1. YOLO v1
论文 https://arxiv.org/abs/1506.02640
之前的网络是分类和定位之后把物体检测出来。Yolo 将物体检测任务把位置和某一类的概率放在张量里,通过回归拟合出一个张量进行检测,通过YOLO,每张图像只需要“看一眼”就能得出图像中都有哪些物体和这些物体的位置。
为了图像能够找到小的物体将图像上采样到 (448 imes448)作为输入图像。一个神经网络从一张图像预测 bounding box 的坐标及包含物体的置信度和物体的可能性。然后进行非极大值抑制、筛选Boxes。
使用相当于简化的 GoogLeNet,包含20层。数据集采用 ImageNet 1000-class 分类任务数据集的 Pretrain 卷积层,20层卷积层,加上一个 average pooling layer 再加上一个全连接层作为 Pretrain 网络。
将输入的图像由 (224 imes224)上采样至 (mathbf{448 imes 448})。预测结果归一化至 (0sim 1),使用 Leaky RELU作为激活函数。
为了防止过拟合第一个全连接层后面使用 ratio=0.5 的 Dropout层。

1.1 网络结构
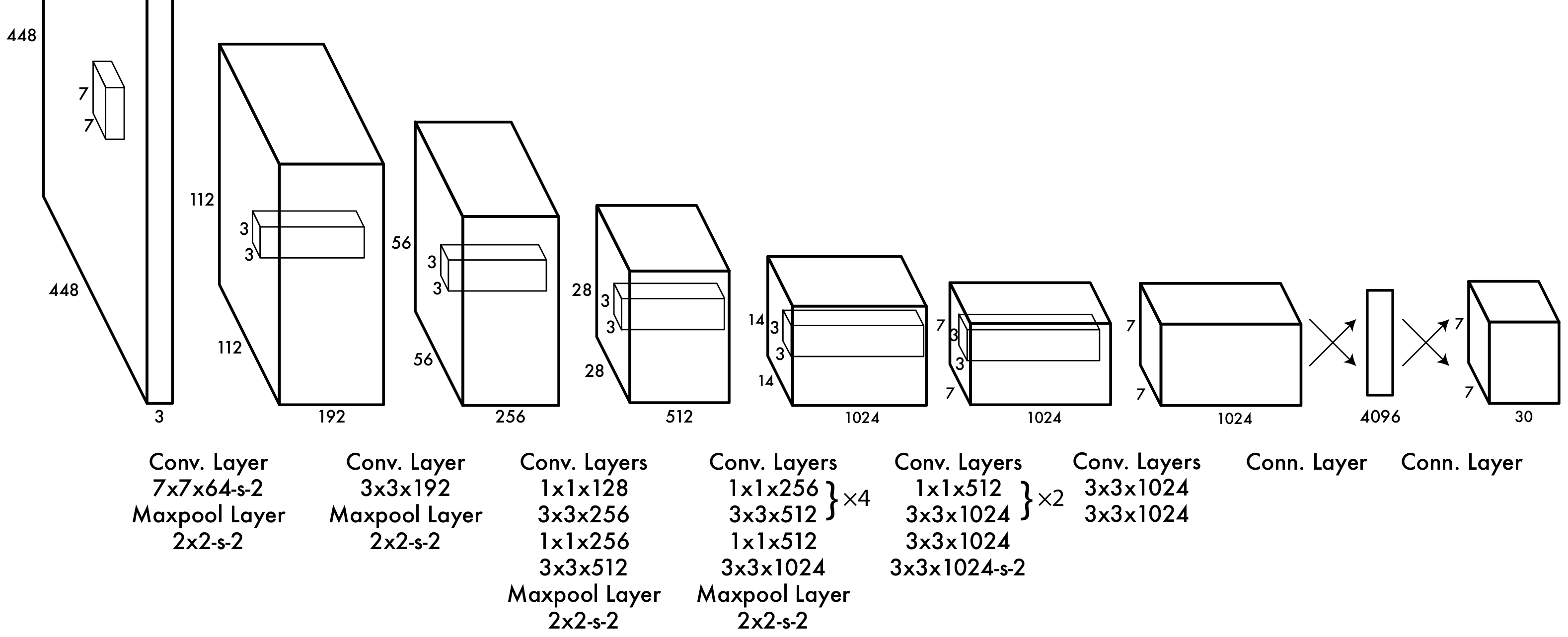
YOLO网络结构由24个卷积层与2个全连接层构成,在Pascal VOC数据上网络入口(448 imes448),输出为最后一个全连接层reshape后的 (7 imes 7 imes 30)的张量数据块。
栅格 Grid Cell
将图像分成 (S imes S)个网格,比如 (7 imes 7)。下图中物体的中心点在第5行、第2列的格子内,这个格子负责预测图像中的该物体。

预测 Bounding box 和 物体
具体地每个格子预测 (B=2)个 Bounding box,一个竖向矩形,一个横向矩形。
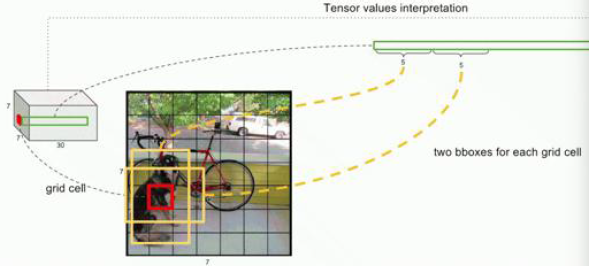
预测的准确度综合考虑这个格子存在物体的概率以及 Predicted Bounding box 与 Ground truth box 的 IoU(Intersection over Union)进行打分 Confidence score,( ext{Confidence} < 1)。( ext{Confidence} = Pr( ext{object}) imes ext{IoU}_ ext{pred}^ ext{truth}),如果该格子不存在物体 (Pr( ext{object})=0),则 ( ext{Confidence} =0)。
每个格子的预测包含 Boundging box中心的坐标 (x),(y) 和长宽 (h),(w)以及是否存在物体的 ( ext{Confidence})值,并且全部归一化到 ([0,1])之间。两个 Bounding box 的预测结果共占用(10)个维度。
已知物体预测类别(Pr( ext{class}_imid ext{object}))
每个格子需要预测已知包含一个物体的条件下属于某一类( ext{class}_i)的概率 (Pr( ext{class}_imid ext{object})) ,对于 Pascal VOC 数据共有 (c=20) 个类别。所以共有 (20) 个维度的结果。所以对于对于 Pascal VOC 数据共有 (5 imes B+c=5 imes 2+20=30) 个维度的结果,其中前面 (10) 个为两个 Bounding box 的预测结果,后面为类别的预测结果。
所以在Pascal VOC数据上总的输出维度为 (S imes S imes(5 imes B+c)=7 imes7 imes(5 imes 2+20)=7 imes 7 imes 30)
在测试阶段的总分综合考虑该格子是物体的概率和 IoU 值以及物体所属类别的条件概率:
( ext{Confidence} imes Pr( ext{class}_imid ext{object})= Pr( ext{object}) imes ext{IoU}_ ext{pred}^ ext{truth} imes Pr( ext{class}_imid ext{object})= Pr( ext{object}) imes Pr( ext{class}_imid ext{object}) imes ext{IoU}_ ext{pred}^ ext{truth}= ext{IoU}_ ext{pred}^ ext{truth} imes Pr( ext{class}_i))
目标函数

由坐标(x,y,w,h)预测误差、IoU误差、分类误差三部分组成,并使用了 (lambda_{ ext{coord}}), (lambda_{ ext{noobj}})进行协调。(i) 表示网格 (iin[0,S^2));(j) 表示Bounding box,(jin[0,B))。(1_{ij}^{ ext{obj}}=1) 表示第 (i) 个格子第(j)个Bounding box含有物体,(1_{ij}^{ ext{obj}}=0)表示没有物体,即对于大量没有物体的Bounding box不进行处理。
坐标预测误差
(color{darkcyan}{lambda_{ ext{coord}}sumlimits_{i=0}^{S^2}sumlimits_{j=0}^B 1_{ij}^{ ext{obj}}[(x_i-hat{x}_i)^2+(y-hat{y}_i)^2]+lambda_{ ext{coord}}sumlimits_{i=0}^{S^2}sumlimits_{j=0}^B 1_{ij}^{ ext{obj}}[(sqrt{w_i}-sqrt{hat{w}_i})^2+(sqrt{h}-sqrt{hat{h}_i})^2}])
开根号是为了让大的 Bounding box 和 小的 Bounding box损失平衡,不至于差异太大。让小的 Bounding box 的偏移有更大的损失,因为小的 Bounding box 的偏移更不能容忍。
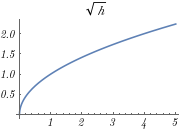
IoU误差
- 含有物体object的 Bounding box 的 Confidence 误差
(color{red}{+sumlimits_{i=0}^{S^2}sumlimits_{j=0}^B 1_{ij}^{ ext{obj}}(C_i-hat{C}_i)^2}) - 不含物体object的 Bounding box 的 Confidence 误差
(color{orange}{+lambda_{ ext{noobj}}sumlimits_{i=0}^{S^2}sumlimits_{j=0}^B 1_{ij}^{ ext{noobj}}(C_i-hat{C}_i)^2})
分类误差
(color{purple}{+sumlimits_{i=0}^{S^2} 1_{i}^{ ext{obj}}sumlimits_{cin classes}(p_i(c)-hat{p}_i(c))^2})
非极大值抑制NMS
从所有检测框中找到Confidence最大的框,对剩余框与其计算IoU,如果IoU大于一定的阈值即重合度过高,则将该框剔除。
类别检测方法
- 对于 (S imes S imes B=7 imes7 imes2=98) 个 Bounding boxes,将Confidence 值小于某个阈值的Confidence 值归 (0)。
- 采用非极大值抑制NMS,重合度过高的框的Confidence 值归 (0)。
- 对于Confidence 不为(0)的box,确定其box的类别
优点
检测速度快( (S imes S imes B=7 imes7 imes2=98) 候选框较少)。
假阳性率低,误判的情况少。
能够学到更加抽象的物体的特征。
缺点
精度不高。
容易对物体定位错误。
每个格子只能预测2个物体,密集的小物体在一块不好预测。
2. YOLO v2 / YOLO 9000
论文 https://arxiv.org/abs/1612.08242
First we improve upon the base YOLO detection
system to produce YOLOv2, a state-of-the-art, real-time
detector. Then we use our dataset combination method
and joint training algorithm to train a model on more than
9000 classes from ImageNet as well as detection data from
COCO.
2.1 YOLO v2
数据集 ImageNet 在 finetune
主要创新:
- 使用 Batch Normalization 提高模型收敛速度,减少过拟合。在所有卷层都应用 Batch Normalization 使结果提升 2%。
- 在ImageNet上进行预训练时大部分模型使用(256 imes256),这里使用 (448 imes 448) 在ImageNet上进行预训练,在此预训练的网络基础上进行 finetune 使网络适应高分辨率输入有利于识别小物体,使得结果提升 4% mAP
- 不止使用两个 Bounding box,而是借鉴 Faster R-CNN 的 anchor 思想,使用多个 anchor boxes(经验值 5 个 anchor boxes),虽然准确率有小幅度下降,召回率提升了 7%,即找到了 YOLO v1 中找不到的物体。
- 使用 K-means 聚类方法对数据集标出的 Bounding box 框进行聚类,经验设定 (K=5),发现瘦高矩形框比较多,其次是扁宽的,正方的很少等现象,以此来选择 9 种 anchor boxes 中的 5 种进行训练,聚类选出的是IoU和效率比较好的平衡的结果。
- Bounding box 的预测值与Ground-truth 的差距可能会很大,会导致出现不能回归的情况,比如出现负数等情况,之前的方法是使用 (mathrm{log}) 让其为正进行限定方便运算。这里使用 sigmod: (f(z)=frac{1}{1+e^{−z}}),把((−infty,infty))映射到((0,1)) 使得 anchor boxes 的预测更稳定。
- 增加 passthrough 层,类似于 ResNet ((H(x)=F(x)+x)),将低分辨率与高分辨率特征结合,使 (26 imes26 imes512) 的特征图转化为 (13 imes13 imes2048)的特征图进而进行后续检测有利于小目标的检测。由小的物体不好检测,结合大一点特征图的特征信息能够弥补一定的相关特征信息,增加了 1% 的性能。
- 由于模型只包含卷积层和 pooling 层,可以改变图片的输入尺寸。在实验中,每经过 10 次训练,就会随机选择新的图片尺寸进行训练,可以对抗过拟合和适应不同的图片。
2.1.1 网络结构
设计 Darknet-19 共19层作为基础网络。网络结构里使用较多的 (3 imes 3)的卷积核。在每一次池化操作后把通道数翻倍。使用类似 ResNet 的结构用 (1 imes 1)进行降维压缩特征节省计算,同样用 (1 imes 1)进行升维。使用 Batch Normalization 稳定模型训练。
| Type | Filters | Size/Stride | ~ Output ~ |
|---|---|---|---|
| Convolutional | 32 | (3 imes 3) | (224 imes 224) |
| Maxpool | (2 imes 2 / 2) | (112 imes 112) | |
| Convolutional | 64 | (3 imes 3) | (112 imes 112) |
| Maxpool | (2 imes 2 / 2) | (56 imes 56) | |
| Convolutional | 128 | (3 imes 3) | (56 imes 56) |
| Convolutional | 64 | (1 imes 1) | (56 imes 56) |
| Convolutional | 128 | (3 imes 3) | (56 imes 56) |
| Maxpool | (2 imes 2 / 2) | (28 imes 28) | |
| Convolutional | 256 | (3 imes 3) | (28 imes 28) |
| Convolutional | 128 | (1 imes 1) | (28 imes 28) |
| Convolutional | 256 | (3 imes 3) | (28 imes 28) |
| Maxpool | (2 imes 2 / 2) | (14 imes 14) | |
| Convolutional | 512 | (3 imes 3) | (14 imes 14) |
| Convolutional | 256 | (1 imes 1) | (14 imes 14) |
| Convolutional | 512 | (3 imes 3) | (14 imes 14) |
| Convolutional | 256 | (1 imes 1) | (14 imes 14) |
| Convolutional | 512 | (3 imes 3) | (14 imes 14) |
| Maxpool | (2 imes 2 / 2) | (7 imes 7) | |
| Convolutional | 1024 | (3 imes 3) | (7 imes 7) |
| Convolutional | 512 | (1 imes 1) | (7 imes 7) |
| Convolutional | 1024 | (3 imes 3) | (7 imes 7) |
| Convolutional | 512 | (1 imes 1) | (7 imes 7) |
| Convolutional | 1024 | (3 imes 3) | (7 imes 7) |
| - | - | - | - |
| Convolutional | 1000 | (1 imes 1) | (7 imes 7) |
| Avgpool | Global | (1000) | |
| Softmax |
2.2 YOLO 9000
ImageNet 的数据标签来源于WordNet,具有一定的层次结构。作者根据 WordNet 综合 ImageNet 数据集 和 COCO 数据集 建立 WordTree,包含 9000 个分类。
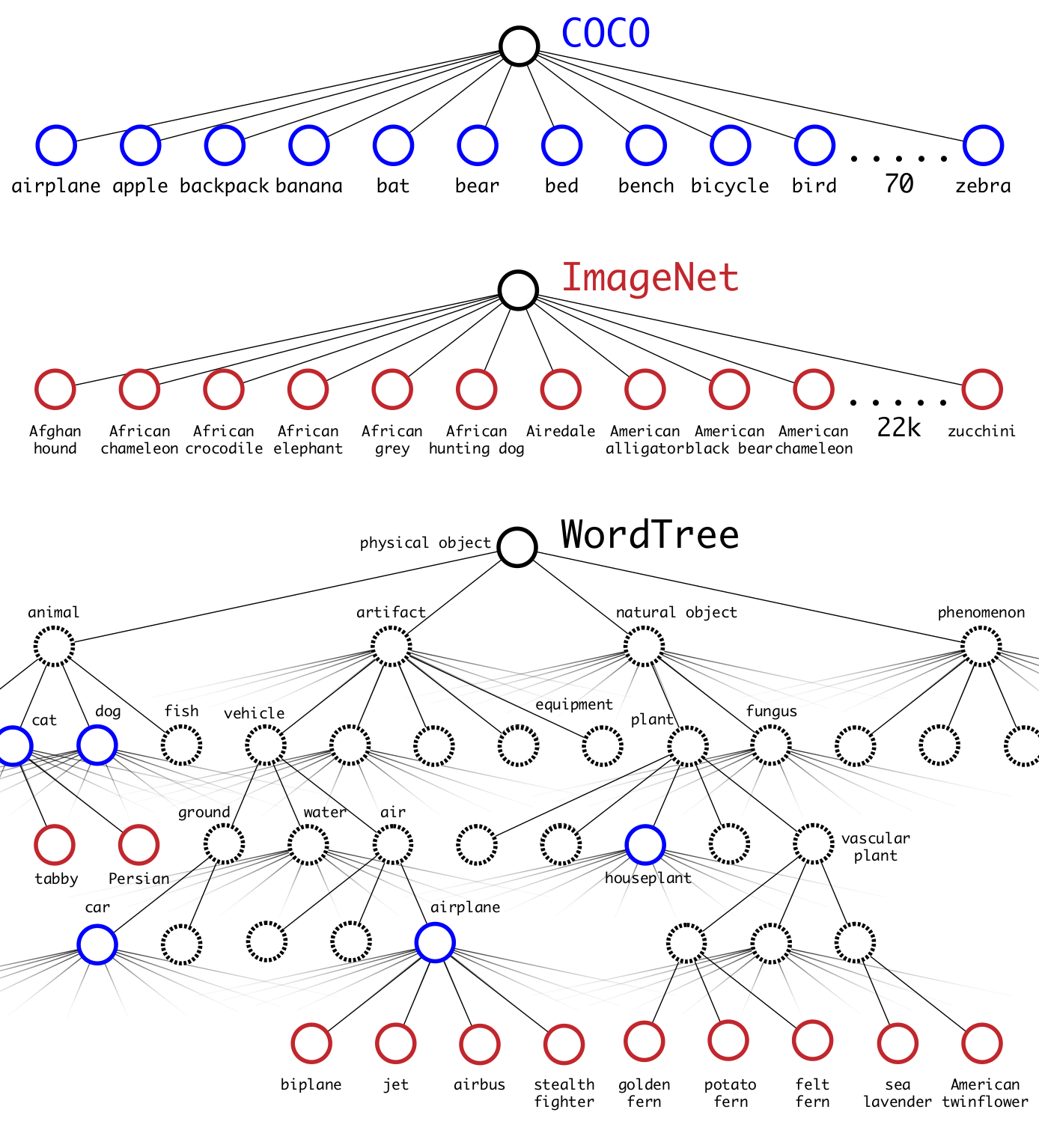
3. YOLO v3
论文 https://arxiv.org/abs/1804.02767
使用 DarkNet-53 的 53 层的基础网络(使用前52层,不使用全连接层),这个网络由残差单元叠加而成。
相较于 YOLO v2:
- 由于 Softmax 只能给出最大的, 所以使用 Logistic loss
- YOLO v2 使用 5 个 anchor boxes,YOLO v3 使用 3 个 考虑不同尺度的类似金字塔结构的 anchor boxes,相当于 (3 imes 3) 个 anchor boxes,映射到三个尺度的特征图上,每个特征图使用的是 3 个 anchor boxes,提高了 IoU
- YOLO v2 只有一个 Detection,YOLO v3 有 3 个 Detection
- 基础骨干网络使用 DarkNet-53,增加卷积层有利于提取更多深层次的信息,含有残差单元体现了一些 ResNet 的特性
3.1 网络结构
使用逻辑回归预测每个边界框的分类。为了实现多标签分类,不再使用 softmax 函数作为最终的分类器,而是使用 binary cross-enropy 作为损失函数。
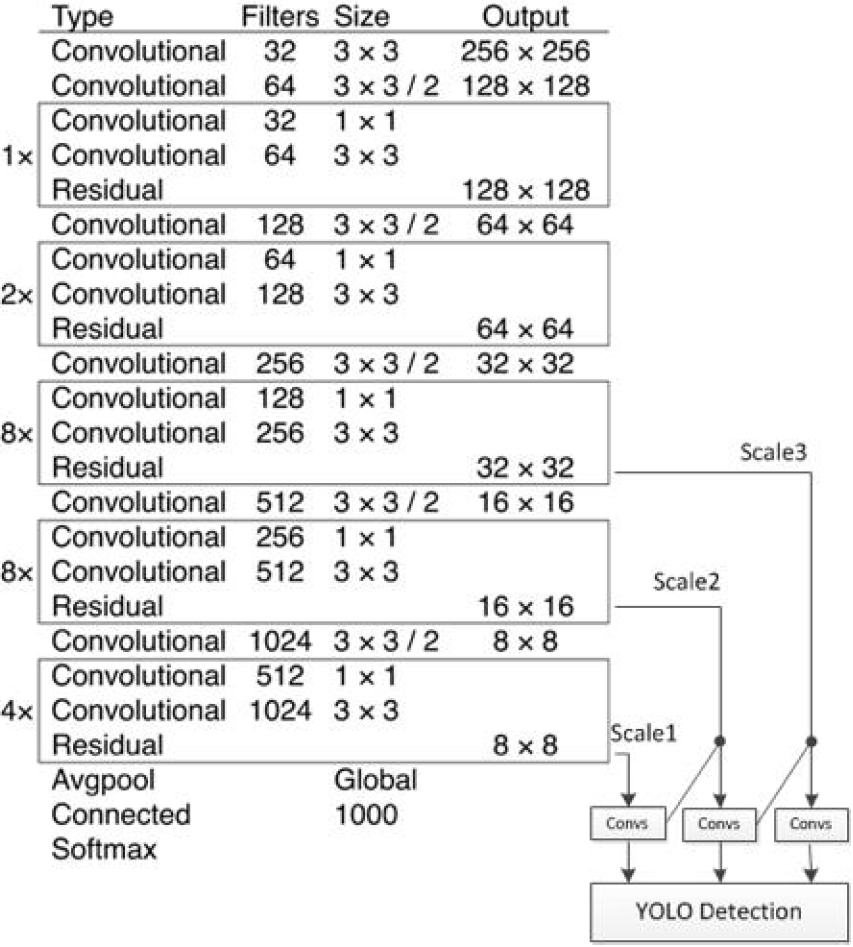
3.2 多尺度预测
- 在 DarkNet-53的特征图(第52层卷积层的输出)上,经过 7 Convs 卷积层得到第一个特征图 feature map,在这个特征图上做第一次预测,得到 Scale 1 尺度的预测,预测大尺度的物体。
- 在上一步的 7 Convs 卷积层 向前倒数第 3 个卷积层的输出进行一次 ( imes 2) 上采样,将上采样后的特征与DarkNet-53 的第 43 个卷积层的特征连接,经过 7 Convs 卷积层得到特征图,在这个特征图上做第二次预测,得到 Scale 2 尺度的预测,预测中尺度的物体。
- 在上一步的 7 Convs 卷积层向前倒数第 3 个卷积层的输出,进行一次卷积一次 ( imes2)上采样,得到的特征图与DarkNet-53 的第 26 个卷积特征图连接,再经过7 Convs 卷积层得到特征图,在这个特征图上做第三次预测,得到 Scale 3 尺度的预测,预测小尺度的物体。
优点
对于密集的人站在一起效果好
[1] https://programmersought.com/article/50663470669/
[2] YOLOv1论文理解 csdn
[3] 【YOLOv1】的那点事儿 csdn
[4] 一文看懂YOLO v3 csdn