一、前言
正则表达式(英语为 Regular Expression,在代码中常简写为 regex、regexp 或 RE),是使用单个字符串来描述或匹配一系列符合某个句法规则的字符串。许多工具和程序设计语言都支持利用正则表达式进行字符串操作,在 Linux 中,常用的 grep、sed 和 awk 等命令,也都支持正则表达式。
Linux 中正则表达式和通配符的区别:正则表达式用来找文件内容、文本和字符串等,一般只有 grep、sed 和 awk 支持,这三个命令也通常被称为 Linux 文本处理三剑客;而通配符用来找文件名,普通命令都支持,通配符主要有星号(*)和问号(?),星号代表零个或多个任意字符,问号只代表一个任意的字符。
此外,对于 grep 命令而言,又可分为:
grep 是很常见也很常用的命令,它的主要功能是进行字符串数据的比较,然后符合用户需求的字符串打印出来。但是注意,grep 在数据中查找一个字符串时,是以 "整行" 为单位进行数据筛选的。
egrep 命令等同于 grep -E,利用此命令可以使用扩展的正则表达式对文本进行搜索,并把符合用户需求的字符串打印出来。
fgrep 命令等同于 grep -F,它利用固定的字符串来对文本进行搜索,但不支持正则表达式的引用,所以此命令的执行速度也最快。
二、正则表达式分类
Linux 正则表达式一般分为 BRE(Basic Regular Expression) 和 ERE(Extended Regular Expression)。前者为基本正则表达式,后者为扩展正则表达式。他们都遵循 POSIX 规范,POSIX 指的是可移植操作系统接口。ERE 是 BRE 的扩展版本,具有更强的处理能力,并且增加了一些元字符(metacharactor)。Linux 的 grep 默认使用 BRE,可以通过 egrep 或者 grep -E 来开启使用 ERE。Linux 的 sed 使用 BRE 中的一个子集,主要是为了保证处理的速度和效率。BRE 与 ERE 在能力上区别仅在多项匹配的能力上,其他方面没有大的差别,主要的区别体现在元字符上。
比如:
BRE(基础正则表达式)只认识的元字符有 ^$.[]*,其他字符识别为普通字符,如 "()",要使用此功能必须加 "" 进行转义,即 "()";
ERE(扩展正则表达式)则添加了 (){}?+| 等元字符;
只有在用反斜杠 "" 进行转义的情况下,字符 (){} 才会在BRE被当作元字符处理,而ERE中,任何元符号前面加上反斜杠反而会使其被当作普通字符来处理。
三、BRE 基本正则表达式
3.1 元字符 ^
比如 ^word ,表示搜索以 word 开头的内容,即此字符后面的任意内容必须出现在行首
[root@ryan linux]# cat -n test2
1 bob:26:shanxi:138912:linux
2
3 ryan:28:china:23124:java
4 adam:30:xinjiang:123123:python
5
6 emily:20:beijing:35345:scala
7 ada:16:shengjiang:123321:rubby
[root@ryan linux]# grep ^ad test2
adam:30:xinjiang:123123:python
ada:16:shengjiang:123321:rubby
3.2 元字符 $
比如 word$ 搜索以 word 结尾的内容,即此字符前面的任意内容必须出现在行尾
[root@ryan linux]# grep a$ test2
ryan:28:china:23124:java
emily:20:beijing:35345:scala
3.3 表达式 ^$
^$ 表示空行,不是空格
[root@ryan linux]# grep -n ^$ test2
2:
5:
第 2 行和第 5 行都是空行。
3.4 元字符 .
. 代表且只能代表任意一个字符(不匹配空行)
[root@ryan linux]# grep -n "." test2
1:bob:26:shanxi:138912:linux
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
[root@ryan linux]# grep -n ".y" test2
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
3.5 转义字符
转义字符,让有特殊含义的字符脱掉马甲,现出原形,如 .只表示小数点
[root@ryan linux]# cat -n test2
1 bob:26:shanxi:138912:linux
2
3 ryan:28:china:23124:java
4 adam:30:xinjiang:123123:python
5
6 emily:20:beijing:35345:scala
7 ada:16:shengjiang:123321:rubby
8 jim.green:18:shandong:123321:rubby
9 tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep "." test2
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep ".g" test2
jim.green:18:shandong:123321:rubby
3.6 元字符 *
重复之前的字符或文本0个或多个,之前的文本或字符连续0次或多次,即匹配其前面的字符任意次
[root@ryan linux]# grep "e*" test2
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
adam:30:xinjiang:123123:python
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
* 匹配前一个字符0个或多个,假如匹配0个的时候,实际上就等于空,什么都没有。什么都没有的情况下就默认匹配文件的全部内容,然后再匹配大于0的情况。
3.7 表达式 .*
.* 匹配任意多个字符
[root@ryan linux]# grep -n ".*" test2
1:bob:26:shanxi:138912:linux
2:
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
5:
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
3.8 表达式 ^.*
^.* 以任意多个字符串开头
[root@ryan linux]# grep -n "^.*" test2
1:bob:26:shanxi:138912:linux
2:
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
5:
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep -n "^.*a" test2
1:bob:26:shanxi:138912:linux
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
3.9 括号表达式 [ ]
[abc][0-9][.,/],匹配字符集合内的任意一个字符 a 或 b 或 c:[a-z] 匹配所有小写字母;表示一个整体,内藏无限可能;[abc] 找 a 或 b 或 c 可以写成 [a-c]
[root@ryan linux]# grep -n "[abc]" test2
1:bob:26:shanxi:138912:linux
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep -n "[0-9]" test2
1:bob:26:shanxi:138912:linux
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep -n "[.,/]" test2
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
[root@ryan linux]# cat -n test2
1 bob:26:shanxi:138912:linux
2
3 ryan:28:china:23124:java
4 adam:30:xinjiang:123123:python
5
6 emily:20:beijing:35345:scala
7 ada:16:shengjiang:123321:rubby
8 jim.green:18:shandong:123321:rubby
9 tom:16:hebei:123321:ru.bby
10 http://www.baidu.com/musicdocument,mp3
[root@ryan linux]# grep -n "[.,/]" test2
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
10:http://www.baidu.com/musicdocument,mp3
3.10 表达式 [^abc]
匹配不包含 ^ 后的任意字符 a 或 b 或 c,是对 [abc] 的取反,且与 ^ 含义不同
[root@ryan linux]# grep -n "[^abc]" test2
1:bob:26:shanxi:138912:linux
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
10:http://www.baidu.com/musicdocument,mp3
[root@ryan linux]# grep -n "^[abc]" test2
1:bob:26:shanxi:138912:linux
4:adam:30:xinjiang:123123:python
7:ada:16:shengjiang:123321:rubby
[^abc] 匹配不包含 a、b 或 c 的字符串,而 ^[abc] 匹配以 a、b 或 c 开头的行。
注意:我发现 "^" 这个字符在中括号 "[ ]" 中被使用的话就表示字符类的否定,如果不是的话就是表示限定开头。我这里说的是直接在"[ ]" 中使用,不包括嵌套使用。其实也就是说 "[ ]" 代表的是一个字符集,"^" 只有在字符集中才是反向字符集的意思。
3.11 a{m,n}
重复前面 a 字符 m 到 n 次,即匹配其前面的字符至少 m 次,至多 n 次(如果用 egrep 或 sed -r 可去掉转义字符反斜杠 "")
[root@ryan linux]# grep -n "w{1,3}" test2
直接运行之后,grep 匹配不到字符,说明 grep 默认不支持大括号匹配,可以添加参数 -E,表明使用扩展正则表达式,如下:
[root@ryan linux]# grep -nE "w{1,3}" test2
10:http://www.baidu.com/musicdocument,mp3
或者使用转义字符,如下:
[root@ryan linux]# grep -n "w{1,3}" test2
10:http://www.baidu.com/musicdocument,mp3
a{m,} 重复前面 a 字符至少 m 次,如果用 egrep 或 sed -r 可去掉转义字符反斜杠 "";
a{m} 重复前面 a 字符 m 次,如果用 egrep 或 sed -r 可去掉转义字符反斜杠 "";
注意:
1) ^ 字符是否在 [ ] 中,作用是不同的;
2) * 字符在正则表达式中的作用与其充当通配符时的作用不同;
3) ! 字符在正则表达式中并不是特殊字符;
四、ERE 扩展正则表达式
grep 默认不支持扩展正则元符号,因此扩展正则表达式的符号对于 grep 来说就等同于普通字符含义,因此,想让 grep 直接处理正则符号可以通过转义字符 {} 来处理,或使用 grep -E 强制让 grep 直接认识扩展正则元符号,不需要再进行转义。 egrep 等效于 grep -E,直接支持扩展正则元符号。sed 通过使用 sed -r 支持扩展正则元符号。
4.1 元字符 +
重复前一个字符一次或一次以上,前一个字符连续一个或多个,把连续的文本或字符取出
[root@ryan linux]# grep -nE "e+" test2
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
10:http://www.baidu.com/musicdocument,mp3
4.2 元字符 ?
重复前面一个字符0次或1次(.是有且只有1个)
[root@ryan linux]# grep -nE "e?" test2
1:bob:26:shanxi:138912:linux
2:
3:ryan:28:china:23124:java
4:adam:30:xinjiang:123123:python
5:
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
10:http://www.baidu.com/musicdocument,mp3
[root@ryan linux]# grep -nE "e." test2
6:emily:20:beijing:35345:scala
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
10:http://www.baidu.com/musicdocument,mp3
4.3 管道符 |
| 表示或者同时过滤多个字符
[root@ryan linux]# grep -n "138|912|123" test2
[root@ryan linux]# grep -n "138|912|123" test2
1:bob:26:shanxi:138912:linux
4:adam:30:xinjiang:123123:python
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
[root@ryan linux]# grep -nE "138|912|123" test2
1:bob:26:shanxi:138912:linux
4:adam:30:xinjiang:123123:python
7:ada:16:shengjiang:123321:rubby
8:jim.green:18:shandong:123321:rubby
9:tom:16:hebei:123321:ru.bby
4.4 元字符 ( )
() 分组过滤被括起来的东西表示一个整体 (一个字符),后向引用
[root@ryan linux]# grep -nE "(xin|sheng)jiang" test2
4:adam:30:xinjiang:123123:python
7:ada:16:shengjiang:123321:rubby
等效于 AB + AC = A(B +C)
五、补充
5.1 预定义的正则表达式
只有 ERE 才支持:

5.2 其他元字符
BRE 已经支持:
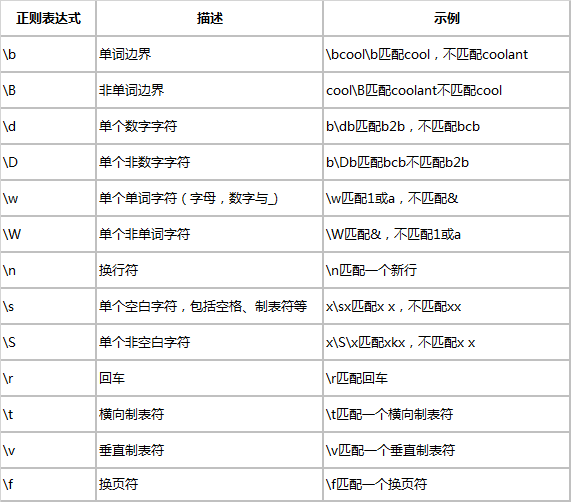
正则表达式只有多加练习,才能很好的融会贯通,配合 grep,egrep,sed -r,awk 等工具。
六、sed 工具的使用
虽然 grep 已经有很强大的功能了,但是只能实现查找功能,而不能实现替换等操作。sed 是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作,下面先了解一下 sed 的用法。
格式:sed [-nefri] 'command' 文本
常用选项:
-n∶使用安静 (silent )模式。在一般 sed 的用法中,所有来自 STDIN 的资料一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来;
-e∶直接在指令列模式上进行 sed 的动作编辑;
-f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
-r∶使 sed 的动作支持 ERE 的语法,预设是 BRE 语法;
-i∶直接修改读取的档案内容,而不是由屏幕输出;
常用命令:
a∶新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行);
c∶取代,c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行;
d∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i∶插入,i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作;
s∶取代,可以直接进行取代的工作,通常这个 s 的动作可以搭配正则表达式,例如 1,20s/old/new/g 就是;
6.1 打印某行
打印第2行,如下:
[root@ryan linux]# cat -n test3.txt
1 bob:26:shanxi:138912:linux
2 ryan:28:china:23124:java
3 adam:30:xinjiang:123123:python
4 emily:20:beijing:35345:scala
5 ada:16:shengjiang:123321:rubby
6 jim.green:18:shandong:123321:rubby
7 tom:16:hebei:123321:ru.bby
8 http://www.baidu.com/musicdocument,mp3
9 The negotiation went well and they finally reached an agreement.
[root@ryan linux]# sed -n '2'p test3.txt
ryan:28:china:23124:java
打印所有行,如下:
[root@ryan linux]# sed -n '1,$'p test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
adam:30:xinjiang:123123:python
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
打印指定区间的行,如下:
[root@ryan linux]# sed -n '2,5'p test3.txt
ryan:28:china:23124:java
adam:30:xinjiang:123123:python
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
6.2 打印包含某个字符串的行
[root@ryan linux]# sed -n '/adam/'p test3.txt
adam:30:xinjiang:123123:python
也可使用 ^、$、.、*等元字符,如下:
[root@ryan linux]# sed -n '/ad./'p test3.txt
adam:30:xinjiang:123123:python
ada:16:shengjiang:123321:rubby
6.3 删除某行或多行
单个数字表示删除某行,删除1到3行,如下:
[root@ryan linux]# sed '1,3'd test3.txt
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
删除匹配到的行,如下:
[root@ryan linux]# sed '/ad./'d test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
emily:20:beijing:35345:scala
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
6.4 替换字符或字符串
格式:sed 's/要替换的字符串/新的字符串/g' (要替换的字符串可以用正则表达式)
[root@ryan linux]# sed '1,3s/ada/robot/g' test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
robotm:30:xinjiang:123123:python
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
[root@ryan linux]# sed '/ad./s/ada/robot/g' test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
robotm:30:xinjiang:123123:python
emily:20:beijing:35345:scala
robot:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
参数 g 表示本行全局替换,如果不加 g 则只替换本行出现的第一个。除了可以使用 / 作为分隔符外,我们还可以使用其他特殊字符,例如 # 和 @
[root@ryan linux]# sed '/ad./s#ada#robot#g' test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
robotm:30:xinjiang:123123:python
emily:20:beijing:35345:scala
robot:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
也可以替换文档中所有的数字或者字母,如下:
[root@ryan linux]# sed 's/[0-9]//g' test3.txt
bob::shanxi::linux
ryan::china::java
adam::xinjiang::python
emily::beijing::scala
ada::shengjiang::rubby
jim.green::shandong::rubby
tom::hebei::ru.bby
http://www.baidu.com/musicdocument,mp
The negotiation went well and they finally reached an agreement.
[root@ryan linux]# sed 's/[a-zA-Z]//g' test3.txt
:26::138912:
:28::23124:
:30::123123:
:20::35345:
:16::123321:
.:18::123321:
:16::123321:.
://../\,3
.
也可使用 sed 's/[0-9a-zA-Z]//g' test3.txt
[root@ryan linux]# cat test3.log
aabbccddeeffgghh
[root@ryan linux]# sed 's/^(..)(..)(..)(..).*$/1:2:3:4/' test3.log
aa:bb:cc:dd
说明:
其中^表示从一行的开头匹配
第一个(..)表示匹配任意2个字符,并且后面的 1,就是这次匹配的结果;
对于字符串 aabbccddeeffgghh 而言,就是 aa 这2个字符;
同理,第二(..)匹配bb,对应 2;
第三(..)匹配 cc,对应 3;
第四(..)匹配 dd,对应 4;
剩下的 eeffgghh 匹配 .*$,其中 .* 表示匹配任意个字符,$ 匹配到末尾,这些字符串被抛弃;
aabbccddeeffgghh 得到的结果就是 aa:bb:cc:dd。
这里1 和2 的意思其实就是引用第 一,二 个 () 里的内容。() 括号的意思就是,当你执行替换的时候不是整行替换,而且替换 () 里的内容。
[root@ryan linux]# cat test3
total 92
-rw-r--r--. 1 root root 40 Mar 31 19:29 1
-rw-r--r--. 1 root root 13368 Mar 20 20:46 file.log
-rw-r--r--. 1 root root 13368 Mar 18 17:48 install.log
drwxr-xr-x. 2 root root 4096 Mar 31 20:03 split_dir
drwxr-xr-x+ 2 root root 4096 Dec 3 13:35 test
drwxr-xr-x. 2 root root 4096 Nov 26 03:46 test1
-rw-r--r--. 1 root root 158 Mar 20 21:11 test1.tar.bz2
-rw-r--r--. 1 root root 161 Mar 18 22:02 test1.tar.gz
-rw-r--r--. 1 root root 208 Mar 21 22:24 test1.tar.xz
-rw-r--r--. 1 root root 7 Mar 31 13:38 test1.txt
-rw-r--r--. 1 root root 162 Mar 20 21:21 test1.zip
-rw-r--r-- 1 root root 312 Apr 5 22:58 test2
-rw-r--r-- 1 root root 0 Apr 7 11:32 test3
-rw-r--r--. 1 root root 310 Apr 7 11:21 test3.txt
drwxr-xr-x. 3 root root 4096 Mar 20 21:24 test4
-rw-r--r--. 1 root root 678 Mar 20 21:31 test4.zip
-rwxr-xr-x. 1 root root 43 Apr 3 22:08 test.sh
[root@ryan linux]# sed -r 's/s{1,}/#/g' test3
total#92
-rw-r--r--.#1#root#root#40#Mar#31#19:29#1
-rw-r--r--.#1#root#root#13368#Mar#20#20:46#file.log
-rw-r--r--.#1#root#root#13368#Mar#18#17:48#install.log
drwxr-xr-x.#2#root#root#4096#Mar#31#20:03#split_dir
drwxr-xr-x+#2#root#root#4096#Dec#3#13:35#test
drwxr-xr-x.#2#root#root#4096#Nov#26#03:46#test1
-rw-r--r--.#1#root#root#158#Mar#20#21:11#test1.tar.bz2
-rw-r--r--.#1#root#root#161#Mar#18#22:02#test1.tar.gz
-rw-r--r--.#1#root#root#208#Mar#21#22:24#test1.tar.xz
-rw-r--r--.#1#root#root#7#Mar#31#13:38#test1.txt
-rw-r--r--.#1#root#root#162#Mar#20#21:21#test1.zip
-rw-r--r--#1#root#root#312#Apr#5#22:58#test2
-rw-r--r--#1#root#root#0#Apr#7#11:32#test3
-rw-r--r--.#1#root#root#310#Apr#7#11:21#test3.txt
drwxr-xr-x.#3#root#root#4096#Mar#20#21:24#test4
-rw-r--r--.#1#root#root#678#Mar#20#21:31#test4.zip
-rwxr-xr-x.#1#root#root#43#Apr#3#22:08#test.sh
6.5 直接修改文件的内容
[root@ryan linux]# cat test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
adam:30:xinjiang:123123:python
emily:20:beijing:35345:scala
ada:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
[root@ryan linux]# sed -i 's/ada/robot/g' test3.txt
[root@ryan linux]# cat test3.txt
bob:26:shanxi:138912:linux
ryan:28:china:23124:java
robotm:30:xinjiang:123123:python
emily:20:beijing:35345:scala
robot:16:shengjiang:123321:rubby
jim.green:18:shandong:123321:rubby
tom:16:hebei:123321:ru.bby
http://www.baidu.com/musicdocument,mp3
The negotiation went well and they finally reached an agreement.
七、awk 工具的使用
awk 是一个强大的文本分析工具,相对于 grep 的查找,sed 的编辑,awk 在其对数据分析并生成报告时,显得尤为强大。简单来说 awk 就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
注意:awk 以空格为分割域时,是以单个或多个连续的空格为分隔符的;cut 则是以单个空格作为分隔符。
7.1 截取文档中的某个段
[root@ryan linux]# cat test4.log
-rw-r--r--.#1#root#root#40#Mar#31#19:29#1
-rw-r--r--.#1#root#root#13368#Mar#20#20:46#file.log
-rw-r--r--.#1#root#root#13368#Mar#18#17:48#install.log
drwxr-xr-x.#2#root#root#4096#Mar#31#20:03#split_dir
drwxr-xr-x+#2#root#root#4096#Dec#3#13:35#test
[root@ryan linux]# awk -F '#' '{print $1}' test4.log
-rw-r--r--.
-rw-r--r--.
-rw-r--r--.
drwxr-xr-x.
drwxr-xr-x+
-F 选项的作用是指定分隔符,如果不加 -F 选项,则以空格或者 tab 为分隔符。print 表示打印的动作,用来打印某个段,$1表示第1个字段,$2为第2个字段,以此类推。$0比较特殊,它表示整行。print 动作要用 {} 括起来,否则会报错。
print 还可以打印自定义的内容,但是自定义的内容要用双引号括起来,如下:
[root@ryan linux]# awk -F '#' '{print $1":"$3":"$4":"$9}' test4.log
-rw-r--r--.:root:root:1
-rw-r--r--.:root:root:file.log
-rw-r--r--.:root:root:install.log
drwxr-xr-x.:root:root:split_dir
drwxr-xr-x+:root:root:test
7.2 匹配字符或者字符串
[root@ryan linux]# awk '/robot/' test3.txt
robotm:30:xinjiang:123123:python
robot:16:shengjiang:123321:rubby
7.3 条件操作符
awk 中可以用逻辑符号进行判断,比如 == 表示等于,另外还有 >、>=、<、<=、!= 等,在和数字比较时,不能把数字用括号括起来,否则,awk 会认为是字符,而不是数字。
[root@ryan linux]# awk -F ':' '$3>=100' /etc/passwd
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
rtkit:x:498:496:RealtimeKit:/proc:/sbin/nologin
pulse:x:497:495:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin
adam:x:500:500::/home/adam:/bin/bash
bob:x:501:501:bob-xu,hsbc,1008611,1008612:/home/bob:/bin/bash
也可以两个字段之间进行逻辑比较,如下:
[root@ryan linux]# awk -F ':' '$3!=$4' /etc/passwd
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
……
还可以使用 && 和 ||,分别表示 "并且" 和 "或者",如下:
[root@ryan linux]# awk -F ':' '$3>500 && $3<700' /etc/passwd
bob:x:501:501:bob-xu,hsbc,1008611,1008612:/home/bob:/bin/bash
7.4 awk 的内置变量
awk 常用的变量有 NF 和 NR,NF 表示用分隔符分隔后一共有多少段,NR 表示行号。
[root@ryan linux]# awk -F ':' '{print NF}' /etc/passwd
7
7
7
……
[root@ryan linux]# awk -F ':' '{print $NF}' /etc/passwd
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
……
[root@ryan linux]# awk -F ':' '{print NR}' /etc/passwd
1
2
3
……
[root@ryan linux]# awk 'NR>=1 && NR <=3' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@ryan linux]# awk 'NR>=1 && NR <=3' /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin
7.5 awk 常见的使用场景
使用 awk 命令获取文本的某一行,某一列,如下:
打印文件的第一列(域) : awk '{print $1}' filename
打印完第一列,然后打印第二列 : awk '{print $1 $2}' filename
打印文本文件的总行数 : awk 'END{print NR}' filename
打印文本第一行 :awk 'NR==1{print}' filename
打印文本第二行的第一列 :sed -n '2'p filename|awk -F ':' '{print $1}' 或 awk -F ':' 'NR==2{print $1}' filename
打印文本最后一行:awk 'END {print}' filename
打印文本最后一行的第二列:awk -F ':' 'END {print $2}' filename
这里的 END 是 awk 特有的语法,表示所有的行都已经执行。
在 Shell 里面,如果想将命令的运行结果赋值给某个变量,可采用如下两种方式,格式为
1) arg=`(命令)`
2) arg=$(命令)
因此,如果想要把某一文件的总行数赋值给变量 nlines,可以表达为:
1) nlines=`(awk 'END{print NR}' filename)`
或者
2) nlines=$(awk 'END{print NR}' filename)
八、正则表达式的最短与最长匹配
贪婪与懒惰规则
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。考虑这个表达式:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab。这被称为贪婪匹配。
但是有时后,我们也需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号 ?,问号表示匹配前面的内容0次或1次。这样 .*? 就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复,即最多匹配一次。现在看看懒惰版的例子:
a.*?b 匹配最短的,以 a 开始,以 b 结束的字符串。如果把它应用于 aabab 的话,它会分别匹配 aab(第一到第三个字符)和 ab(第四到第五个字符)。
为什么第一个匹配是 aab(第一到第三个字符)而不是 ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
懒惰限定符

正则表达式也可以返回子匹配结果
$1,$2……是表示的小括号里的内容,其中 $1是第1个小括号里的内容,$2是第2个小括号里的内容,依次类推。
比如 /gai([w]+?)over([d]+)/
匹配 gainover123
$1为第1个括号里的 n;
$2为第2个括号里的 123。