拓展
python解释器:
- Cpython C语言写的
- Jpython java语言写的
什么是GIL全局解释器锁
在同一个进程下开启的多线程,同一时刻只能有一个线程执行,因为Cpython的内存管理不是线程安全
摘自官方文档解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
为什么要有GIL全局解释器锁?

假如我有一个主进程和三个子进程,一个主线程(demo.py)需要一个python解释器,主线程下的三个子线程都是为X进程运算x -= 1,倘若我们不进行加锁,三个子线程同时到达python解释器,同时对x就行修改,会造成数据计算错误。如果我的子线程是对x进程赋值,在刚执行到x =的时候,python解释器的垃圾回收线程如果没有锁的情况下,也运行了,判断x是没有值的,就会将x进行回收,所以要有GIL全局解释器来保证数据的安全。
GIL全局解释器锁的优缺点
优点:
保证数据的安全
缺点:
单个进程下,开启多个线程,牺牲执行效率,无法实现并行,只能实现并发。
多线程和IO密集型的应用场景
- IO密集型,使用多线程
- 计算密集型,使用多进程
import time
from threading import Thread
n = 100
def task():
global n
m = n
time.sleep(3)
n = m - 1
if __name__ == '__main__':
list1 = []
for line in range(10):
t = Thread(target=task)
t.start()
list1.append(t)
for t in list1:
t.join()
print(n)

转载文章
作者:DarrenChan陈驰
链接:https://www.zhihu.com/question/23474039/answer/269526476
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在介绍Python中的线程之前,先明确一个问题,Python中的多线程是假的多线程! 为什么这么说,我们先明确一个概念,全局解释器锁(GIL)。
Python代码的执行由Python虚拟机(解释器)来控制。Python在设计之初就考虑要在主循环中,同时只有一个线程在执行,就像单CPU的系统中运行多个进程那样,内存中可以存放多个程序,但任意时刻,只有一个程序在CPU中运行。同样地,虽然Python解释器可以运行多个线程,只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同时只有一个线程在运行。在多线程环境中,Python虚拟机按照以下方式执行。
1.设置GIL。
2.切换到一个线程去执行。
3.运行。
4.把线程设置为睡眠状态。
5.解锁GIL。
6.再次重复以上步骤。
对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其他线程在这个线程等待I/O的时候运行。如果某线程并未使用很多I/O操作,它会在自己的时间片内一直占用处理器和GIL。也就是说,I/O密集型的Python程序比计算密集型的Python程序更能充分利用多线程的好处。
我们都知道,比方我有一个4核的CPU,那么这样一来,在单位时间内每个核只能跑一个线程,然后时间片轮转切换。但是Python不一样,它不管你有几个核,单位时间多个核只能跑一个线程,然后时间片轮转。看起来很不可思议?但是这就是GIL搞的鬼。任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
我们不妨做个试验:
#coding=utf-8
from multiprocessing import Pool
from threading import Thread
from multiprocessing import Process
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(3):
t = Thread(target=loop)
t.start()
while True:
pass我的电脑是4核,所以我开了4个线程,看一下CPU资源占有率:
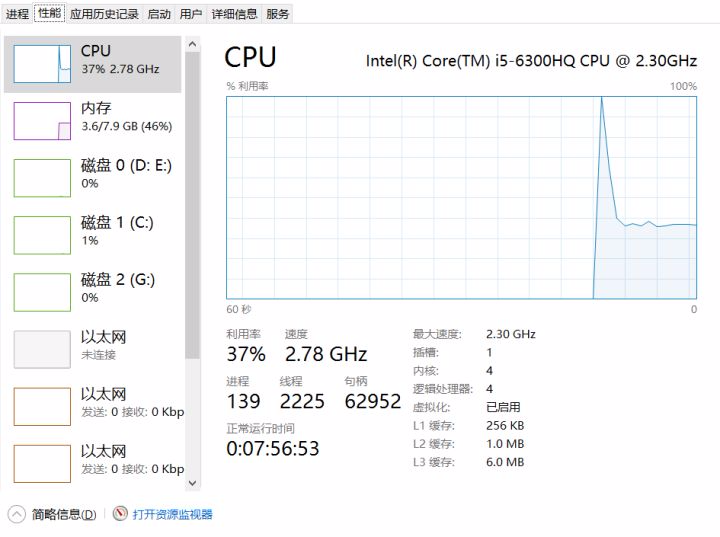
我们发现CPU利用率并没有占满,大致相当于单核水平。
而如果我们变成进程呢?
我们改一下代码:
#coding=utf-8
from multiprocessing import Pool
from threading import Thread
from multiprocessing import Process
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(3):
t = Process(target=loop)
t.start()
while True:
pass
结果直接飙到了100%,说明进程是可以利用多核的!
为了验证这是Python中的GIL搞得鬼,我试着用Java写相同的代码,开启线程,我们观察一下:
package com.darrenchan.thread;
public class TestThread {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
}
}
}).start();
}
while(true){
}
}
}
由此可见,Java中的多线程是可以利用多核的,这是真正的多线程!而Python中的多线程只能利用单核,这是假的多线程!
难道就如此?我们没有办法在Python中利用多核?当然可以!刚才的多进程算是一种解决方案,还有一种就是调用C语言的链接库。对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其他线程在这个线程等待I/O的时候运行。我们可以把一些 计算密集型任务用C语言编写,然后把.so链接库内容加载到Python中,因为执行C代码,GIL锁会释放,这样一来,就可以做到每个核都跑一个线程的目的!
可能有的小伙伴不太理解什么是计算密集型任务,什么是I/O密集型任务?
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
综上,Python多线程相当于单核多线程,多线程有两个好处:CPU并行,IO并行,单核多线程相当于自断一臂。所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
分享廖雪峰的博客:廖雪峰博客