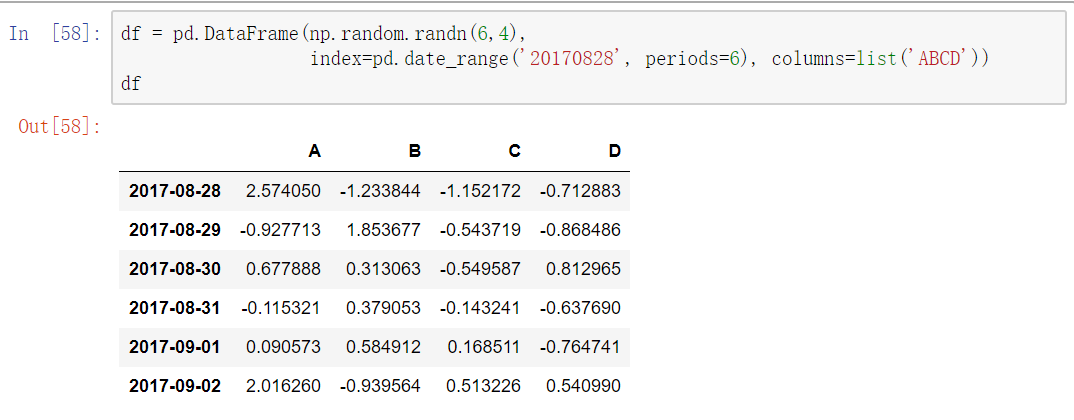
首先创建一组数据
非交叉选取
下面的这种方法只能单独的选取行或者列,即只能操作某一个轴的数据,不能实现交叉。
-
选取单独列
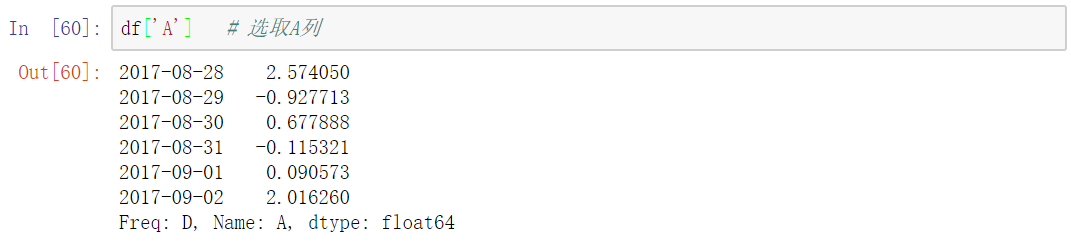
选取的数据我们用type来查看类型发现是Series -
选取某指定的几列

值得注意的是,使用这种方法并不能实现对列的切片,比如df[['A':'C']] -
选取某一行

使用这种方法,即使你要选择的仅仅是某一行,也需要使用切片的方法来实现,因为非切片的方法默认选取的是列。 -
选取某几行
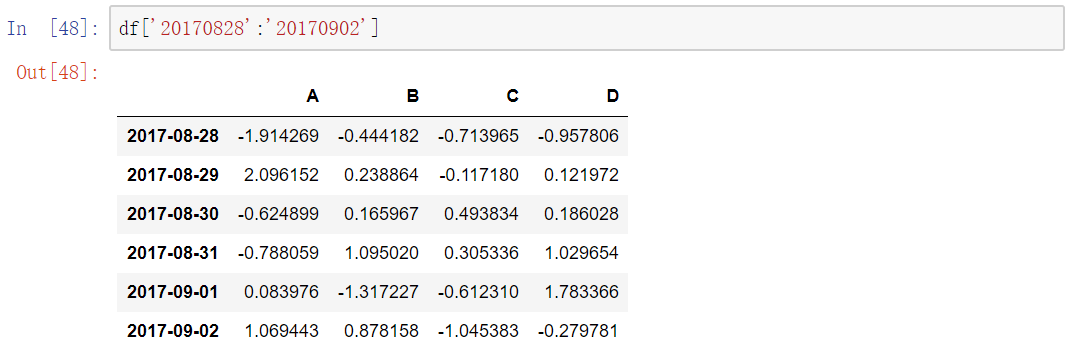
同样是使用切片的方法来实现选取某几行
通过标签的交叉选取
下面的这种方法可以同时选择行和列,自然也是可以单独选取。
-
单独选取某一行

-
只对行切片

-
交叉选取
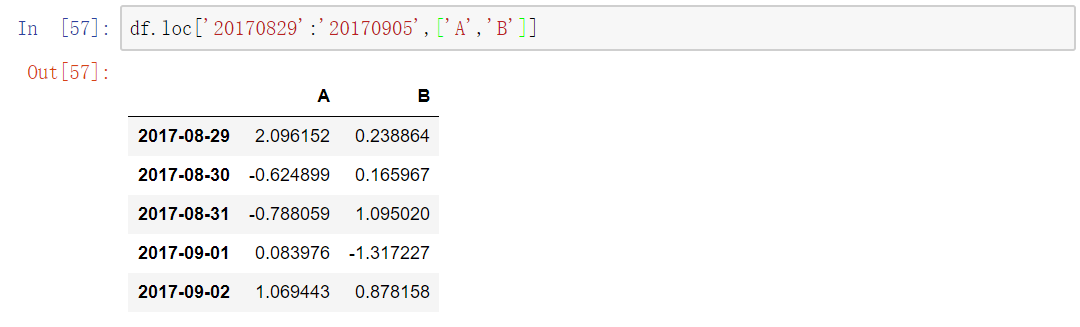


看的出来,使用loc[]的方法非常的灵活,既可以使用索引进行选取,又可以使用切片,可是同时实现对0/1轴的交叉选取,事实上,上面的单独对行的操作其实默认已经选取了全部的列。只是我们把针对列的操作省略了,因为默认已经选择了所有列。
通过位置的交叉索引
下面的这种方法也是实现交叉索引,与上面的区别在于,iloc[]的方法,只能使用自动索引,所谓的自动索引,就是无论你有没有创建一套你个性化的索引,pandas都会自动创建一套索引,这套索引是数字型的,拿下面的数据来说,你看到了我们的0轴索引是日期,1轴索引是ABCD,但是事实上,pandas还有一套索引,如下图所示,这个默认存在的。

至于操作和loc[]方法是一样的,区别仅仅在于把属于你的那一套索引换成pandas的索引。