资源下载:https://files.cnblogs.com/codealone/ConsoleApplication2.zip
Json查看工具:https://files.cnblogs.com/codealone/JsonView.zip
博客园随笔备份之后,得到的文件格式如下:
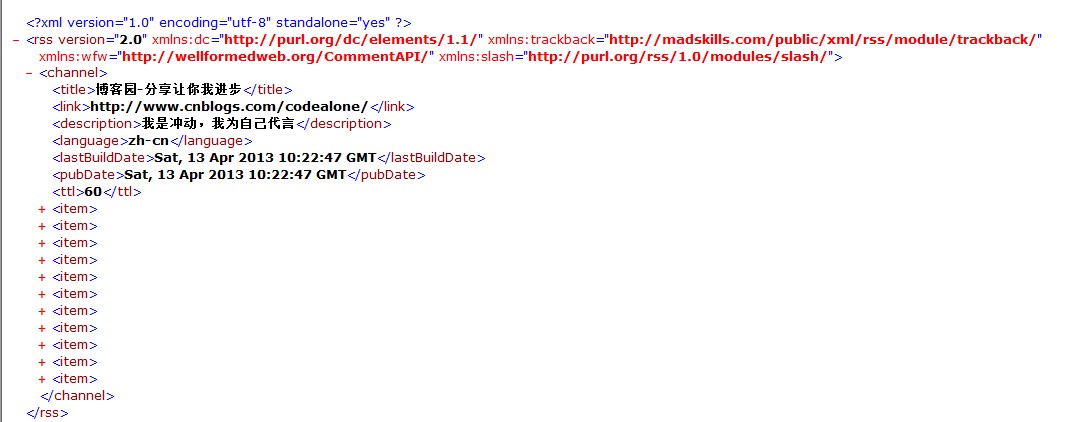
我们要读取上述xml,主要是获得channel节点下的所有内容,在平时的工作过程中,觉得json数据要比xml更加容易操作些,于是想,能不能将其转换成json格式,进一步转换成对象。下一步的工作则是将 rss节点下的内容,转换为json。
主要代码如下:
var xml = File.ReadAllText(@"D:\cnblogs.xml");//该xml为博客园随笔备份文件 XmlDocument doc = new XmlDocument(); doc.LoadXml(xml); //获取rss节点下的内容 var channelXml = doc.SelectSingleNode("rss").InnerXml; //进一步细化xml格式,内容仅为rss节点下的内容 doc.LoadXml(channelXml); //将xml序列化成json,并且去掉根节点 var json = JsonConvert.SerializeXmlNode(doc,Newtonsoft.Json.Formatting.None,true);
此时json的内容如下:

此时由xml到json的转换就完成了,下一步,则是如何将json转换成对象。通过查看上述json的结构,将每个节点看作一个对象,很容易定义出数据结构,具体如下:
public class Channel { public string title { get; set; } public string link { get; set; } public string description { get; set; } public string language { get; set; } public string lastBuildDate{ get; set; } public string pubDate { get; set; } public string ttl { get; set; } public List<Channel_Item> item { get; set; } } public class Channel_Item { public string title { get; set; } public string link { get; set; } public string author { get; set; } public string pubDate { get; set; } public string guid { get; set; } public Item_Description description { get; set; } } public class Item_Description { //默认以变量名称作为json序列化的节点,由于该节点内容不符合变量定义规范,则显示指定即可 [JsonProperty("#cdata-section")] public string content { get; set; } }
最后一步,则是将刚刚得到的json序列化成我们定义的数据结构:
var channel = JsonConvert.DeserializeObject<Channel>(json);
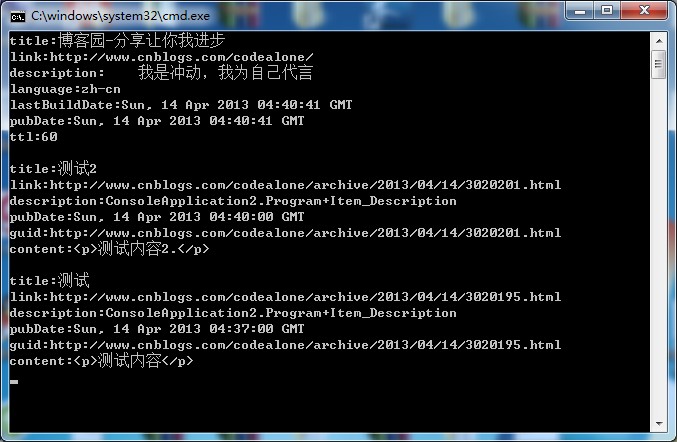
到此为止,我们将xml转换成对象的工作就完成了,打印读取的内容:
问题:
在实际的测试过程中,发现如果备份文件中,仅有一个item节点的时候,序列化后的json item部分如下:
{ "item": { "title": "测试", "link": "http://www.cnblogs.com/codealone/archive/2013/04/14/3020195.html", "author": "冲动", "pubDate": "Sun, 14 Apr 2013 04:37:00 GMT", "guid": "http://www.cnblogs.com/codealone/archive/2013/04/14/3020195.html" } }
此时是不可以直接序列化成List<Channel_Item>对象,针对此情况,不想更多的去改变代码,在item仅有一个的时候,手动添加一个空节点,此时对应的json为:
"item": [ { "title": "测试", "link": "http://www.cnblogs.com/codealone/archive/2013/04/14/3020195.html", "dc:creator": { "@xmlns:dc": "http://purl.org/dc/elements/1.1/", "#text": "冲动" }, "author": "冲动", "pubDate": "Sun, 14 Apr 2013 04:37:00 GMT", "guid": "http://www.cnblogs.com/codealone/archive/2013/04/14/3020195.html", "description": { "#cdata-section": "<p>测试内容</p>" } }, null ]
上述json格式就可以轻松的序列化成List<Channel_Item>对象了。