名空间CodeArt.Concurrent提供并位于CodeArt程序集内。该特性指示对象是并发访问安全的,也就是多线程访问安全的。任何类型只要标记这个特性,当CA内部在构造该类型的实例时,就会缓存实例。当需要下次创建时直接返回该实例,因为对象是并发访问安全的,只需要一个实例即可。因此,当你设计的类型是并发访问安全的同时你也希望它以单例的形式出现,那么就可以为类型标记该特性。这里的PermissionSpecification对象没有任何属性成员,内部的方法实现也与状态无关,因此可以作为单例的形式出现,所以标记了该特性。该特性可以提高应用程序性能,重复使用同一个对象。
PermissionSpecification继承了泛型基类ObjectValidator<Permission>,这是对象验证器的基础类,继承这个对象可以节省大家处理其他细节的时间。泛型参数里记得填写聚合根的类型,也就是Permission。
protected override void Validate(Permission obj, ValidationResult result) 是派生类必须重写的方法,你要在这里面编写验证逻辑。 ValidationResult表示的是验证结果的对象,你可以使用这个对象追加错误信息。在本示例里只是简单的将该参数传递给了Validator使用。
由于我们经常会遇到某个属性不能重复出现的需求(比如用户名不能重复等),因此CA提供的Validator工具对象里定义了CheckPropertyRepeated方法,用于检查属性的值是否重复。Validator.CheckPropertyRepeated(obj, Permission.NameProperty, result);就是检查对象obj的Name属性的值是否已经在别的对象里出现了,如果出现了,result参数里就会增加一条错误,该错误最终会由CA框架处理,抛出错误异常。用该方法判定属性重复规则很方便,请注意Validator的定义在CodeArt.DomainDriven.DataAccess程序集中,也就是说,这个工具类是由基础设施层提供的,不是领域模型层的内容,因为判定属性值是否重复需要由仓储的实现支持,技术上的原因导致该工具类只能出现在基础设施层。另外,我们可以定义更加复杂的固定规则,比如一个班的学生人数不能超过50人等。在后续的示例里我们再演示更加复杂的情况。
说明了CA里如何验证对象固定规则的代码后,我们回过头来谈谈这方面的思想问题。大家也许认为我们这里的领域属性以及属性验证和传统开发模式里的表设计是一回事,比如在表permission里有个名称为name的字段,这个字段要有唯一性约束,并且长度是50以内。不可否认,从这个角度来看,领域对象和数据库表设计确实有点相似之处,但是两者完全不是同一个概念。
我们之所以用领域驱动设计就是为了探寻事物在特定领域里的本质特征,为了实现这一目标,我们会基于领域的思想去考虑问题,思考的结果之一就是探寻到了事物固有的规则,这个固定规则就是描述事物本质特征的一个方面。但是数据库字段设计是基于表的设计,设计的表有可能是某个业务需要的表,也有可能是中间表,甚至临时表,它们被设计的目的就是为了方便存储数据或者为某个业务处理做数据上的支持。请注意,数据库里的表为某个业务的实现做数据上的支持,不代表数据表自身处理了业务,事实上,开发人员还需要编写大量操作数据库的代码来实现业务逻辑。与之相反的是,领域对象天生就具备处理复杂业务的能力,它不是数据的提供者而是业务的处理者,这是两者最为本质的区别。
我们从业务的角度分析对象,摸索出事物的本质,然后为其制定固定规则。这和表设计是两种不同思考问题的方式。虽然有可能两种实施方式下偶尔得到了相同的结果(这里指的结果仅仅是存储结果,因为领域对象最终也是要被加入到仓储的,用数据库做仓储的实现还是需要为该领域对象设计表,那么我们设计好的对象在映射表的时候,有可能对象表的设计会与传统开发设计出来的表相同),但这不代表对象设计和表设计是同样一件事,事实上大部分情况下两者设计的结果是截然不同的。所以,领域对象的设计和数据库表的设计不能混为一谈,用数据库持久化领域对象确实需要设计表,但是表的字段、约束等规则都是依赖于领域对象的设计,先有领域对象才会有数据库里的表,就算你不用数据库存储领域对象,领域对象依然存在,它依然可以处理业务!
9)再来看看关于MarkedCode的代码段:
internal static readonly DomainProperty MarkedCodeProperty = DomainProperty.Register<string, Permission>("MarkedCode");
/// <summary>
/// <para>权限的唯一标示,可以由用户设置</para>
/// <para>可以通过唯一标示找到权限对象</para>
/// <para>该属性可以为空</para>
/// </summary>
[PropertyRepository()]
[StringLength(0, 50)]
public string MarkedCode
{
get
{
return GetValue<string>(MarkedCodeProperty);
}
set
{
SetValue(MarkedCodeProperty, value);
}
}
/// <summary>
/// 是否定义了标识码
/// </summary>
public bool DeclareMarkedCode
{
get
{
return !string.IsNullOrEmpty(this.MarkedCode);
}
}
与Name属性类似,同样的语法定义了MarkedCode(标记码)属性。在第一次编码Permission对象的时候并没有这个属性,随着项目的推进我们发现有必要为Permisson对象追加标记码机制。
大家试想一下,系统既然有权限机制,那么必然会有验证的需要,比如在员工列表的页面(我们就以表现层是B/S站点为例说明)有个Page_Load方法,该方法里也许会验证当前登录人是否有查看该员工信息的权限。假设验证权限的示意代码是 ValidatePermission(“查看员工信息”)。ValidatePermission是验证权限的方法,该方法是表现层定义的,与领域模型层无关,这个方法会将当前登录人的编号和权限的名称提交到门户服务,由门户服务判断结果。大家不要在意实现的细节,门户服务处理请求的机制后续教程中会讲解。在这里各位请考虑一个问题,我们将权限的名称以硬编码的形式提交给门户服务,门户服务需要通过权限名称找到权限对象,然后调用权限对象的领域方法判断登录人是否合法,那么问题就来了,如果哪一天由于一些原因,我们需要在系统后台更改这个权限的名称怎么办?我们把权限名称“查看员工信息”修改为“查看多个员工信息”,这时候我们不得不找到员工列表页,手工改代码修改名称,然后编译代码,重新上传到服务器。可以想象得到,当权限数量多了这种维护非常麻烦。
那么我们在ValidatePermission方法里传递权限的编号呢?要知道编号是不会被改变的。但是使用编号有两个问题,1.编号是GUID(你也可以设置为整型),这种数字化的值不够直观:ValidatePermission(125),你能看出该方法是验证什么权限吗?2.如果我们把查看员工信息的权限误删除了,然后我们又重新创建该权限,那么“查看员工信息”的权限编号就变了,我们依然要在页面里改验证代码。
引起该问题的本质原因是什么呢?是因为在站点里有权限上的需要,这是站点在开发期间固化的硬性需要,是硬编码实现的,比如: ValidatePermission(“查看员工信息”)就是硬编码实现验证登录人是否有“查看员工信息”的权限。而我们设计的权限机制是一个通用型的,是为了在多个站点里都可以重用权限验证的机制。因此,我们提供门户服务的后台入口,由系统管理员可以设置每个站点自己的权限信息,并提交给门户服务保存,比如:A站点是一个OA系统,所以我们为A站点创建了“查看员工信息”和“创建员工信息”这两个权限。请记住,门户服务本身是个独立站点,你在A站点提交权限信息给门户服务,门户服务就为A站点保存了这两项权限的信息。权限的数据是放在门户服务的仓储里,不是在A站点里。另外,B站点是一个资讯项目,所以我们又在门户服务里为B站点保存了“文章管理”的权限。那么,你可以在A站点和B站点里,调用门户服务提供的验证权限的API,来判断当前登录人是否有指定的权限。这样我们多个项目都可以共用门户服务,我们不必在新项目里为权限机制重复付出劳动力。
所以,问题出现在站点对权限的要求是硬性的、是硬编码的,而权限对象的定义是保存在远程门户服务的仓储里的,一个是硬编码,一个是仓储里的对象,他们两者没有映射关系。因此我们就设计了“标记码”来体现这种映射关系。你可以为每个权限对象设置一个MarkedCode的属性值,这个值同时也是站点硬性编码的值,将该值提交给门户服务,门户服务就可以通过该值找到唯一一个对应的权限对象。这就是我们为什么要设计MarkedCode属性的原因。有了这项机制后,站点里可以调用类似这样的代码:ValidatePermission(“ViewEmployeeInfo”)来表示需要验证当前登录者是否具备查看员工信息的权限,而我们在创建名称为“查看员工信息”的权限的时候,可以指定MarkedCode为“ViewEmployeeInfo”,这样映射关系就建立好了,由于标记码是我们硬编码的需要而创建的,所以它不会像权限名称那样有可能会改变,可以放心使用。这种以标识码的方式将系统的硬编码和对应的领域对象一一映射的机制也可以用于其他需求,不必局限于权限模块。
除了MarkedCode的定义外,代码段里还编写了DeclareMarkedCode属性,严格的讲,DeclareMarkedCode应该是一个领域方法,应该是这样的格式:
public bool DeclareMarkedCode()
{
return !string.IsNullOrEmpty(this.MarkedCode);
}
只不过.NET提供了属性的写法,DeclareMarkedCode不需要任何参数,内部实现也很简单,所以我们就将其定义成了属性的写法,这样调用起来比较方便、直观,例如:
if(permission.DeclareMarkedCode)
{
//该权限定义了标识码
}
else
{
//该权限没有定义标识码
}
之所以在Permission里定义DeclareMarkedCode是因为我们认为不是所有的需求都是直接使用权限来限定用户访问的,有时候仅判断用户是否属于某个角色即可认证访问安全。所以我们不必为每个Permission都填写标识码,只需要为站点里需要用到的权限填写标识码。这也是为什么MarkedCode属性没有标记[NotEmpty()]的原因,它可以是空的。为了在领域对象Permission里突出“标识码不是必须的”这一点特征,我们额外编写了DeclareMarkedCode属性,以便在需要的时候可以直接判断。事实上,在往后的日子里,该属性几乎没有被用到过,写这段代码是我们随手而为之,你可以认为这是一种过度设计,但是这无伤大雅,因为实现DeclareMarkedCode属性的成本很低。当然,建议大家在实施项目时仅在有必要的时候才为领域对象编写额外的属性或方法,不要过度设计,这个话题后文会有详述。
10)Description属性表示权限的描述,系统管理员在设置权限的时候可以填写简短的描述以便查阅使用,该领域属性非常简单不做过多的说明。
11)再来看看Permission的构造函数的代码:
[ConstructorRepository()] public Permission(Guid id) : base(id) { this.OnConstructed(); }
[ConstructorRepository()]特性由CodeArt.DomainDriven.DataAccess提供,属于CA框架里ORM的定义。该特性表示领域对象被仓储创建时调用的构造函数是Permission(Guid id)的版本。由于Permission比较简单,所以它的构造函数只有一个。有时候我们会为领域对象编写多个构造函数,这时候标示出仓储使用哪个构造函数就很重要了。同样的,如果你不使用CA提供的ORM那么可以不标记该特性。
this.OnConstructed();代码很关键,表示构造对象的工作已全部完成。使用CA编写领域对象,当对象构造函数工作完毕的时候,必须调用 OnConstructed 方法,这是各位需要遵守的使用原则。之所以有这项原则是因为目前还没有技术平台(.NET、JAVA等)提供了对象被构造完成的事件给程序员使用。而CA需要监视各种领域事件,这包括领域对象被构造完成的事件,这些事件会对领域设计带来很大的好处(后续教程会详述)。因此需要大家手动调用OnConstructed方法给予框架提示对象构造已完成。在CA后续的版本里我们会考虑追加动态编译的机制来实现自动化处理,但在当前版本中请大家遵守这个使用约定。
12)最后我们看看关于Permission的空定义:
#region 空对象 private class PermissionEmpty : Permission { public PermissionEmpty() : base(Guid.Empty) { this.OnConstructed(); } public override bool IsEmpty() { return true; } } public static readonly Permission Empty = new PermissionEmpty(); #endregion
CA规定每一个领域对象都应该有一个空对象定义,并且以名称为Empty的静态成员公布出来。也就是说,我们可以使用领域对象.Empty的形式使用这个领域对象的空对象,Permission.Empty就代表Permission的空对象。上述代码是编写空对象的固定模式,大家请遵循该模式编写空对象,说明如下:
private class PermissionEmpty : Permission 请注意访问修饰符是私有的private,表示我们对外不直接公开PermissionEmpty,要使用空对象必须以Permission.Empty的语法。这可以保证空对象是全局唯一的,不会有多个实例,提升系统性能。由于空的权限对象还是权限对象,所以PermissionEmpty继承自Permission。另外,空对象类型的命名我们约定为领域对象名称追加Empty后缀。
构造函数代码不必多说,大家只要注意一点,空对象也是领域对象,因此也要遵守约定调用 OnConstructed 方法以便提示框架对象已构造完毕。
IsEmpty方法是DomainObject的提供的基类方法。所有的领域空对象定义里都要重写IsEmpty方法,并且返回true作为结果。
public static readonly Permission Empty = new PermissionEmpty(); 请注意访问修饰符public代表外界可以使用Permisson.Empty属性,另外,请注意Empty成员的类型为Permission而实例为PermissionEmpty,这样对于外界代码而言既隐藏了PermissionEmpty的定义又公布出了Permission的Empty成员。
关于空对象最后一个注意事项是“请将空对象的定义放在所有的领域属性的定义之后或者直接放在领域对象代码的底部”,有这项约定不是因为设计上的问题而是在代码实现上,如果不将空对象放在领域属性的定义之后,有可能引起一个技术问题,由于这个技术问题隐藏得比较深,所以在这里不过多说明,当大家完全了解了CA的工作方法后,我再来剖析框架的实现细节,那时候再解答引起问题的原因。在这里各位只用记住需要遵守这个约定就可以了。
讲解完空对象的编码说明,相信大家应该有一个疑惑,那就是“我们究竟为什么要实现空对象?”。虽然前面的教程里讲过空对象的思想,不过具体它对我们编写程序有什么实质上的帮助各位应该还不清楚。
要回答这个问题,首先请回想一下,在传统开发里我们经常会遇到删除某条数据要级联删除相关的数据,而删除相关的数据又要级联删除相关数据的相关数据。读取数据也一样,我们常常inner join多个表,有的项目中一行sql代码甚至会连接10个以上的数据表。连接这么多的表就表明着表与表之间有耦合关系,一旦其中一个表发生变化,需要维护的地方就会很多,这往往令程序员焦头烂额。然而,这些与空对象有什么关系呢?
在CA里是用一个整体策略来避免这类问题,空对象是这个策略的一个环节。首先,我们获取对象只能通过仓储查询聚合根。在仓储内部执行查询的时候,聚合根的成员也会被随之加载(除非你设置了延迟加载,这个话题后续章节里有详细说明),也就是说,当我们加载聚合根的时候,仓储会以聚合根对应的数据表为from表,inner join 内聚成员表, 然后根据查询的数据结果构造聚合根对象和内聚成员对象,并且填充它们的属性值。(这是一种简化的说明,实际上CA提供的ORM的内部机制比较复杂,加载对象的时候会进行缓存、并发控制、对象继承和扩展的识别等工作)。由于聚合根的成员类型数量会很少,这里我们没有用“一般很少”来形容,因为无论需求多么复杂,我们始终可以保证聚合根的成员类型数量几乎不超过3个。也就是说,在仓储内部inner join 的表不会超过3个,大多数情况下仅0-2个。
那为什么CA可以保证聚合根的成员数量很少呢?因为无论业务多么复杂,我们都可以将复杂的业务拆分成多个内聚模型,每个内聚模型仅负责1个关注点,这样一个内聚模型里的聚合根和内聚成员的总数会非常少。每个聚合根会提供领域方法以便应用层调用。有时候也会出现两个聚合根共同完成某项任务的情况,但是这种“共同完成”指的是聚合根A调用聚合根B的方法,B的方法在B内部定义,聚合根A不会深入到以聚合根B内部去告诉B它应该怎么样实现方法。也就是说多个聚合根就算在一起工作,但是它们的职责依然是分离的,各自履行各自的承诺,只是在一起协助完成任务而已。
但是有一种情况比较特殊,那就是有可能内聚模型a内部引用了内聚模型b里的聚合根B。比如说:文章(Article)对象是一个聚合根,文章分类(ArticleCategory)也是一个聚合根,大家不必纠结于为什么这样设计,文章系统的设计后面会有案例剖析,目前我们就认为已经设计成这样子了。示意代码如下:
public class Article:AggreateRoot<Article,int> { 其他成员的定义..... Public ArticleCategory Category{ get ; set;} 其他成员的定义...... } public class ArticleCategory:AggreateRoot<ArticleCategory,int> { 会有多个成员的定义..... }
其中Article有项领域属性叫Category(文章所属的分类),类型为ArticleCategory。也就是说以Article为聚合根的内聚模型有个名称为Category的成员类型为另外一个内聚模型的聚合根ArticleCategory。假设ArticleCategory模型里也有自己的成员,比如自定义文章模板(也就是说,发布在这个分类下的文章必须遵守的内容模板)等。那么如果我们加载聚合根Article,当仓储查询数据的时候是不是要查询成员Category,因此要inner jion 文章分类的表,由于文章分类的也有成员,那么还要inner join 文章分类的成员对应的表,导致最终以文章为聚合根的查询 inner join 的表数量也会很多,超过10个左右呢?
不会。因为Category是文章内聚模型以外的外部聚合根,这种外部聚合根默认情况下是不需要加载的,只有当你需要的时候才会再次加载。也就是说,当你第一次加载Article对象的时候,Category属性根本就没有被读取而是当你使用类似的语法article.Category访问分类属性的时候,CA才会调用仓储加载聚合根ArticleCategory对象。也许你会问这样会不会造成性能问题?在传统开发里我们可以使用一句sql加载出文章和文章分类的信息:
select * from article inner join articleCategory on article.categoryId = articleCategory.Id;
执行该sql就可以一次性查出文章和文章所属分类的信息,而在刚才的例子里,如果我们先加载了Article对象,然后代码执行在某个地方时使用了Category属性,导致再次加载分类信息,进行了二次查询,这样性能会不会比直接执行sql差呢?
不会,性能问题是个综合性话题,并不是一次性查的数据越多性能就越高。事实上,数据库IO读取是以页为最小单位的,每个页8K(这里以SQL Server 2005为例,其他数据库大同小异)。也就是说,只要你执行查询操作,就算你查询的数据只有1个字节,数据库依然会读取一个8K的数据页(数据库最小读取页为8K,实际工作时常常也以64K为单位查询),那么你想想,如果我们读取的数据体积越小,我们可以加载的数据是不是越多?这也是为什么数据库设计里有个重要的原则,设计字段类型的时候占用字节数越小越好。因为字段类型占用字节数越小,每行数据占的体积就越少,那么数据库IO一次每页可以容纳的数据行数就越多:1行数据体积是1K,8K就可以加载8行数据,但是1行数据如果是500字节,那么8K就可以加载16行数据,所以数据类型占用的字节数小,我们一次IO读取的有效数据就越多,这样就减少了IO读取的次数,提升了系统性能。
因此,当我们查询多个文章对象的时候,由于只用加载文章内聚模型内部的数据所以性能比查询完整的文章信息(包括分类信息在内的完整引用链)要好的多。另外,就算我们在查询完文章对象后,又要使用它的分类属性,由于有对象缓存的原因,分类属性的值来自于缓存区而不是直接读取数据库,因此,我们并不能武断的认为一次性执行sql查询所有的内容就比二次访问的性能要高,性能的优化要根据环境上下文综合性的判定,找出性能的瓶颈再去优化。
那么,以上说的这一切和空对象有什么关系呢?大家试想一下,如果我们删除了文章分类,该如何处理分类下的文章?传统模式下,这种情况需要级联删除,顶多在删除操作之前UI会给个友好的提示“删除该分类会删除分类下的文章,您确定删除吗?”,因为如果你不删除分类下的文章,那么当你inner join 分类表的时候,由于没有分类数据的存在,文章查询不到了,文章成了系统里不可见的“脏”数据(是的,你可以用left join来处理这种情况,但是left join又会带来查询结果中分类信息为 null的麻烦,你又得处理这种情况,另外,很多情况下不是你想用left join就可以用的,涉及到的问题很多,这也是为什么基于数据表处理业务很容易混乱的原因之一)。
那么在CA里呢?在CA里有两种处理办法,我们目前只讨论最常见的第一种:删除外部内聚根不会影响内聚模型的聚合根极其成员!也就是说,一篇文章所属的分类对象被删除了,默认情况下该分类下的文章是不会删除的,你依然可以在文章列表里查询到已被删除分类的文章信息(因为我们查询文章列表并不需要inner join文章分类,所以丝毫不影响查询结果)。那么,这时候Article对象的Category属性值是什么呢?就是ArticleCategory.Empty啊,也就是空的文章分类对象!前文说过,空的对象也是有职责的,因此你使用代码:article.Category.Name的时候结果是空字符串,并不会报错,空的文章分类的职责之一就是提供分类名称的特征,就算是空字符串也是一种特殊的分类名称。那么在表现层,文章列表分类那一列里,没有分类的文章显示的分类名称就是空的字符串。你也可以使用 article.Category.IsEmpty() 判断类型是否为空,以便输出“文章未分类”的字样提供给UI显示。在这种模式下,你甚至可以新建分类对象,然后将未分类的文章再次分配新分类。
我们从UI和数据库的角度分析了空对象起到的作用。现在我们透过现象看本质,从设计思想上对空对象的价值进行总结:在领域模型层,我们通过内聚模型分离关注点,每个关注点的内聚性极强,每个内聚模型只用关心内部的处理细节,不必关心外部模型是如何实现的。但是一个关注点的内部往往又会使用另外一个关注点帮助自己完成某项任务,这也就是为什么内聚模型内部有可能会引用外部聚合根的原因。上述示例里, 文章的聚合根(Article)就使用了文章分类的聚合根(ArticleCategory)来帮助文章处理有关“文章所属分类”的关注点,这令文章模型不必处理分类事物的实现细节,将分类这个关注点全部委托给文章分类处理,这也使得日后当文章分类需要追加新的特性或者修复BUG或者变化需求都不会影响到文章的实现,程序员不必因为修改某个内聚模型而担心牵扯到另外的内聚模型,极大提高了系统的灵活性和稳健性。当一个文章对象的实例引用的文章分类被删除了,该文章对象依然可以正常工作,造成这种良好现象的根本原因是文章使用了某个分类实例来满足它对分类的需要,该分类实例遵守了一项约定,这项约定的内容就是ArticleCategory类型定义体现出来的,例如分类名称Name就是约定之一,表示分类可以提供名称这项特征。那么当该分类实例被删除了,文章实例引用的分类就会被自动切换到空分类这个实例上,该分类实例同样遵守了ArticleCategory类型约定,因为空的文章分类也是继承于ArticleCategory类型的,所以空的文章分类替代了已被删除的文章分类,继续履行分类的职责,这令系统非常健壮,不会因为缺少了谁而崩溃!这跟使用接口的原理是一样的,我们可以随时为某个内聚模型里引用的外部聚合根切换实例,这就相当于为接口切换了实现一样,只要遵循了接口约定,系统一样可以稳定的运行!
所以,大家不要小看这个看似简单却隐含深意的空对象,它是实现CA整体策略的一个重要环节,对分离关注点、切断对象依赖性上有很大的帮助。降低对象之间依赖关系涉及到的话题比较多,目前我们只讨论到这里,但是各位要明白,CA提供的不仅仅是一个框架而是一个实施项目的整体策略,背后暗藏着一系列解决各类问题的思想理论。当你遇到系统设计上的问题时,这些理论像军师一样辅助你更好的做决策。所以在我的教程里会用大量的篇幅讨论思想方面的话题。附带说一句,CA 3.0还实现了对象快照机制,提供了可以保存被删除对象的快照功能,你可以在系统中依然使用被删除了的对象,但是可以提示类似这样的信息:“该房源已被删除,您看到的是快照信息”,快照特性不仅仅用于UI显示,在领域模型层也有很大的作用,后文再详细介绍。
最后再次提醒各位,虽然在解释空对象的作用时我们将领域对象和数据表的实现作了大量的对比,但是领域对象和数据表依然不是同一个概念,他们有本质上的不同。领域有对象是具有职责的。由于Permission对象很简单,所以很方便我们作为第一个代码示例做说明,但是Permission并不能体现出职责的更多特点,这令它看起来有点类似“表类”这样的贫血模型,但是在后面的教程里我们会建立更多的领域对象并演示出领域对象之间如何协同工作的,这样大家的认识会更加深刻。
第一个领域模型的代码讲解工作就到此结束了。大家有没有对CA提供的开发方式很感兴趣呢?有没有想赶紧使用CA开发项目的冲动?先别急,在下一章节里我们会详细讲述如何使用Permission对象完成应用命令调用、如何构建Permission的仓储以及如何配置CA的服务站点。学习完这些,你就可以初步尝试使用CA实践开发工作了。