机器学习
人工找特征 让电脑校对这些特征 计算最优表现
深度学习
电脑自己找特征(获得多层习得特征)
深度学习来学习高维向量,将词放在高维向量空间中,这些空间就是词义空间
词义相同的形成聚集块
坐标轴并没有实际意义,用了降维分析后会丢失空间中许多信息
将词的每个部分都想象成向量的一部分
目标
通过词汇预测上下文
我们选择一个密集型向量,使得它可以预测目标词汇中的其他文本
Word2Vec:构建一个简单的,快速的训练模型,让我们处理数十亿的单词并生成的单词表示
- 两个用于生成词汇向量
- 两个用来训练算法
Skip-gram prediction
核心:在每一个算步中都取一个词作为中心词汇
比如在句子...furing into banking cnises as...中,选取bangking作为中心词汇(m表示半径,即窗口半径)
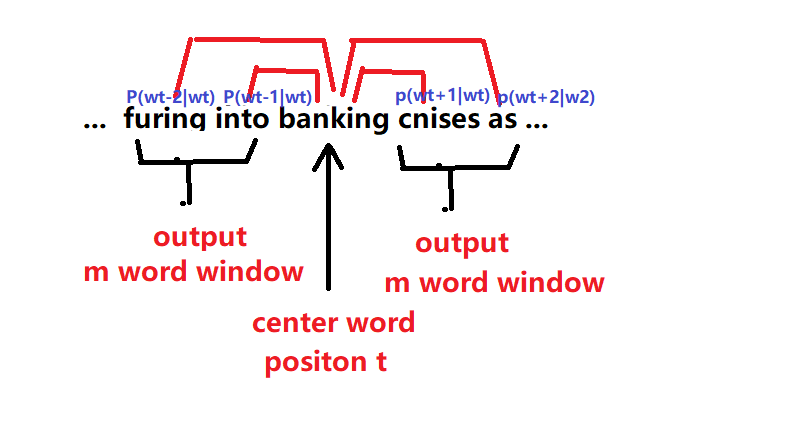
则存在一个概率分布使得中心词汇左右的上下文的概率最大
Loss function:

思想
通过内积衡量两个单词的相似性
通过SoftMax将数值变为概率(逻辑回归)
推导过程

更多:https://www.jianshu.com/p/a1163174ebaf
梯度下降算法
python代码
while True:
theta_grad=evaluate_gradient(T,corpus,theta)
theta=theta-alpha*theta_grad
SGD随机梯度下降算法
只要我们随机选取一个位置,就有了一个中心词汇以及它们周围的词汇。我们移动一个位置,对所有的参数求梯度。
Word2Vec
- 已知一个语料库(通过计数等方法获得每个词在其他词附近出现的次数得到语料库中的共现矩阵)
- 计算概率,给定中心词
- 为了求出概率的最值
- 随机梯度下降法
SVD奇异值分解(降维)


优化 Glove模型
优化一 遍历整个语料库--->取随机的不同时出现的词(仅取5-10个随即词,最小化它们共现的概率)
优化二 一些高频词汇(he、the等)将最大次数设为100
优化三 根据距离中心词汇不同距离的步数设为不同的值
单词向量类比法
根据研究发现,单词具有多重意义符合线性组合
使用余弦距离表示相似性 d=arg max((xb-xa+xc)Txi/||xb-xa+xc||)
比如,max:woman king:queen