刚开始看书有些问题没有看懂,查阅了很多博客,发现说的很有道理但是又出现新的问题,这里谈谈我的理解:
一、目的和思想
有一些数据x和类别y,我们的目的是用这些数据做分类器,通过sigmoid函数(一种单位跃阶函数)实现分类:
ƒ(z)=1/(1+e-z)
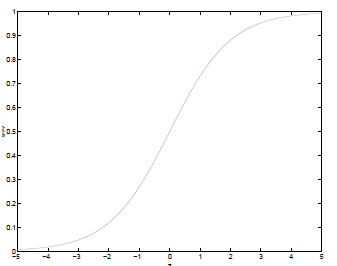
可以看到sigmoid函数值域(0,1),在0处变化很陡。
我们将x的线性组合(因为可能不止一个特征),带入到这个函数中,可以得到一个函数值y,如果这个函数值y>0.5我们就认为它是种类1,否则我们认为它是种类0.在这里,其实我们潜意识里,是把这个函数值y当作是种类1的概率即P(class=1|x)。但是,正如前文所说可能不止一个特征,这些线性组合之间就存在系数,我们设这个系数为向量w。所以P(class=1|x;w)=1/(1+e-wx),w为参数也是未知数。所以如果我们求得最合适的w,就可以实现这个分类器:
P(class=1|x;w)=1/(1+e-wx)=hw(x),P(class=0|x;w)=1-1/(1+e-wx)=e-wx/(1+e-wx)=1-hw(x)
发现其符合伯努利分布:
P(class|x;w)=hw(x)class(1-hw(x))1-class
为求参数w,我们想到了极大似然估计法,求得了一个关于w的概率函数:
l(w)=∏P(class|x;w)=Π(hw(x)class(1-hw(x))(1-class)
求对数:
lnl(w)=Σclasslnhw(x)+(1-class)ln(1-hw(x))
回想一下极大似然估计中,我们是为了这个最大,然后对它进行求导=0求得参数,在这里我们使用梯度上升法去求极值。
二、梯度上升法:
这是一个爬坡的类似概念,给你一个起点,确定极值方向迈开步子,就可以向高坡爬去:
Xi+1=Xi+α∂ƒ(X)/∂X
所以这是一个求极值的方法
三、
我们为了lnl(w)=Σclasslnhw(x)+(1-class)ln(1-hw(x))这个最大,使用梯度上升法:
wi+1=wi+α∂ƒ(w)/∂w
∂ƒ(w)/∂w这个需要一个关于w的函数,即ƒ(w)=lnl(w)=Σclasslnhw(x)+(1-class)ln(1-hw(x)),两边同时求导:

所以, ∂ƒ(w)/∂w=(class-hw(x))x
梯度迭代:
wi+1=wi+α∂ƒ(w)/∂w=wi+α*(class-hw(x))x
1 from numpy import *
2 def sigmoid(inX):
3 return 1.0/(1+exp(-inX))
4 def gradAscent(dataMatIn,classLabels):
5 dataMatrix=mat(dataMatIn)#将特征数据变为矩阵
6 labelMat=mat(classLabels).transpose()#类别标签变为列向量
7 m,n=shape(dataMatrix)#获得数据矩阵的行和列
8 alpha=0.001#步长
9 maxCycles=500#迭代次数
10 weights=ones(n,1)
11 for k in range(maxCycles):
12 h=sigmoid(dataMatrix*weights)
13 error=(labelMat-h)#差别
14 weights=weights+alpha*dataMatrix.transpose()*error#上面的推导!
15 return weights
16 #画出数据集和Logistic回归最佳拟合直线的函数
四、随机梯度上升
因为梯度上升在每次更新参数时都要遍历整个数据集(一次处理所有数据被叫做批处理),当数据量庞大时,计算复杂度将非常高。随机梯度上升一次采用一个样本点更新回归系数。由于可以在新样本到来时对分类进行增量式更新,因而随机梯度上升算法可以是一个在线学习算法。
1 #随机梯度上升算法
2 def stocGradAscent0(dataMatrix,classLabels):
3 m,n=shape(dataMatrix)
4 alpha=0.01
5 weights=ones(n)
6 for i in range(m): #可以看到梯度上升算法是由迭代次数控制所有的数据都参与运算,随机梯度上升算法在数据取,只选取某组数据
7 h=sigmoid(sum(dataMatrix[i]*weights))
8 error=classLabels[i]-h
9 weights=weights+alpha*error*dataMatrix[i]
10 return weights
11 #改进的随机梯度上升算法
12 def stocGradAscent1(dataMatrix,classLabels,numIter=150):
13 m,n=shape(dataMatrix)
14 weights=ones(n)
15 for j in range(numIter):
16 dataIndex=range(m)
17 for i in range(m):
18 alpha=4/(1.0+j+i)+0.01#alpha在每次迭代时调整
19 randIndex=int(random.uniform(0,len(dataIndex)))#随机选取更新
20 h=sigmoid(sum(dataMatrix[randIndex]*weights))
21 error=classLabels[randIndex]-h
22 weights=weights+alpha*error*dataMatrix[randIndex]
23 del(dataIndex[randIndex])#将选取的删除
24 return weights
五、参数调整
根据不同的需要对参数进行调整
alpha(步长):代表着多次迭代后新数据的影响程度
迭代次数:判断优化算法优劣的可靠方法是看它是否收敛,也就是参数是否达到了稳定值,是否还会不断地变化。可以通过不同的迭代次数观察参数的变化情况。