为什么要生成分布式ID?
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。例如在游戏中,游戏数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,那业务系统对ID号的要求有哪些呢?
1)全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
2)趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
3)单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
4)信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
1、UUID
使用网卡地址、时间戳和随机数进行生成唯一ID,Java中就自带生成UUID的方法。
优点:本地即可生成,不需要网络开销
缺点:字符串占用内存,不自增,对数据库索引不友好,MySQL官方推荐不要使用
2、snowflake算法
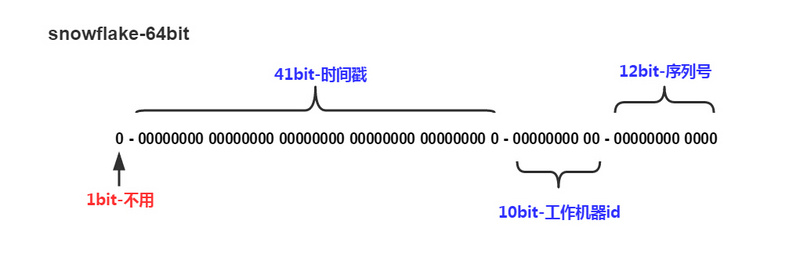
1位:保留位不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
41位:用来记录时间戳(毫秒),41位可以表示2^41−1个数字,(2^41−1)/(1000∗60∗60∗24∗365)=69年
10位:用来记录工作机器id
12位:序列号,用来记录同毫秒内产生的不同id
优点:存在自增趋势,只占用64位
缺点:强依赖机器时钟
3、Flicker公司的解决方案
使用MySQL的auto_increment自增特性来生成唯一ID。
创建优惠券表:
CREATE TABLE Discount ( id bigint(20) unsigned NOT NULL auto_increment, stub char(1) NOT NULL default '', PRIMARY KEY (id), UNIQUE KEY stub (stub) ) ENGINE=InnoDB
获取ID: 在一个事务中执行如下sql,replace和insert语句区别主要是replace在插入数据的时候,如果数据存在(通过主键和唯一索引来查找)则先删除,然后再进行插入。
START TRANSACTION;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
COMMIT;
上面这种方法只在单台MySQL上生成ID,从高可用角度考虑,接下来就要解决单点故障问题:可以启用两台数据库服务器来生成ID,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
DiscountServer1 // 优惠券服务1 auto-increment-increment = 2 // 自增值 auto-increment-offset = 1 // 起始值 DiscountServer2 // 优惠券服务2 auto-increment-increment = 2 // 自增 auto-increment-offset = 2 // 起始值
优点:充分借助数据库的自增ID机制,提供高可靠性,生成的ID有序。
缺点:强依赖数据库,占用两个独立的MySQL实例,有些浪费资源,成本较高,而且增删MySQL实例很复杂。
4、MongoDB的ObjectId
MongoDB中我们经常会接触到一个自动生成的字段:”_id”,类型为ObjectId。上面方法中用到了MySQL数据库时,主键都是设置成自增的。但在分布式环境下,这种方法就不可行了,会产生冲突。为此,MongoDB采用了一个称之为ObjectId的类型来做主键。ObjectId是一个12字节的 BSON 类型字符串。
4字节:UNIX时间戳 3字节:表示运行MongoDB的机器 2字节:表示生成此_id的进程 3字节:由一个随机数开始的计数器生成的值
前9个字节保证了同一秒不同机器不同进程产生的ObjectId的唯一性。后三个字节是一个自动增加的计数器(一个mongod进程需要一个全局的计数器),保证同一秒的ObjectId是唯一的。同一秒钟最多允许每个进程拥有(256^3 = 16777216)个不同的ObjectId。
优点:算法实现思路和snowflake类似,但是相比更消耗空间