为什么需要hystrix
- Hystrix同样是netfix公司在分布式系统中的贡献。同样的也进入的不维护阶段。不维护不代表被淘汰。只能说明推陈出新技术在不断迭代。曾今的辉煌曾经的设计还是值得我们去学习的。
- 在分布式环境中,服务调度是特色也是头疼的一块。在服务治理章节我们介绍了服务治理的功能。前一课我们也介绍了ribbon、feign进行服务调用。现在自然的到了服务监控管理了。hystrix就是对服务进行隔离保护。以实现服务不会出现连带故障。导致整个系统不可用
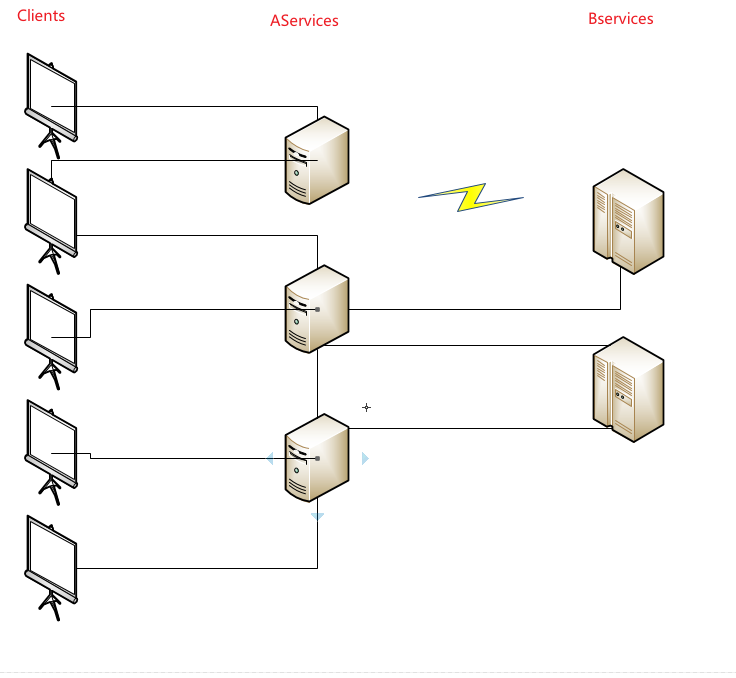
- 如上图所示,当多个客户端进行服务调用Aservice时,而在分布式系统中Aservice存在三台服务,其中Aservice某些逻辑需要Bservice处理。Bservice在分布式系统中部署了两台服务。这个时候因为网络问题导致Aservice中有一台和Bservice的通信异常。如果Bservice是做日志处理的。在整个系统看来日志丢了和系统宕机比起来应该无所谓了。但是这个时候因为网络通信问题导致Aservice整个服务不可用了。有点得不尝试。

- 在看上图 。 A–>B–>C–>D 。此时D服务宕机了。C因为D宕机出现处理异常。但是C的线程却还在为B响应。这样随着并发请求进来时,C服务线程池出现爆满导致CPU上涨。在这个时候C服务的其他业务也会受到CPU上涨的影响导致响应变慢。
特色功能
Hystrix是一个低延迟和容错的第三方组件库。旨在隔离远程系统、服务和第三方库的访问点。官网上已经停止维护并推荐使用resilience4j。但是国内的话我们有springcloud alibaba。
Hystrix 通过隔离服务之间的访问来实现分布式系统中延迟及容错机制来解决服务雪崩场景并且基于hystrix可以提供备选方案(fallback)。
- 对网络延迟及故障进行容错
- 阻断分布式系统雪崩
- 快速失败并平缓恢复
- 服务降级
- 实时监控、警报
99.9 9 30 = 99.7 % u p t i m e 0.3 % o f 1 b i l l i o n r e q u e s t s = 3 , 000 , 000 f a i l u r e s 2 + h o u r s d o w n t i m e / m o n t h e v e n i f a l l d e p e n d e n c i e s h a v e e x c e l l e n t u p t i m e . 99.99^{30} = 99.7\% quad uptime \ 0.3\% quad of quad 1 quad billion quad requests quad = quad 3,000,000 quad failures \ 2+ quad hours quad downtime/month quad even quad if quad all quad dependencies quad have quad excellent quad uptime. 99.9930=99.7%uptime0.3%of1billionrequests=3,000,000failures2+hoursdowntime/monthevenifalldependencieshaveexcellentuptime.
- 上面试官网给出的一个统计。在30台服务中每台出现异常的概览是0.01%。一亿个请求就会有300000失败。这样换算下每个月至少有2小时停机。这对于互联网系统来说是致命的。

- 上图是官网给出的两种情况。和我们上章节的类似。都是介绍服务雪崩的场景。
项目准备
- 在openfeign专题中我们就探讨了基于feign实现的服务熔断当时说了内部就是基于hystrix。当时我们也看了pom内部的结构在eureka中内置ribbon的同时也内置了hystrix模块。
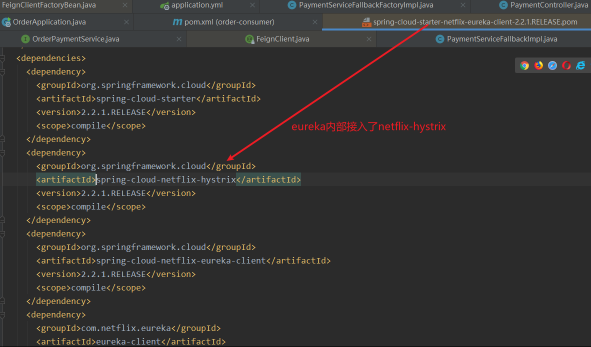
- 虽然包里面包含了hystrix 。我们还是引入对应的start开启相关配置吧。这里其实就是在openfeign专题中的列子。在那个专题我们提供了PaymentServiceFallbackImpl、PaymentServiceFallbackFactoryImpl两个类作为备选方案。不过当时我们只需指出openfeign支持设置两种方式的备选方案。今天我们
<!--hystrix--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
演示下传统企业没有备选方案的情况会发生什么灾难。


接口测试
- 首先我们对payment#createByOrder接口进行测试。查看下响应情况

- 在测试payment#getTimeout/id方法。

* 现在我们用jemeter来压测payment#getTimeOut/id这个接口。一位需要4S等待会照成资源消耗殆尽问题。这个时候我们的payment#createByOrder也会被阻塞。
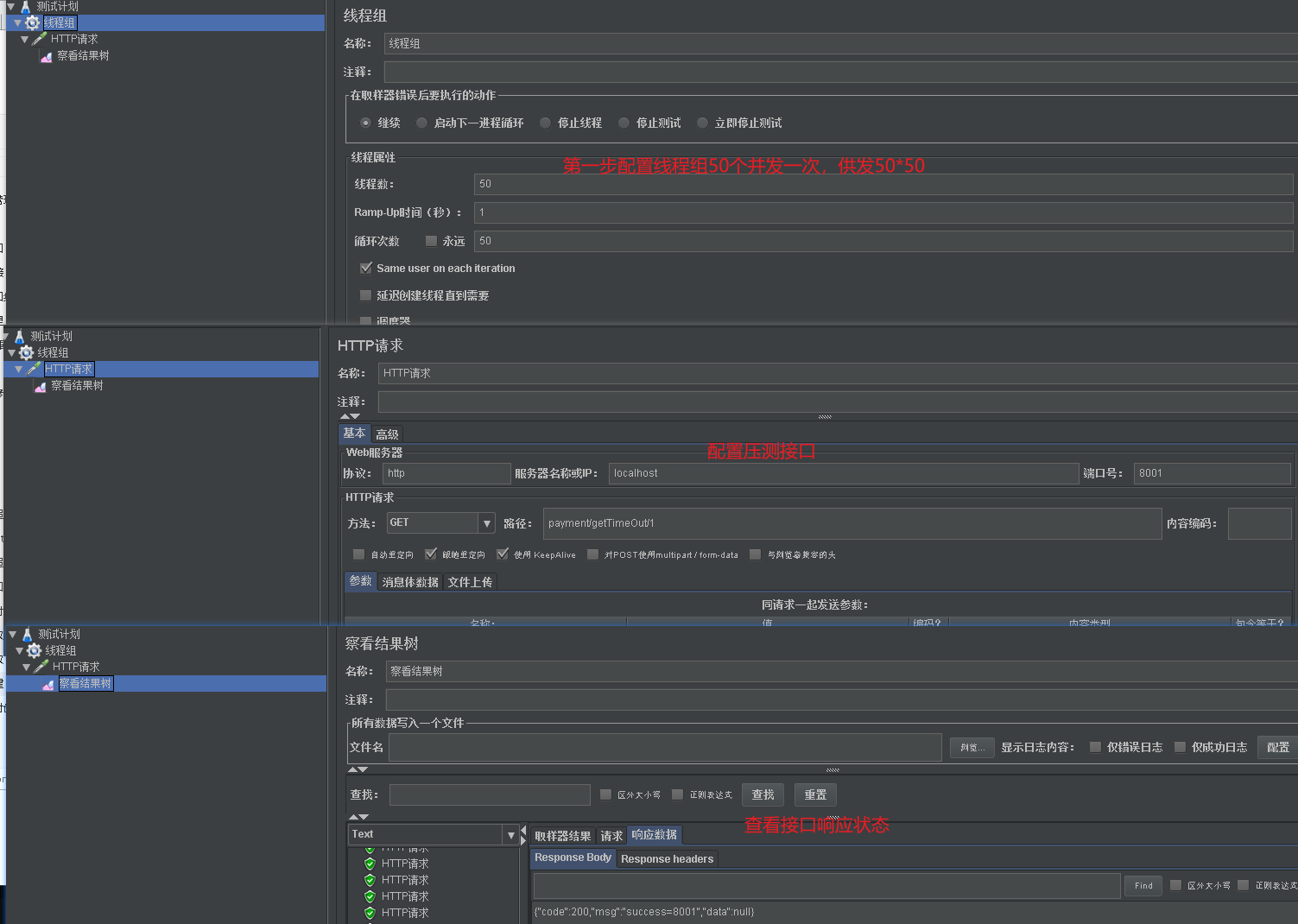
* spring中默认的tomcat的最大线程数是200.为了保护我们辛苦的笔记本。这里我们将线程数设置小点。这样我们更容易复现线程被打满的情况。线程满了就会影响到payment#createByOrder接口。

- 上面我们压测的是payment的原生接口。如果压测的是order模块。如果没有在openfeign中配置fallback。那么order服务就会因为payment#getTimeOut/id接口并发导致线程满了从而导致order模块响应缓慢。这就是雪崩效应。下面我们从两个方面来解决雪崩的发生。
业务隔离
- 上面的场景发生是因为payment#createByOrder 和payment#getTimeOut/id同属于payment服务。一个payment服务实际上就是一个Tomcat服务。同一个tomcat服务是有一个线程池的。 每次请求落到该tomcat 服务里就会去线程池中申请线程。获取到线程了才能由线程来处理请求的业务。就是因为tomcat内共享线程池。所以当payment#getTimeOut/id并发上来后就会抢空线程池。导致别的借口甚至是毫不相关的接口都没有资源可以申请。只能干巴巴的等待资源的释放。
- 这就好比上班高峰期乘坐电梯因为某一个公司集中上班导致一段时间电梯全部被使用了。这时候国家领导过来也没办法上电梯。
- 我们也知道这种情况很好解决。每个园区都会有专用电梯供特殊使用。
- 我们解决上述问题也是同样的思路。进行隔离。不同的接口有不同的线程池。这样就不会造成雪崩。
线程隔离

- 还记得我们上面为了演示并发将order模块的最大线程数设置为10.这里我们通过测试工具调用下order/getpayment/1这个接口看看日志打印情况

- 我们接口调用的地方将当前线程打印出来。我们可以看到一只都是那10个线程在来回的使用。这也是上面为什么会造成雪崩现象。
@HystrixCommand(
groupKey = "order-service-getPaymentInfo",
commandKey = "getPaymentInfo",
threadPoolKey = "orderServicePaymentInfo",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1000")
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize" ,value = "6"),
@HystrixProperty(name = "maxQueueSize",value = "100"),
@HystrixProperty(name = "keepAliveTimeMinutes",value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold",value = "100")
},
fallbackMethod = "getPaymentInfoFallback"
)
@RequestMapping(value = "/getpayment/{id}",method = RequestMethod.GET)
public ResultInfo getPaymentInfo(@PathVariable("id") Long id) {
log.info(Thread.currentThread().getName());
return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id, ResultInfo.class);
}
public ResultInfo getPaymentInfoFallback(@PathVariable("id") Long id) {
log.info("已经进入备选方案了,下面交由自由线程执行"+Thread.currentThread().getName());
return new ResultInfo();
}
@HystrixCommand(
groupKey = "order-service-getpaymentTimeout",
commandKey = "getpaymentTimeout",
threadPoolKey = "orderServicegetpaymentTimeout",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "10000")
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize" ,value = "3"),
@HystrixProperty(name = "maxQueueSize",value = "100"),
@HystrixProperty(name = "keepAliveTimeMinutes",value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold",value = "100")
}
)
@RequestMapping(value = "/getpaymentTimeout/{id}",method = RequestMethod.GET)
public ResultInfo getpaymentTimeout(@PathVariable("id") Long id) {
log.info(Thread.currentThread().getName());
return orderPaymentService.getTimeOut(id);
}
- 这里演示效果不好展示,我就直接展示数据吧。
| 并发量在getpaymentTimeout | getpaymentTimeout/{id} | /getpayment/{id} |
|---|---|---|
| 20 | 三个线程打满后一段时间开始报错 | 可以正常响应;也会慢,cpu线程切换需要时间 |
| 30 | 同上 | 同上 |
| 50 | 同上 | 也会超时,因为order调用payment服务压力会受影响 |
- 如果我们将hystrix加载payment原生服务就不会出现上面第三条情况。为什么我会放在order上就是想让大家看看雪崩的场景。在并发50的时候因为payment设置的最大线程也是10,他本身也是有吞吐量的。在order#getpyament/id接口虽然在order模块因为hystrix线程隔离有自己的线程运行,但是因为原生服务不给力导致自己调用超时从而影响运行的效果。这样演示也是为了后续引出fallback解决雪崩的一次场景模拟吧。
- 我们可以在payment服务中通过hystrix设置fallback。保证payment服务低延迟从而保证order模块不会因为payment自己缓慢导致order#getpayment这种正常接口异常。
- 还有一点虽然通过hystrix进行线程隔离了。但是我们在运行其他接口时响应时间也会稍长点。因为CPU在进行线程切换的时候是有开销的。这一点也是痛点。我们并不能随心所欲的进行线程隔离的。这就引出我们的信号量隔离了。
信号量隔离
- 关于信号量隔离这里也就不演示了。演示的意义不是很大
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1000"),
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY,value = "SEMAPHORE"),
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS,value = "6")
},
fallbackMethod = "getPaymentInfoFallback"
)
- 我们如上配置表示信号量最大为6 。 表示并发6之后就会进行等待。等待超时时间未1s。
| 措施 | 优点 | 缺点 | 超时 | 熔断 | 异步 |
|---|---|---|---|---|---|
| 线程隔离 | 一个调用一个线程池;互相不干扰;保证高可用 | cpu线程切换开销 | √ | √ | √ |
| 信号量隔离 | 避免CPU切换。高效 | 在高并发场景下需要存储信号量变大 | × | √ | × |
- 除了线程隔离、信号量隔离等隔离手段我们可以通过请求合并、接口数据缓存等手段加强稳定性。
服务降级
触发条件
- 程序发生除HystrixBadRequestException异常。
- 服务调用超时
- 服务熔断
- 线程池、信号量不够

- 在上面我们的timeout接口。不管是线程隔离还是信号量隔离在条件满足的时候就会直接拒绝后续请求。这样太粗暴了。上面我们也提到了fallback。
- 还记的上面我们order50个并发的timeout的时候会导致getpayment接口异常,当时定位了是因为原生payment服务压力撑不住导致的。如果我们在payment上加入fallback就能保证在资源不足的时候也能快速响应。这样至少能保证order#getpayment方法的可用性。

* 但是这种配置属于实验性配置。在真实生产中我们不可能在每个方法上配置fallback的。这样愚蠢至极。
* hystrix除了在方法上特殊定制的fallback以外,还有一个全局的fallback。只需要在类上通过@DefaultProperties(defaultFallback = "globalFallback")来实现全局的备选方案。一个方法满足触发降级的条件时如果该请求对应的HystrixCommand注解中没有配置fallback则使用所在类的全局fallback。如果全局也没有则抛出异常。
### 不足
* 虽然DefaultProperties可以避免每个接口都配置fallback。但是这种的全局好像还不是全局的fallback。我们还是需要每个类上配置fallback。笔者查阅了资料好像也没有
* 但是在openfeign专题里我们说了openfeign结合hystrix实现的服务降级功能。还记的里面提到了一个FallbackFactory这个类吗。这个类可以理解成spring的BeanFactory。这个类是用来产生我们所需要的FallBack的。我们在这个工厂里可以生成一个通用类型的fallback的代理对象。代理对象可以根据代理方法的方法签名进行入参和出参。
* 这样我们可以在所有的openfeign地方配置这个工厂类。这样的话就避免的生成很多个fallback。 美中不足的还是需要每个地方都指定一下。关于FallBackFactory感兴趣的可以下载源码查看或者进主页查看openfeign专题。
服务熔断
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"), //是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"), //请求次数
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"), //时间范围
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60"), //失败率达到多少后跳闸
},
fallbackMethod = "getInfoFallback"
)
@RequestMapping(value = "/get", method = RequestMethod.GET)
public ResultInfo get(@RequestParam Long id) {
if (id < 0) {
int i = 1 / 0;
}
log.info(Thread.currentThread().getName());
return orderPaymentService.get(id);
}
public ResultInfo getInfoFallback(@RequestParam Long id) {
return new ResultInfo();
}
- 首先我们通过circuitBreaker.enabled=true开启熔断器
circuitBreaker.requestVolumeThreshold设置统计请求次数circuitBreaker.sleepWindowInMilliseconds设置时间滑动单位 , 在触发熔断后多久进行尝试开放,及俗称的半开状态circuitBreaker.errorThresholdPercentage设置触发熔断开关的临界条件- 上面的配置如果最近的10次请求错误率达到60% ,则触发熔断降级 , 在10S内都处于熔断状态服务进行降级。10S后半开尝试获取服务最新状态
- 下面我们通过jmeter进行接口
http://localhost/order/get?id=-1进行20次测试。虽然这20次无一例额外都会报错。但是我们会发现一开始报错是因为我们代码里的错误。后面的错误就是hystrix熔断的错误了。一开始试by zero 错误、后面就是short-circuited and fallback failed 熔断错误了

- 正常我们在hystrix中会配置fallback , 关于fallback两种方式我们上面降级章节已经实现了。这里是为了方便看到错误的不同特意放开了。

- 在HystrixCommand中配置的参数基本都是在HystrixPropertiesManager对象中。我们可以看到关于熔断器的配置有6个参数。基本就是我们上面的四个配置
服务限流
- 服务降级我们上面提到的两种隔离就是实现限流的策略。
请求合并
- 除了熔断、降级、限流意外hystrix还为我们提供了请求合并。顾名思义就是将多个请求合并成一个请求已达到降低并发的问题。
- 比如说我们order有个接个是查询当个订单信息
order/getId?id=1突然有一万个请求过来。为了缓解压力我们集中一下请求每100个请求调用一次order/getIds?ids=xxxxx。这样我们最终到payment模块则是10000/100=100个请求。下面我们通过代码配置实现下请求合并。
HystrixCollapser
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface HystrixCollapser {
String collapserKey() default "";
String batchMethod();
Scope scope() default Scope.REQUEST;
HystrixProperty[] collapserProperties() default {};
}
| 属性 | 含义 |
|---|---|
| collapserKey | 唯一标识 |
| batchMethod | 请求合并处理方法。即合并后需要调用的方法 |
| scope | 作用域;两种方式[REQUEST, GLOBAL] ; |
REQUEST : 在同一个用户请求中达到条件将会合并
GLOBAL : 任何线程的请求都会加入到这个全局统计中 |
| HystrixProperty[] | 配置相关参数 |

- 在Hystrix中所有的properties配置都会在HystrixPropertiesManager.java中。我们在里面可以找到Collapser只有两个相关的配置。分别表示最大请求数和统计时间单元。
@HystrixCollapser(
scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,
batchMethod = "getIds",
collapserProperties = {
@HystrixProperty(name = HystrixPropertiesManager.MAX_REQUESTS_IN_BATCH , value = "3"),
@HystrixProperty(name = HystrixPropertiesManager.TIMER_DELAY_IN_MILLISECONDS, value = "10")
}
)
@RequestMapping(value = "/getId", method = RequestMethod.GET)
public ResultInfo getId(@RequestParam Long id) {
if (id < 0) {
int i = 1 / 0;
}
log.info(Thread.currentThread().getName());
return null;
}
@HystrixCommand
public List<ResultInfo> getIds(List<Long> ids) {
System.out.println(ids.size()+"@@@@@@@@@");
return orderPaymentService.getIds(ids);
}
- 上面我们配置了getId会走getIds请求,最多是10S三个请求会合并在一起。然后getIds有payment服务在分别去查询最终返回多个ResultInfo。
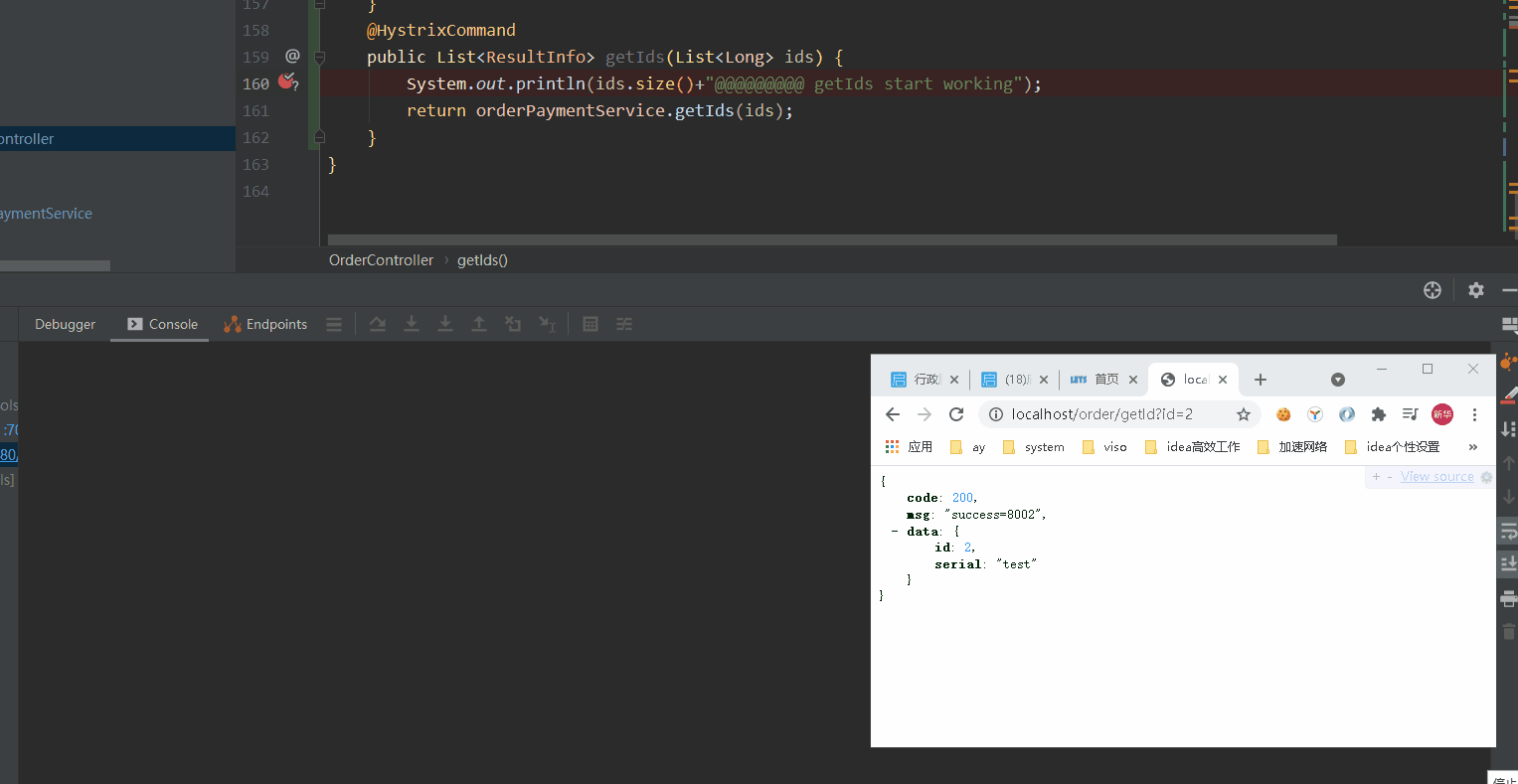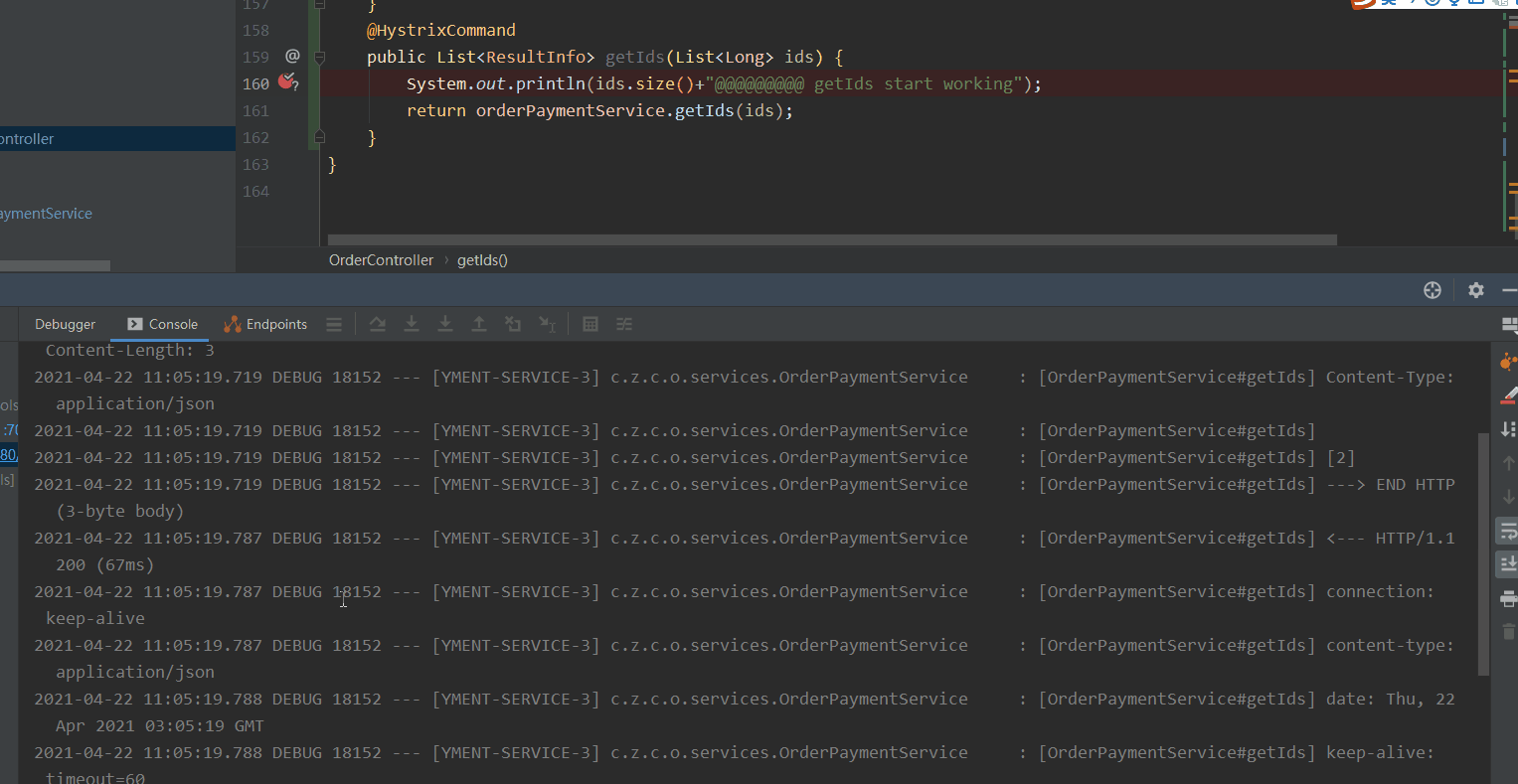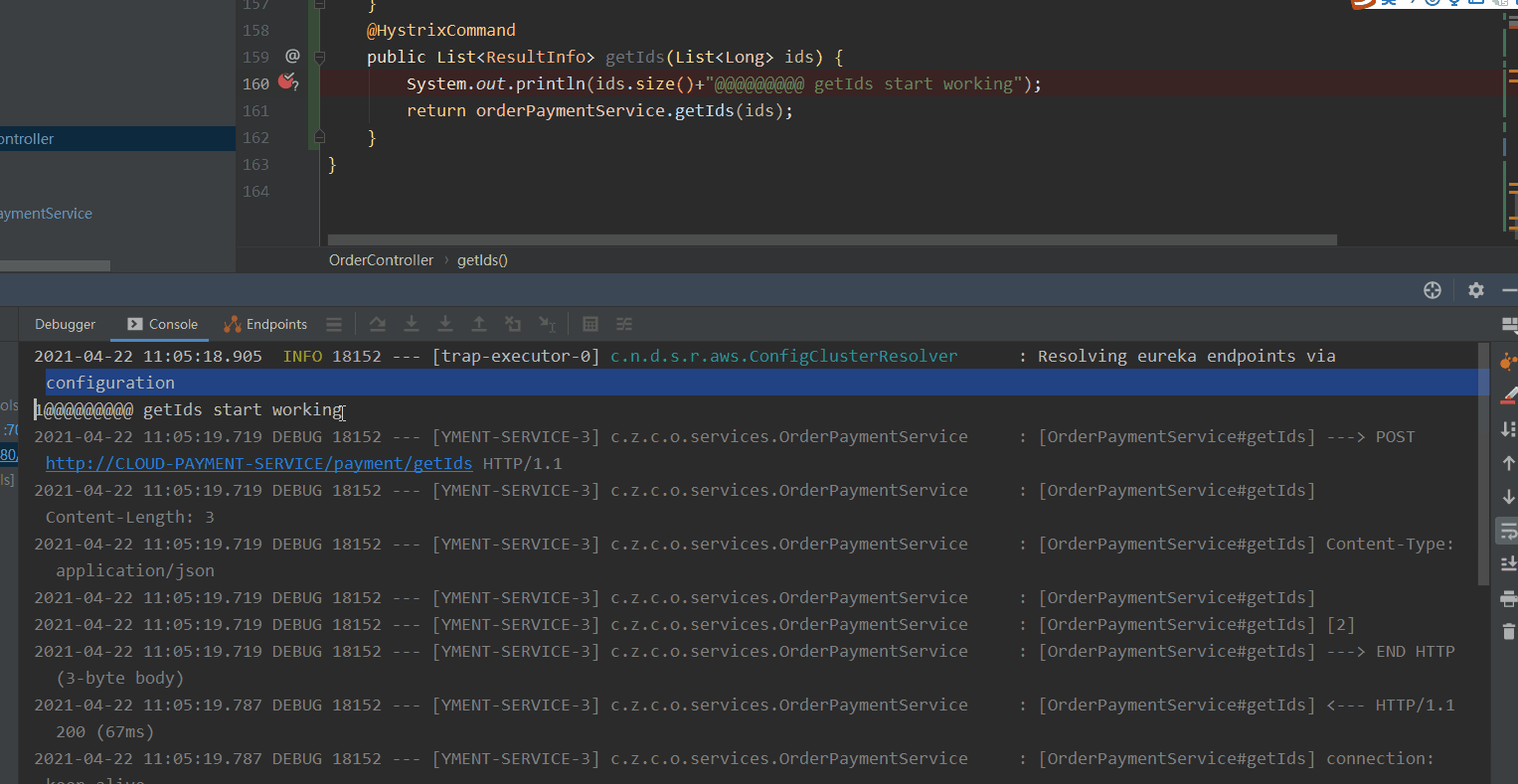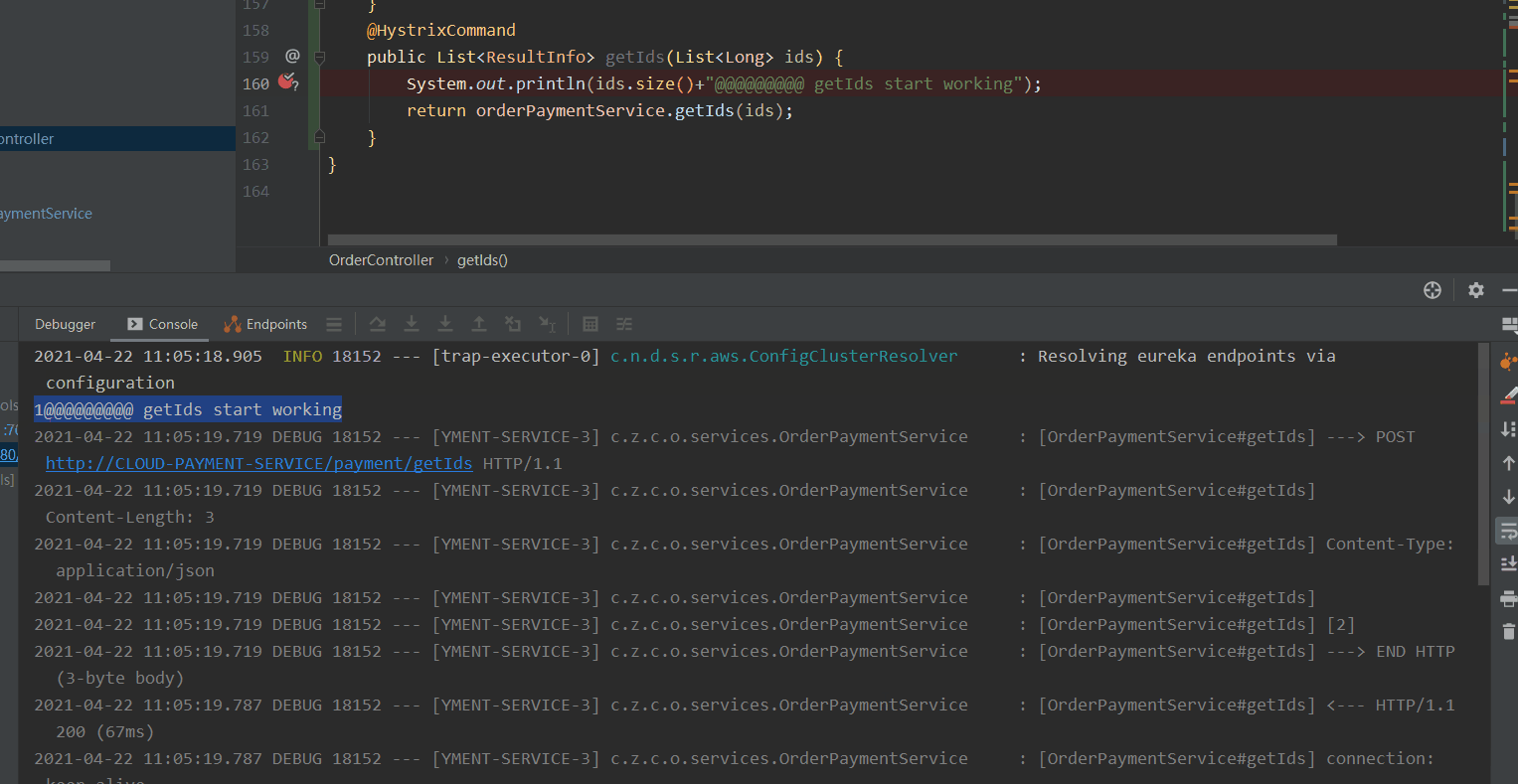
- 我们通过jemeter进行getId接口压测,日志中ids的长度最大是3 。 验证了我们上面getId接口的配置。这样就能保证在出现高并发的时候会进行接口合并降低TPS。
- 上面我们是通过请求方法注解进行接口合并处理。实际上内部hystrix是通过HystrixCommand
工作流程

- 官网给出的流程图示,并配备流程说明一共是9部。下面我们就翻译下。
- ①、创建HystrixCommand或者HystrixObservableCommand对象
* HystrixCommand : 用在依赖单个服务上
* HystrixObservableCommand : 用在依赖多个服务上 - ②、命令执行,hystrrixCommand 执行execute、queue ; hystrixObservableCommand执行observe、toObservable
| 方法 | 作用 |
|---|---|
| execute | 同步执行;返回结果对象或者异常抛出 |
| queue | 异步执行;返回Future对象 |
| observe | 返回Observable对象 |
| toObservable | 返回Observable对象 |
- ③、查看缓存是否开启及是否命中缓存,命中则返回缓存响应
- ④、是否熔断, 如果已经熔断则fallback降级;如果熔断器是关闭的则放行
- ⑤、线程池、信号量是否有资源供使用。如果没有足够资源则fallback 。 有则放行
- ⑥、执行run或者construct方法。这两个是hystrix原生的方法,java实现hystrix会实现两个方法的逻辑,springcloud已经帮我们封装了。这里就不看这两个方法了。如果执行错误或者超时则fallback。在此期间会将日志采集到监控中心。
- ⑦、计算熔断器数据,判断是否需要尝试放行;这里统计的数据会在hystrix.stream的dashboard中查看到。方便我们定位接口健康状态
- ⑧、在流程图中我们也能看到④、⑤、⑥都会指向fallback。 也是我们俗称的服务降级。可见服务降级是hystrix热门业务啊。
- ⑨、返回响应
HystrixDashboard
- hystrix 除了服务熔断、降级、限流以外,还有一个重要的特性是实时监控。并形成报表统计接口请求信息。
- 关于hystrix的安装也很简单,只需要在项目中配置actutor和
hystrix-dashboard两个模块就行了
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- 启动类上添加
EnableHystrixDashboard就引入了dashboard了。 我们不需要进行任何开发。这个和eureka一样主需要简单的引包就可以了。

- 就这样dashboard搭建完成了。dashboard主要是用来监控hystrix的请求处理的。所以我们还需要在hystrix请求出将端点暴露出来。
- 在使用了hystrix命令的模块加入如下配置即可,我就在order模块加入
@Component
public class HystrixConfig {
@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
//注意这里配置的/hystrix.stream 最终访问地址就是 localhost:port/hystrix.stream ; 如果在配置文件中配置在新版本中是需要
//加上actuator 即 localhost:port/actuator
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
}
- 然后我们访问order模块
localhost/hystrix.stream就会出现ping的界面。表示我们order模块安装监控成功。当然order也需要actuator模块 - 下面我们通过jmeter来压测我们的熔断、降级、限流接口在通过dashboard来看看各个状态吧。

- 上面的动画看起来我们的服务还是很忙的。想想如果是电商当你看着每个接口的折线图像不像就是你的心跳。太高的你就担心的。太低了就没有成就高。下面我们看看dashboard的指标详情

- 我们看看我们服务运行期间各个接口的现状。

聚合监控
- 上面我们通过新建的模块
hystrix-dashboard来对我们的order模块进行监控。但是实际应用中我们不可能只在order中配置hystrix的。 - 我们只是在上面为了演示所以在order配置的。现在我们在payment中也对hystrix中配置。那么我们就需要在dashboard中来回切换order、payment的监控数据了。
- 所以我们的聚合监控就来了。在进行聚合监控之前我们先将payment也引入hystrix。注意上面我们是通过bean方式注入hystrix.stream 的 。 访问前缀不需要actuator
新建hystrix-turbine
pom
<!--新增hystrix dashboard-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
- 主要就是新增turbine坐标,其他的就是hystrix , dashboard等模块,具体查看结尾处源码
yml
spring:
application:
name: cloud-hystrix-turbine
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://localhost:7001/eureka
instance:
prefer-ip-address: true
# 聚合监控
turbine:
app-config: cloud-order-service,cloud-payment-service
cluster-name-expression: "'default'"
# 该处配置和url一样。如果/actuator/hystrix.stream 的则需要配置actuator
instanceUrlSuffix: hystrix.stream
启动类
启动类上添加EnableTurbine注解

源码: https://gitee.com/zxhTom/cloud-framework-root
作者:烟花散尽13141
链接:https://blog.csdn.net/u013132051/article/details/116135782
来源:csdn
补充
如何学习java ,分享两个万能学习的资料库:
1、书籍:
2:视频教程:
程序员必读Java书籍SpringBoot、Spring、Mybatis、Redis、RabbitMQ、SpringCloud、高并发(持续更新)
觉得不错的小伙伴记得转发关注哦,后续会持续更新精选技术文章!