
0x01 前言
大家好,我还是那个菜菜的Adminxe,依旧还是很菜,然后这几天也是准备深入爬虫,比如学习完,想要去爬一下小说网,或者是XX影片,或者是XX图书漫画,反正你懂的就行了,我是那个脑力小可爱-酷酷的菜!
今天准备给大家分享的是python爬虫之爬取百度贴吧(约会吧)全站图片,当然,不懂得自行搜索,我为啥要爬取这个贴吧,肯定不用想,那必然是妹子多,妹子多,才能福利大,有妹子,才能激发脑细胞,才能继续学习!
0x01 爬取效果
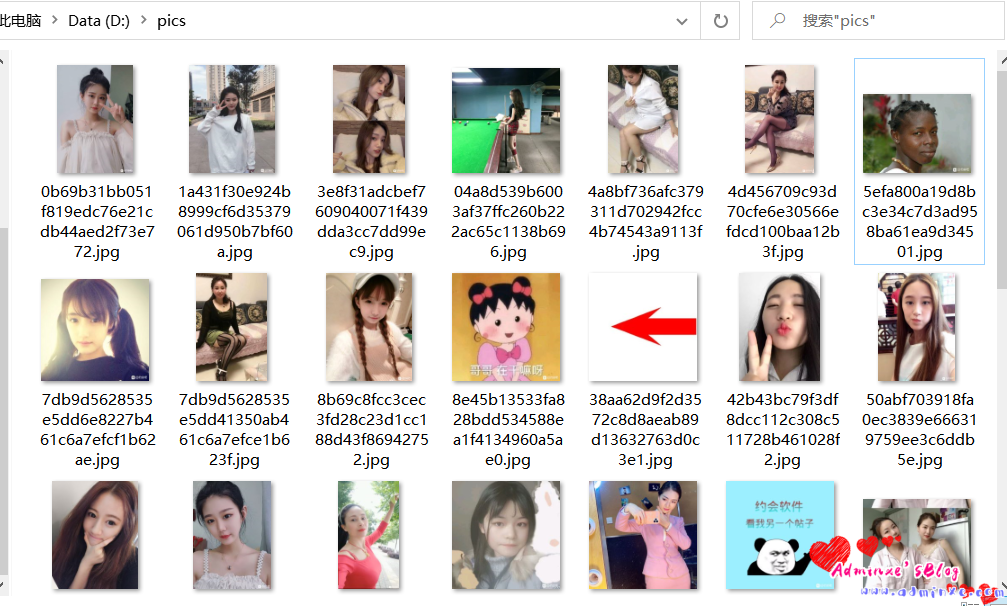
0x02 爬虫代码
#! /usr/bin/python3
# 约会吧全站图片爬取
import requests,parsel,os
page_num = 0
for page in range(0,57050 + 1, 50):
page_num = +1
print('===========================正在爬取第{}页图片==========================='.format(page_num))
#爬虫的一般思路
#1、分析目标网页,确定爬取的url路径,headers参数
base_url = "https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BA%A6%E4%BC%9A%E5%90%A7&fr=search&pn={}".format(page)
headers = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'}
#2、发送请求 --requests 模拟浏览器发送请求,获取响应数据
response = requests.get(url=base_url,headers=headers)
html_str = response.text
#print(html_str)
#3、解析数据 --parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
# 转化数据类型
html = parsel.Selector(html_str)
#print(html)
title_url = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/@href').extract()
#print(title_url)
# 拼接完整的url地址
for title in title_url:
all_url = 'https://tieba.baidu.com' + title
print('当前帖子连接:',all_url)
# 继续发送帖子的请求
response_2 = requests.get(url=all_url,headers=headers)
html_img = response_2.text
# 二次数据
html2 = parsel.Selector(html_img)
img_url = html2.xpath('//cc/div/img[@class="BDE_Image"]/@src').extract()
#print(img_url)
for img in img_url:
img_data = requests.get(url=img,headers=headers).content
# 4、保存数据
# file_name = img.split('/')[-1]
# with open('YUBimg\' + file_name,mode='wb') as f:
# print('正在下载图片:',file_name)
# f.write(img_data)
# f.close()
root = "D://pics//"
file_name = img.split('/')[-1]
path = root + file_name
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
with open(path,'wb') as f:
print('正在下载图片:',file_name)
f.write(img_data)
f.close()
except:
print("爬取失败!")转载请注明:Adminxe's Blog » Python爬虫(约会吧全站图片爬取)