注:本文是人工智能研究网的学习笔记
标称型特征编码(Encoding categorical feature)
有些情况下,某些特征的取值不是连续的数值,而是离散的标称变量(categorical)。
比如一个人的特征描述可能是下面的或几种:
features ['male', 'female'], ['from Europe', 'from US', 'from Asia'], ['use Firefox', 'use Chorme', 'use Safari', 'Use IE']。
这样的特征可以被有效的编码为整型特征值(interger number)。
['male', 'US', 'use IE'] -->> [0,1,3]
['femel', 'Asia', 'use Chrome'] -->> [1,2,1]
但是这些整数型的特征向量是无法直接被sklearn的学习器使用的,因为学习器希望输入的是连续变化的量或者可以比较大小的量,但是上述特征里面的数字大小的比较是没有意义的。
一种变换标称型特征(categorical features)的方法是使用one-of-K或者叫one-hot encoding,在类OneHotEncoder里面就已经实现了。这个编码器将每一个标称型特征编码成一个m维二值特征,其中每一个样本特征向量就只有一个位置是1,其余位置全是0。
enc = preprocessing.OneHotEncoder()
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])
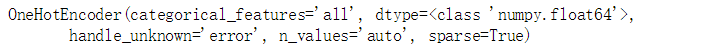
enc.transform([[0,1,3]]).toarray()
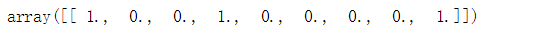
第一列的取值有两个,使用两个数字编码;第二列取值有单个,使用三个数字编码;第三列取值有4个,使用四个数字编码。一共使用九个数字进行编码。
默认情况下,每个特征分量需要多少个值是从数据集中自动推断出来的。我们还可以通过参数n_values进行显式的指定。上面的数据集中,有两个性别,三个可能的地方以及四个浏览器。然后fit之后在对每一个样本进行变换。结果显示,前两个值编码了性别,接下来的三个值编码了地方,最后的四个值编码了浏览器。
注意:如果训练数据中某个标称型特征分量的取值没有完全覆盖其所有可能的情况,则必须给OneHotEncoder指定每一个标称型特征分量的取值个数,设置参数:n_values。
enc = preprocessing.OneHotEncoder(n_values=[2,3,4])
enc.fit([[1,2,3],[0,2,0]])

enc.transform([[1,0,0]]).toarray()
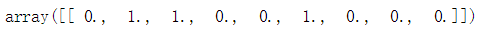
缺失值处理(Imputation of missing values)
由于各种各样的原因,很多真实世界中的数据集包含有缺失值,通常使用blanks,NaNs or other placeholders来代替。这样的数据集是无法直接被sklearn的学习器模型处理的。
一个解决的办法是将包含缺失值得整行或者整列直接丢弃。然而这样可能会丢失很多有价值的数据。
一个更好的办法是补全缺失值,也就是从已知的部分数据推断出未知的数据。
Imputer类提供了补全缺失值得基本策略: 使用一行或者一列的均值,中值,出现次数最多的值来补全,该类也允许不同缺失值得编码。
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit([[1,2], [np.nan,3], [7,6]])
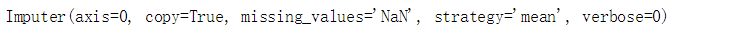
X = [[np.nan,2], [6, np.nan], [7,6]]
imp.transform(X)
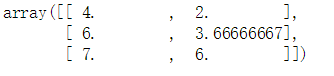
使用训练得数据来进行补全。
Imputer类支持稀疏矩阵:
import scipy.sparse as sp
X = sp.csc_matrix([[1,2], [0,3], [7,6]])
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit(X)
X_test = sp.csc_matrix([[0,2], [6,0], [7,6]])
imp.transform(X_test)

多项式特征(Generating polynominal features)
为输入数据添加非线性特征可以增加模型的复杂度,实现这一点的常用的简单方法是使用多项式特征(polynominal features),他可以引入特征的高阶项和互乘积项。
sklearn的PolynominalFeatures类可以用来在出入数据的基础上构造多项式特征。
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6).reshape(3,2)
poly = PolynomialFeatures(2) # 二阶
poly.fit_transform(X)
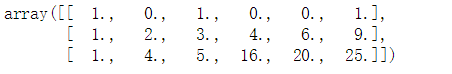

有些情况下,我们只想要原始输入特征分量之间的互乘积项,这时可以设置参数:interaction_only=True,这时将不会出现次方项。
自定义转换器(Custom transformers)
有时候,你需要把一个已经有的Python函数变为一个变换器transformer来进行数据的清理和预处理。
借助于FunctionTransformer类,你可以从任意的Python函数实现一个transformer。比如,构造一个transformer实现对数变换。
from sklearn.preprocessing import FunctionTransformer
transformer = FunctionTransformer(np.log1p)
X = np.array([[0,1], [2,3]])
transformer.transform(X
