之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来。 但是,像比如一些购物网站,他们的商品信息都是js加载出来的,并且会有ajax异步加载。像这样的情况,直接使用scrapy的Request请求是拿不到我们想要的信息的,解决的方法就是使用scrapy-splash。
scrapy-splash加载js数据是基于Splash来实现的,Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT,而我们使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后,拿到的渲染之后的网页源代码。
准备环节
-
安装docker
在windows环境下,安装docker简便的方法是使用docker toolbox,由于Docker引擎的守护进程使用的是Linux的内核,所以我们不能够直接在windows中运行docker引擎。而是需要在你的机器上创建和获得一个Linux虚拟机,用这个虚拟机才可以在你的windows系统上运行Docker引擎,docker toolbox这个工具包里面集成了windows环境下运行docker必要的工具,当然也包括虚拟机了。
首先下载docker toolbox
执行安装程序,默认情况下,你的计算机会安装以下几个程序- Windows版的Docker客户端
- Docker Toolbox管理工具和ISO镜像
- Oracle VM 虚拟机
- Git 工具
当然,如果你之前已经安装过了Oracle VM 虚拟机 或者 Git 工具 ,那么你在安装的时候可以取消勾选这两个内容,之后,你只需要狂点下一步即可。安装完毕以后,找到Docker Quickstart Terminal图标,双击运行,稍等它自己配置一小段时间,你会看到以下的界面
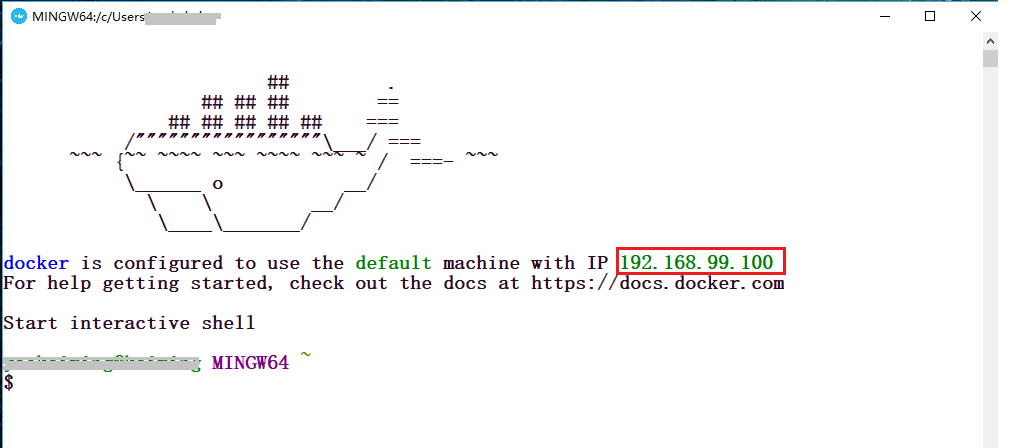
请注意上面画红框的地方,这是默认分配给你的ip,下面会用到。至此,docker工具就已经安装好了。 -
安装Splash
双击运行Docker Quickstart Terminal,输入以下内容
docker pull scrapinghub/splash
这个命令是拉取Splash镜像,等待一算时间,就可以了。下面就是启动Splash
docker run -p 8050:8050 scrapinghub/splash
这个命令就是在计算机的8050端口启动Splash渲染服务
你会看到以下的图示内容。
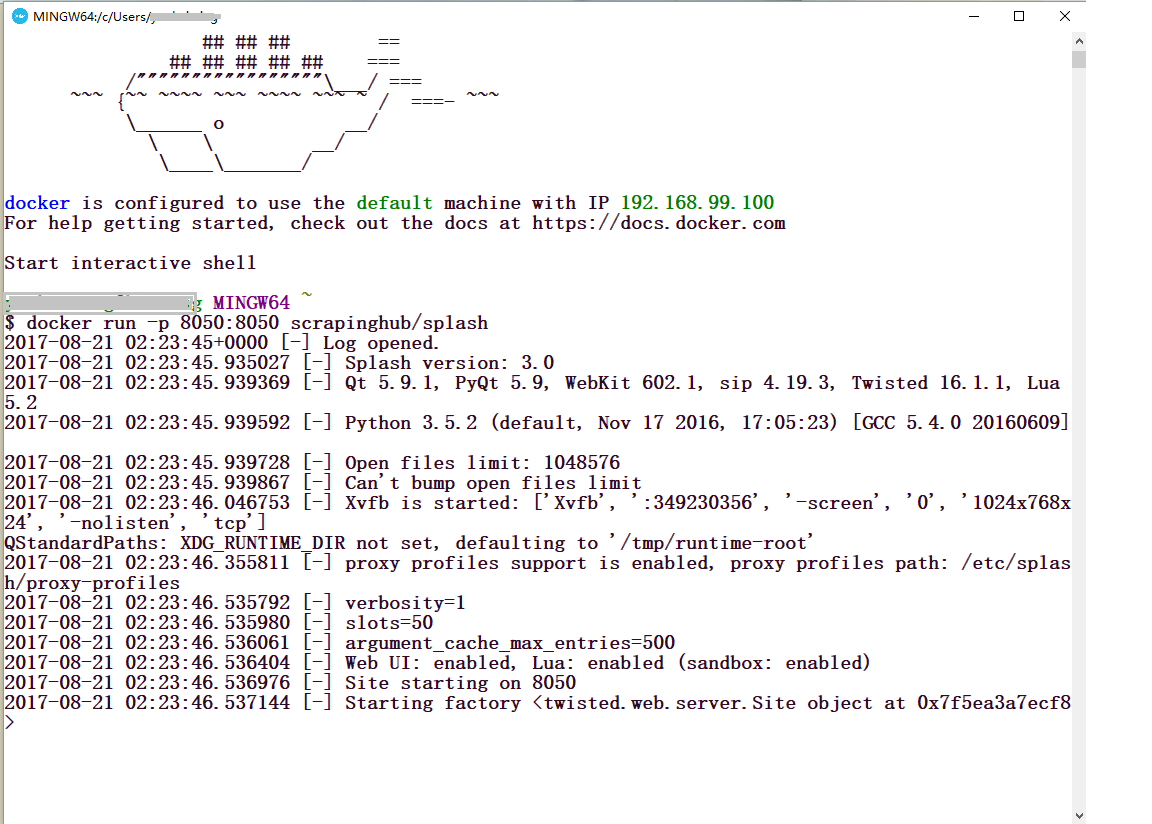
这个时候,打开你的浏览器,输入
192.168.99.100:8050你会看到出现了这样的界面。
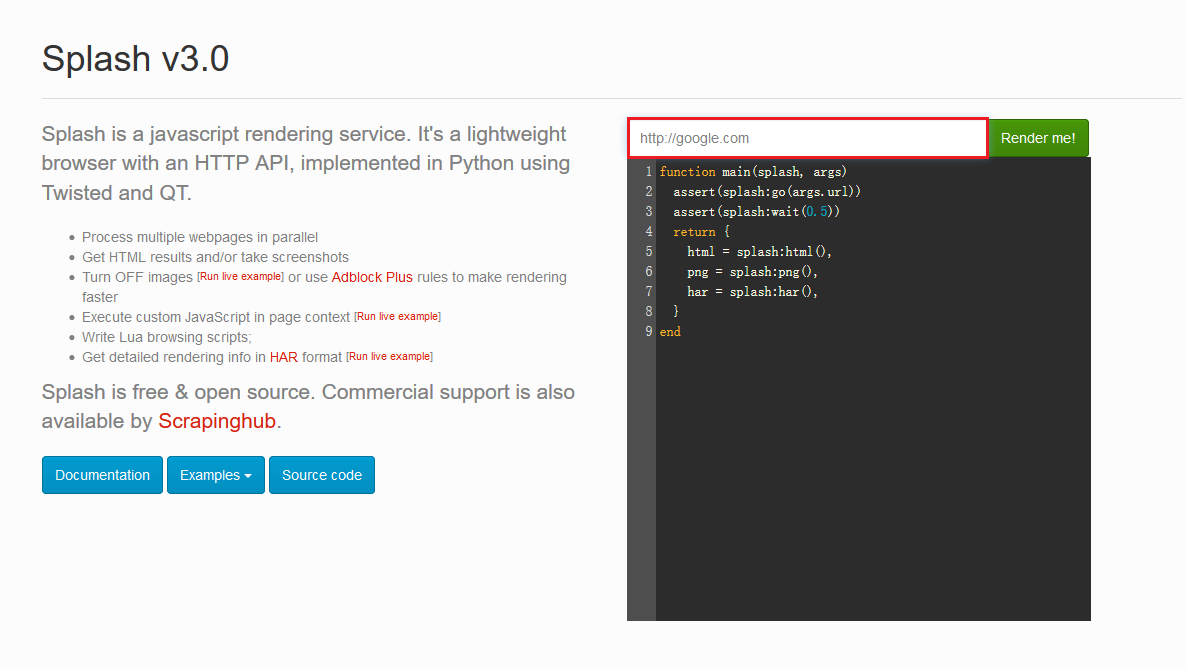
你可以在上图红色框框的地方输入任意的网址,点击后面的Render me! 来查看渲染之后的样子。 -
安装scrapy-splash
pip install scrapy-splash至此,我们的准备环节已经全部结束了。
测试
下面我们就创建一个项目来测试一下,是否真的实现了我们想要的功能。
不使用scrapy-splash
为了有一个直观的对比,我们首先不使用scrapy- splash,来看一下是什么效果,我们以淘宝商品信息为例,新建一个名为taobao的项目,在spider.py文件里面输入下面的内容。
import scrapy
class Spider(scrapy.Spider):
name = 'taobao'
allowed_domains = []
start_urls = ['https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self,response):
titele = response.xpath('//div[@class="row row-2 title"]/a/text()').extract()
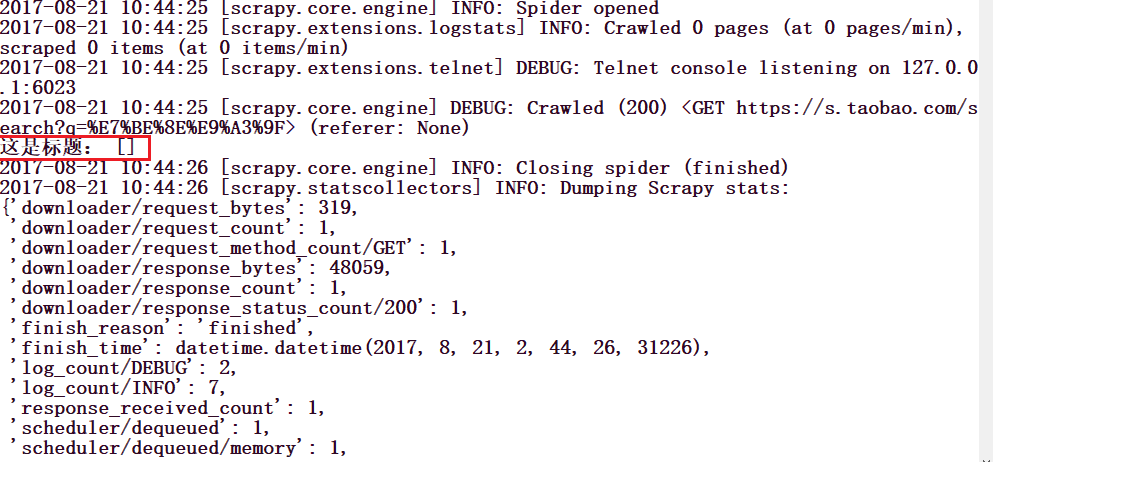
print('这是标题:', titele)
我们打印出淘宝美食的名称,你会看到这样的信息:
使用scrapy-splash
下面我们使用scrapy-splash来实现一下,看一下会出现什么样的效果:
使用scrapy-splash需要一些额外的配置,下面一一列举:
在settings.py文件中,你需要额外的填写下面的一些内容
# 渲染服务的url
SPLASH_URL = 'http://192.168.99.100:8050'
#下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
在spider.py文件中,填入下面的代码:
import scrapy
from scrapy_splash import SplashRequest
class Spider(scrapy.Spider):
name = 'taobao'
allowed_domains = []
start_urls = ['https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse,
args={'wait':1}, endpoint='render.html')
def parse(self, response):
titele = response.xpath('//div[@class="row row-2 title"]/a/text()').extract()
print('这是标题:', titele)
记住不要忘记导入SplashRequest。
下面就是运行这个项目,记得在docker里面先把splash渲染服务运行起来。
结果如下图所示。

看的出来,我们需要的内容已经打印出来了,内容有点乱,我们可以使用正则来进行匹配,但是这已经不是我们这一小节的主要内容了,你可以自己尝试一下。