SQL (Structure Query Language)
1.RDBMS 指的是关系型数据库管理系统,可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
2.增删改查构成了SQL的DML部分,而DLL部分如下:
SQL 中最重要的 DDL 语句:
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
第一部分 SQL 基本语句
关键词 DISTINCT 用于返回唯一不同的值。
SELECT DISTINCT 列名称 FROM 表名称
引号的使用
请注意,我们在例子中的条件值周围使用的是单引号。
这是正确的: SELECT * FROM Persons WHERE FirstName='Bush' 这是错误的: SELECT * FROM Persons WHERE FirstName=Bush
Order by的使用
以字母顺序显示公司名称(Company),并以数字顺序显示顺序号(OrderNumber):
SELECT Company, OrderNumber FROM Orders ORDER BY Company, OrderNumber
这句话是说,查询公司名和序号,首先按照公司的名称进行排序,如果相同,则按照顺序号升序排序,(升序为ASC, 降序为DESC)
Update 语句
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
DELETE 语句
DELETE FROM 表名称 WHERE 列名称 = 值
第二部分 SQL 高级语句
TOP 子句
TOP 子句用于规定要返回的记录的数目。
Sql Server中使用top语法为:select top 10 列名 from 表 (显示表的前10条数据) select top 50 percent 列名 from 表(显示标的百分之50的数据) Mysql中,使用的是limit,相同功能的语法为:select 列名 from 表 limit 10 Oracle中使用的是rownum,表示行数,select 列名 from 表 where rownum <=10
SQL 通配符

现在,我们希望从上面的 "Persons" 表中选取居住的城市以 "A" 或 "L" 或 "N" 开头的人:
SELECT * FROM Persons WHERE City LIKE '[ALN]%'
//in操作,表示允许我们在Where中规定多个值
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...) //column_name列名为任意一个均能查出
BETWEEN 操作符
操作符 BETWEEN ... AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
重要事项:(between and的区间的左右开闭情况,对于不同数据库有不同的规定)不同的数据库对 BETWEEN...AND 操作符的处理方式是有差异的。某些数据库会列出介于 "Adams" 和 "Carter" 之间的人,但不包括 "Adams" 和 "Carter" ;某些数据库会列出介于 "Adams" 和 "Carter" 之间并包括 "Adams" 和 "Carter" 的人;而另一些数据库会列出介于 "Adams" 和 "Carter" 之间的人,包括 "Adams" ,但不包括 "Carter" 。
【还可以用Not操作符表示不在某个范围内的记录,where lastname not between ‘Adams’ and ‘Carter’】
SQL JOIN
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
- JOIN: 如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
SQL UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table_name1 UNION ALL // UNION表示选取不同的值,All允许重复值 SELECT column_name(s) FROM table_name2
SELECT INTO 语句
SELECT INTO 语句从一个表中选取数据,然后把数据插入另一个表中。
SELECT INTO 语句常用于创建表的备份复件或者用于对记录进行存档。
SELECT * INTO new_table_name [IN externaldatabase] FROM old_tablename
实例:在Mysql中,执行上述语句,如下所示:
SELECT `姓名`,`学号` INTO new_table from student LIMIT 4
[Err] 1327 - Undeclared variable: new_table
报错原因:mysql 数据库是不支持 SELECT INTO FROM 这种语句,采用如下方式进行创建即可
CREATE table new_table (SELECT `姓名`,`学号` from student LIMIT 4)
SQL 约束
约束用于限制加入表的数据的类型。
我们将主要探讨以下几种约束:
- NOT NULL 约束强制列不接受 NULL 值
- UNIQUE 约束唯一标识数据库表中的每条记录。
- 当表已被创建时,如需在 "Id_P" 列创建 UNIQUE 约束,请使用下列 SQL:
ALTER TABLE Persons //更改表,增加unique约束 ADD UNIQUE (Id_P)
ALTER TABLE Persons DROP INDEX uc_PersonID //删除unique约束
- 当表已被创建时,如需在 "Id_P" 列创建 UNIQUE 约束,请使用下列 SQL:
- PRIMARY KEY UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
- (请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束)
-
CREATE TABLE Persons ( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CONSTRAINT pk_PersonID PRIMARY KEY (Id_P,LastName) //命名 PRIMARY KEY 约束,以及为多个列定义 PRIMARY KEY 约束 )
- FOREIGN KEY ()
- 一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY
-
CREATE TABLE Orders ( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int, PRIMARY KEY (Id_O), FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) //本表的外键Id_p为Person表中的主键Id_p )
- CHECK
-
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限制。
-
CREATE TABLE Persons ( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CHECK (Id_P>0) //约束Id_p必须大于0 //当约束多个列时,CONSTRAINT chk_Person CHECK (Id_P>0 AND City='Sandnes') )
-
- DEFAULT (DEFAULT 约束用于向列中插入默认值
-
CREATE TABLE Orders ( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int DEFAULT 100, //默认值为100 OrderDate date DEFAULT GETDATE() //日期默认值为当前 )
-
//更改Persons表中的City列的默认值为SANDNES ALTER TABLE Persons ALTER City SET DEFAULT 'SANDNES'
-
SQL 索引
CREATE INDEX 语句用于在表中创建索引。(用户无法看到索引,它们只能被用来加速搜索/查询。)
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
(注释:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引)
CREATE UNIQUE INDEX index_name //unique表示唯一的索引,如果不加此关键词,则允许重复值 ON table_name (column_name)
Drop ————通过使用 DROP 语句,可以轻松地删除索引、表和数据库。
以mysql为例,基本语法均为:“更改表+如何更改”
例如:
ALTER TABLE table_name DROP INDEX index_name
Drop table为删除表,truncate teble为删除表内数据,但是不删除表本身
ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
//在表中,增加一列paiming,数据类型为varchar类型
ALTER TABLE student ADD paiming VARCHAR(20)
//删除表中的某一列,需指出删除的是列COLUMN
ALTER TABLE table_name DROP COLUMN column_name
//修改表中的某一列。
ALTER TABLE table_name ALTER COLUMN column_name datatype
AUTO INCREMENT 字段
我们通常希望在每次插入新记录时,自动地创建主键字段的值。
我们可以在表中创建一个 auto-increment 字段。
CREATE TABLE Persons ( P_Id int NOT NULL AUTO_INCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (P_Id) )
默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1,可以使用alter关键字对其初始值进行更改
alter table Persons auto_increment=100 表示,auto_increment的初始值为100
SQL VIEW(视图) 视图是可视化的表。
什么是视图?
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
创建视图
create view view_name as select column_name from table_name where condition
注释:视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
//等待后续补充......
MySQL Date 函数
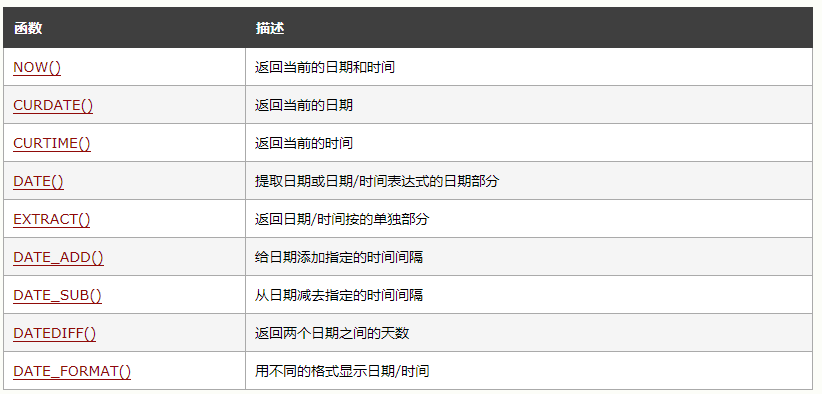
事实证明, 在Mysql中,datetime类型存在问题,需要将datetime换成timestamp类型

EXTRACT() 函数
EXTRACT() 函数用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等等。
SELECT EXTRACT(YEAR FROM OrderDate) AS OrderYear, EXTRACT(MONTH FROM OrderDate) AS OrderMonth, EXTRACT(DAY FROM OrderDate) AS OrderDay, EXTRACT(MINUTE FROM OrderDate) AS OrderMin FROM Orders
Date_Add()函数:给定日期添加指定的时间间隔(Date_Sub是减法),如图所示,将原来的时间,增加两天,进行更新

DATEDIFF() 函数:返回两个日期之间的天数。

DATE_FORMAT() 函数:显示不同的格式
重点记:
SELECT * from orders where DATE(OrderDate) ='2019-09-12' //DATE提取OrderDate中的日期部分 SELECT * from orders where EXTRACT(YEAR FROM OrderDate) ='2019' //extract提取OrderDate中对应单元,即YEAR、MONTH、DAY等单元
IS NULL 和 IS NOT NULL 操作符。
表示允许其是不是为空
DBMS - 数据库管理系统(Database Management System)
RDBMS - 关系数据库管理系统(Relational Database Management System)
第三部分 SQL 函数
SQL 拥有很多可用于计数和计算的内建函数。
两种:1Aggregate函数2Scalar函数
AVG()计算某字段的平均值
SELECT AVG(OrderPrice) AS OrderAverage FROM Orders
COUNT() 函数返回匹配指定条件的行数
SELECT COUNT(column_name) FROM table_name
SELECT COUNT(*) FROM table_name 这句话显示表中的记录数
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目
FIRST() 函数返回指定的字段中第一个记录的值。
然而,在Mysql中是不支持First函数的,采用limit来实现第一条或前几条记录

同样,在mysql中,Last函数也不支持,可以采用逆序,选取Limit进行实现
SUM 函数返回数值列的总数(总额)。
注意:Sum函数是求和,而count函数是统计记录数目
Group By语句 GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer //返回每个顾客的总消费金额,这样的话,采用Groupby对客户进行分组
HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
那么having语句也是限定条件,到底和Where有什么不同呢??????????????
根据上边红色部分的字,Where只能修饰返回的单一值,不能和合计函数一起用,因此,但对合计函数进行限定时,需采用having进行修饰!!!
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer HAVING SUM(OrderPrice)<2000 //比如这个,查找订单总金额少于 2000 的客户。
UCASE() 和LCASE()函数,是将字段的值转换为大小写
MID() 函数
MID 函数用于从文本字段中提取字符。(感觉这个函数应该用处不小)
语法:
SELECT MID(column_name,start[,length]) FROM table_name

LEN() 函数
LEN 函数返回文本字段中值的长度。
注意:在MySQL中,对应的函数为LENGTH(str)函数,如下:

ROUND() 函数
ROUND 函数用于把数值字段舍入为指定的小数位数。
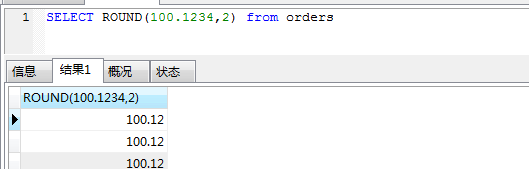
亲测:如果所查列中,小数位数为1位,你想保留两位,它不会自动补零!!!
基本的语句和语法就这些了!!!期待更多的内容~