在上一篇博客CNN核心概念理解中,我们以LeNet为例介绍了CNN的重要概念。在这篇博客中,我们将利用著名深度学习框架PyTorch实现LeNet5,并且利用它实现手写体字母的识别。训练数据采用经典的MNIST数据集。本文主要分为两个部分,一是如何使用PyTorch实现LeNet模型,二是实现数据准备、定义网络、定义损失函数、训练、测试等完整流程。
一、LeNet模型定义
LeNet是识别手写字母的经典网络,虽然年代久远,但从学习的角度仍不失为一个优秀的范例。要实现这个网络,首先来看看这个网络的结构:
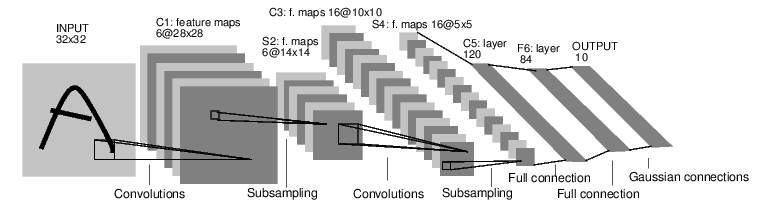
这是一个简单的前向传播的网络,它接受32x32图片作为输入,经过卷积、池化和全连接层的计算,最终给出输出结果。实现的过程并不复杂:
1 from torch import nn 2 from torch.nn import functional as F 3 4 class LeNet(nn.Module): 5 def __init__(self): 6 super(LeNet, self).__init__() 7 # 1 input image channel, 6 output channels, 5x5 square convolution 8 self.conv1 = nn.Conv2d(1, 6, 5, padding=2) 9 self.conv2 = nn.Conv2d(6, 16, 5) 10 # an affine operation: y = Wx + b 11 self.fc1 = nn.Linear(16 * 5 * 5, 120) 12 self.fc2 = nn.Linear(120, 84) 13 self.fc3 = nn.Linear(84, 10) 14 15 16 def forward(self, x): 17 x = F.relu(self.conv1(x)) 18 # Max pooling over a (2, 2) window 19 x = F.max_pool2d(x, 2) 20 x = F.relu(self.conv2(x)) 21 x = F.max_pool2d(x, 2) 22 23 x = x.view(x.size(0), -1) 24 x = F.relu(self.fc1(x)) 25 x = F.relu(self.fc2(x)) 26 x = self.fc3(x) 27 return x
我们继承了nn.Module模块,在__init__中完成了卷积层和全连接层的初始化。值得注意的是由于池化层没有参数,因此并没有一起初始化。初始化参数包括输入个数、输出个数,卷积层的参数还有卷积核大小。除此之外在第一个卷积层C1中还定义了padding,这是因为数据集中图片是28x28的,padding=2表明输入的时候在图片四周各填充2个像素的空白,将输入变成了32x32。
在forward中我们实现了前向传播。这里我们根据定义对输入依次进行卷积、激活、池化等操作,最后返回计算结果。在全连接层之前,有一个对数据的展开操作,我们使用Tensor的view函数实现,这个函数可以将Tensor转变成任意合法的形状。我们只定义了forward函数,而没有定义backword函数,这是因为PyTorch的自动微分功能自动帮我们完成了反向传播的定义。
LeNet模型这样就定义完成了。但是需要注意的是,这个网络和最初LeCun论文中的实现略有不同:
- 原始论文中C3与S2并不是全连接而是部分连接,这样能减少部分计算量。而现代CNN模型中,比如AlexNet,ResNet等,都采取全连接的方式了。我们的实现在这里做了一些简化。
- 原文中使用双曲正切作为激活函数,而我们使用了收敛速度更快的ReLu函数。
- 按照原文描述,网络最后一层为高斯连接层。而我们为了简单起见还是用了全连接层。
LeNet其实是一个比较“古老”的模型了,我们不必追求完美的复现,理解其中关键的概念即可。
二、准备数据
为PyTorch准备数据非常方便。对于一些经典数据集,PyTorch已经将它们封装好了,我们可以直接拿来用。当然MNIST数据集也在此列,但是我们仍然定义了自己的数据集,因为这种方法可以处理更通用的情况。为了定义自己的数据集,首先要继承torch.utils.data.database类,然后实现至少__getitem__和__len__两个方法。
1 import gzip, struct 2 import numpy as np 3 import torch.utils.data as data 4 5 class MnistDataset(data.Dataset): 6 def __init__(self, path, train=True): 7 self.path = path 8 if train: 9 X, y = self._read('train-images-idx3-ubyte.gz', 10 'train-labels-idx1-ubyte.gz') 11 else: 12 X, y = self._read('t10k-images-idx3-ubyte.gz', 13 't10k-labels-idx1-ubyte.gz') 14 15 self.images = torch.from_numpy(X.reshape(-1, 1, 28, 28)).float() 16 self.labels = torch.from_numpy(y.astype(int)) 17 18 def __getitem__(self, index): 19 return self.images[index], self.labels[index] 20 21 def __len__(self): 22 return len(self.images) 23 24 def _read(self, image, label): 25 with gzip.open(self.path + image, 'rb') as fimg: 26 magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16)) 27 X = np.frombuffer(fimg.read(), dtype=np.uint8).reshape(-1, rows, cols) 28 with gzip.open(self.path + label) as flbl: 29 magic, num = struct.unpack(">II", flbl.read(8)) 30 y = np.frombuffer(flbl.read(), dtype=np.int8) 31 return X, y
由于官网上提供的MNIST数据集是gzip压缩格式,因此我们在读取的时候首先要解压,然后转成numpy形式,最后转成Tensor保存起来。之后在__getitem__中返回相应的数据和类别就可以了,__len__函数直接返回数据集的大小。由于MNIST数据集有训练和测试两部分,因此需要分类处理。
三、使用数据训练网络
我们首先用DataLoader类加载数据集,DataLoader负责将数据转化成适当的形式放入模型训练。使用DataLoader可以方便地控制微批次大小、线程数等参数。
1 train_dataset = MnistDataset('./data/') 2 train_loader = data.DataLoader(train_dataset, shuffle=True, batch_size=256, 3 num_workers=4)
这时候可以测试数据有没有成功加载进来,如图所示。

下一步定义评价函数和优化器,这一步很重要,但不是本文重点。直接给出代码:
1 criterion = nn.CrossEntropyLoss(reduction='sum') 2 optimizer = optim.Adam(net.parameters(), lr=1e-3, betas=(0.9, 0.99))
最后的给出训练过程的简化版。这个两层循环就是实际的训练过程,外层循环控制遍历数据集的次数,内层循环控制每一次参数更新。
1 for epoch in range(5): 2 for (inputs, label) in train_loader: 3 # zero the parameter gradients 4 optimizer.zero_grad() 5 # forward + backward + optimize 6 output = net(inputs) 7 loss = criterion(output, label) 8 loss.backward() 9 optimizer.step()
三、模型评估
模型经过训练之后,将测试集输入放入模型,将输出和标签比对可以计算出模型的准确率等信息,进而对模型不断优化。此外如果想要了解模型到底学到了什么东西,还可以将中间层结果输出。如图所示:

这部分代码没有给出,完整代码可以到Github页面查看。