相关文章:
关于Flume 的 一些核心概念:
| 组件名称 | 功能介绍 |
| Agent代理 | 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
| Client客户端 | 生产数据,运行在一个独立的线程。 |
| Source源 | 从Client收集数据,传递给Channel。 |
| Sink接收器 | 从Channel收集数据,进行相关操作,运行在一个独立线程。 |
| Channel通道 | 连接 sources 和 sinks ,这个有点像一个队列。 |
| Events事件 | 传输的基本数据负载。 |
文章和 大数据系列之Flume+HDFS 非常相似,不同的在于flume安装目录conf下新建了kafka.properties文件,启动时也应当用此配置文件作为参数启动。下面看具体内容:
1. kafka.properties:
agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /tmp/logs/kafka.log
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100
#设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=master:9092
#设置Kafka的Topic
agent.sinks.k1.topic=kafkatest
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder
agent.sinks.k1.channel=c1
关于配置文件中注意3点:
a. agent.sources.s1.command=tail -F /tmp/logs/kafka.log
b. agent.sinks.k1.brokerList=master:9092
c . agent.sinks.k1.topic=kafkatest
2.很明显,由配置文件可以了解到:
a.我们需要在/tmp/logs下建一个kafka.log的文件,且向文件中输出内容(下面会说到);
b.flume连接到kafka的地址是 master:9092,注意不要配置出错了;
c.flume会将采集后的内容输出到Kafka topic 为kafkatest上,所以我们启动zk,kafka后需要打开一个终端消费topic kafkatest的内容。这样就可以看到flume与kafka之间玩起来了~~
3.具体操作:
a.在/tmp/logs下建立空文件kafka.log。在mfz 用户目录下新建脚本kafkaoutput.sh(一定要给予可执行权限),用来向kafka.log输入内容: kafka_test***
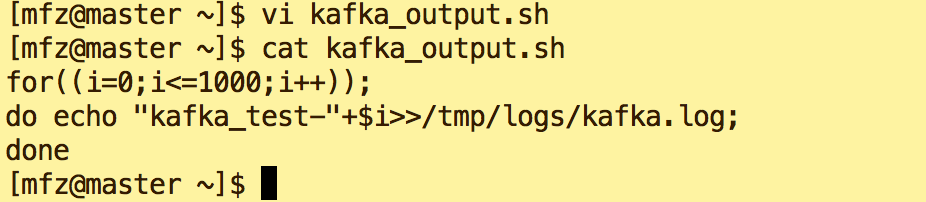
for((i=0;i<=1000;i++)); do echo "kafka_test-"+$i>>/tmp/logs/kafka.log; done
b. 在kafka安装目录下执行如下命令,启动zk,kafka 。(不明白此处可参照 大数据系列之Flume+HDFS)
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties &
bin/kafka-server-start.sh -daemon config/server.properties &
c.新增Topic kafkatest
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatest
d.打开新终端,在kafka安装目录下执行如下命令,生成对topic kafkatest 的消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafkatest --from-beginning --zookeeper master
e.启动flume
bin/flume-ng agent --conf-file conf/kafka.properties -c conf/ --name agent -Dflume.root.logger=DEBUG,console
d.执行kafkaoutput.sh脚本(注意观察kafka.log内容及消费终端接收到的内容)
![]()
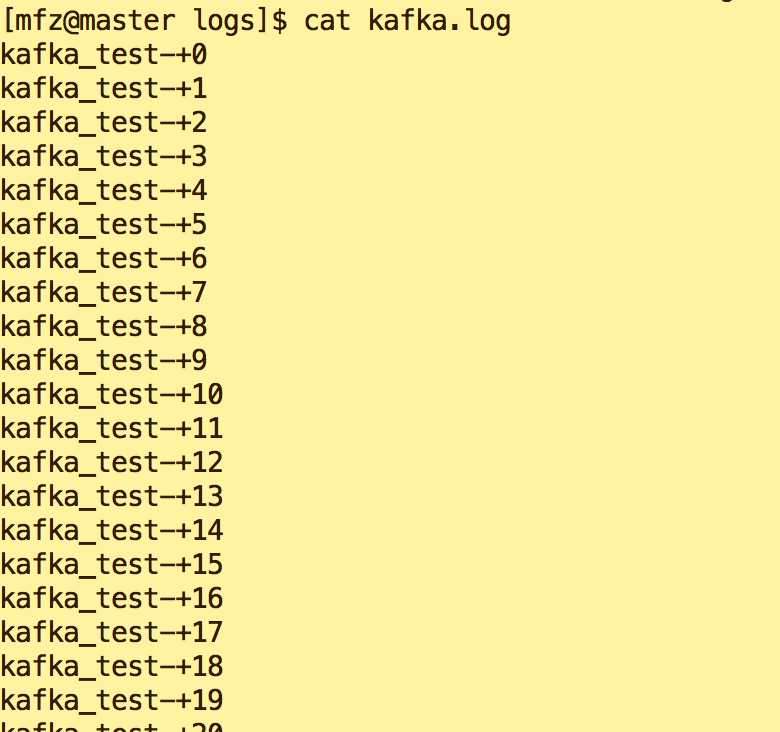
e.查看新终端消费信息
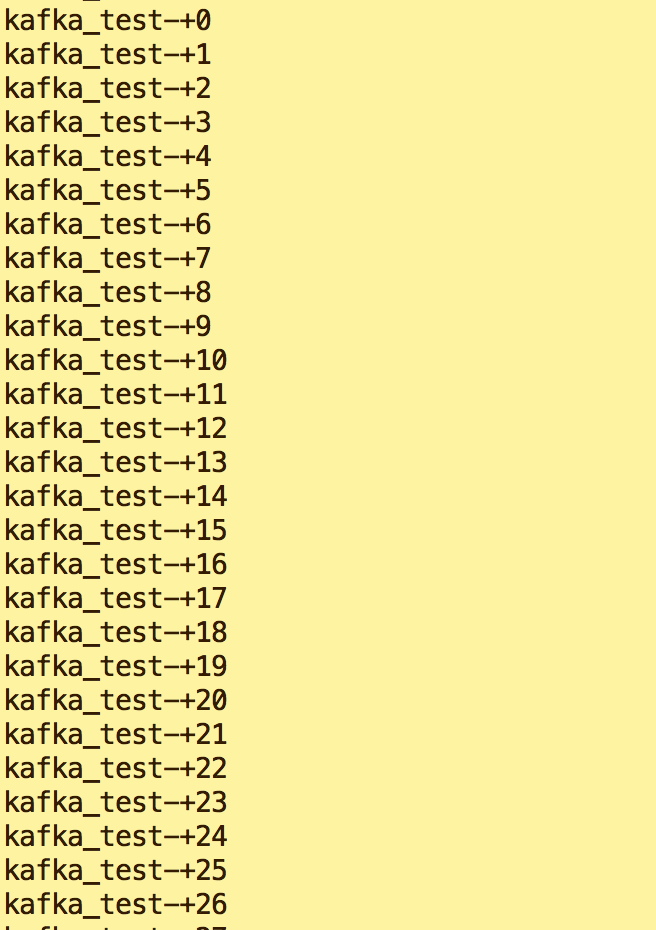
整体流程如图:
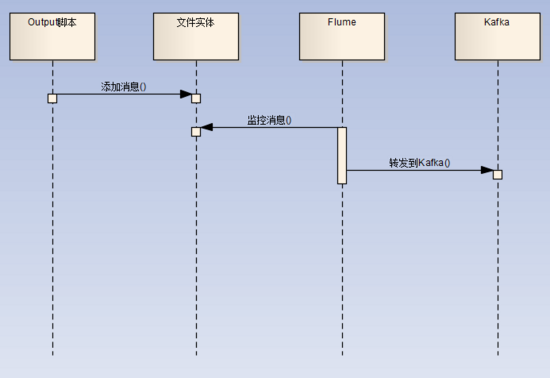
完~~
后续将介绍Java代码对于Flume+HDFS ,Flume+Kafka的实现。敬请期待~