转自 http://blog.csdn.net/Androidlushangderen/article/details/43311943
参考资料:http://blog.csdn.net/hguisu/article/details/7996185
更多数据挖掘算法:https://github.com/linyiqun/DataMiningAlgorithm
链接分析
在链接分析中有2个经典的算法,1个是PageRank算法,还有1个是HITS算法,说白了,都是做链接分析的。具体是怎么做呢,继续往下看。
PageRank算法
要说到PageRank算法的作用,得先从搜索引擎开始讲起,PageRank算法的由来正式与此相关。
搜索引擎
最早时期的搜索引擎的结构,无外乎2个核心步骤,step1:建立庞大的资料库,step2:建立索引库,用于指向具体的资料。然后就是用户的查找操作了,那怎么查呢,一个很让人会联想到的方法就是通过关键字匹配的方法,例如我想输入张三这个关键词,那我就会在资源中查包含有张三这个词语的文章,按照关键词匹配方法,只要一篇文章中张三出现的次数越多,就越是要查询的目标。(但是更公正的方法应是次数/文章总次数,一个比值的形式显然更公平)。仔细这么想也没错。好继续往下。
Term Spam攻击
既然我已经知道了搜索的核心原理,如果我想要让我的网页能够出现在搜索的结果更靠前的位置,只要在页面中加入更多对应的关键词不就OK了,比如在html的div中写入10000个张三,让后使其隐藏此标签,使得前端页面不受影响,那我的目的岂不是达到了,这就是Term Spam攻击。
PageRank算法原理
既然关键词匹配算法容易遭到攻击,那有什么好的办法呢,这是候就出现了著名的PageRank算法,作为新的网页排名/重要性算法,最早是由Google的创始人所写的算法,PageRank算法彻底摒弃了什么关键词不关键词的,每个网页都有自己的PageRank值,意味一个网页的重要程度,PR值越高,最后呈现的位置更靠前。那怎么衡量每个网页的重要程度呢,答案是别的页面对他的链接。一句话,越多的网页在其内容上存在指向你的链接,说明你的网页越有名。具体PR值的计算全是通过别的网页的PR值做计算的,简单计算过程如下:
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。

换句话说,根据链出总数平分一个页面的PR值。

所示的例子来说明PageRank的具体计算过程。

以上是网页内部有链接的时候,因为还可能在1个网页中没有任何链接的情况,而这个时候,跳到任何网页的概率都是可能的。因此最后的计算公式就变成了这个样子:

q称为阻尼系数。
PageRank的计算过程
PageRank的计算过程实际并不复杂,他的计算数学表达式如下:

就是1-q变成了1-q/n了,算法的过程其实是利用了幂法的原理,等最后计算达到收敛了,也就结束了。
按照上面的计算公式假设矩阵A = q × P + ( 1 一 q) *  /N,e为全为1的单位向量,P是一个链接概率矩阵,将链接的关系通过概率矩阵表现,A[i][j]表示网页i存在到网页j的链接,转化如下:
/N,e为全为1的单位向量,P是一个链接概率矩阵,将链接的关系通过概率矩阵表现,A[i][j]表示网页i存在到网页j的链接,转化如下:




图4 P’ 的转置矩 阵
这里为什么要把矩阵做转置操作呢,原本a[i][j]代表i到j链接,现在就变为了j到i的链接的概率了,好,关键记住这点就够了。最后A就计算出来了,你可以把他理解为网页链接概率矩阵,最后只需要乘上对应的网页PR值就可以了。
此时初始化向量R[1, 1, 1];代表最初的网页的PR值,与此A概率矩阵相乘,第一个PR值R[0]'=A[0][0]*R[0] + A[0][1]*R[1] + A[0][2]*R[2],又因为A[i][j]此时的意思正是j到i网页的链接概率,这样的表达式恰恰就是上文我们所说的核心原理。然后将计算新得的R向量值域概率矩阵迭代计算直到收敛。
PageRank小结
PageRank的计算过程巧妙的被转移到了矩阵的计算中了,使得过程非常的精简。
Link Spam攻击
魔高一尺道高一丈,我也已经知道了PageRank算法的原理无非就是靠链接数升排名嘛,那我想让我自己的网页排名靠前,只要搞出很多网页,把链接指向我,不就行了,学术上这叫Link Spam攻击。但是这里有个问题,PR值是相对的,自己的网页PR值的高低还是要取决于指向者的PR值,这些指向者 的PR值如果不高,目标页也不会高到哪去,所以这时候,如果你想自己造成一堆的僵尸网页,统统指向我的目标网页,PR也不见的会高,所以我们看到的更常见的手段是在门户网站上放链接,各大论坛或者类似于新浪,网页新闻中心的评论中方链接,另类的实现链接指向了。目前针对这种作弊手法的直接的比较好的解决办法是没有,但是更多采用的是TrustRank,意味信任排名检测,首先挑出一堆信任网页做参照,然后计算你的网页的PR值,如果你网页本身很一般,但是PR值特别高,那么很有可能你的网页就是有问题的。
HITS
HITS算法同样作为一个链接分析算法,与PageRank算法在某些方面还是比较像的,将这2种算法放在一起做比较,再好不过的了,一个明显的不同点是HITS处理的网页量是小规模的集合,而且他是与查询相关的,首先输入一个查询q,假设检索系统返回n个页面,HITS算法取其中的200个(假设值),作为分析的样本数据,返回里面更有价值的页面。
HITS算法原理
HITS衡量1个页面用A[i]和H[i]值表示,A代表Authority权威值,H代表Hub枢纽值。
大意可理解为我指出的网页的权威值越高,我的Hub值越大。指向我的网页的Hub值越大,我的权威值越高。二者的变量相互权衡。下面一张图直接明了:
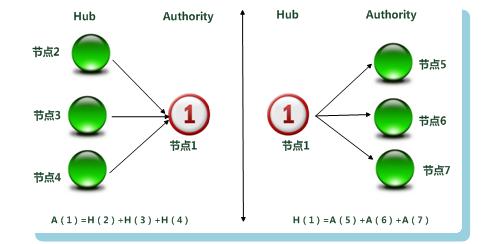
图3 Hub与Authority权值计算
如果理解了PageRank算法的原理,理解HITS应该很容易,最后结果的输出是根据页面的Authority权威值从高到低。
1)  、
、 分别表示网页结点 i 的Authority值(权威度)和Hub值(中心度)。
分别表示网页结点 i 的Authority值(权威度)和Hub值(中心度)。
2) 对于“扩展集base”来说,我们并不知道哪些页面是好的“Hub”或者好的“Authority”页面,每个网页都有潜在的可能,所以对于每个页面都设立两个权值,分别来记载这个页面是好的Hub或者Authority页面的可能性。在初始情况下,在没有更多可利用信息前,每个页面的这两个权值都是相同的,可以都设置为1,即:

3)每次迭代计算Hub权值和Authority权值:
网页 a (i)在此轮迭代中的Authority权值即为所有指向网页 a (i)页面的Hub权值之和:
a (i) = Σ h (i) ;
网页 a (i)的Hub分值即为所指向的页面的Authority权值之和:
h (i) = Σ a (i) 。
对a (i)、h (i)进行规范化处理:
将所有网页的中心度都除以最高中心度以将其标准化:
a (i) = a (i)/|a(i)| ;
将所有网页的权威度都除以最高权威度以将其标准化:
h (i) = h (i)/ |h(i)| :
5)如此不断的重复第4):上一轮迭代计算中的权值和本轮迭代之后权值的差异,如果发现总体来说权值没有明显变化,说明系统已进入稳定状态,则可以结束计算,即a ( u),h(v)收敛 。
HITS算法描述

具体可以对照后面我写的程序。
HITS小结
从链接反作弊的角度来思考,HITS更容易遭受到Link Spam的攻击,因为你想啊,网页数量少啊,出错的几率就显得会大了。
PageRank算法和HITS算法实现
最后奉上本人亲自实现的2个算法,输入数据是同一个文(每条记录代表网页i到网页j存在链接):
1 2 1 3 2 3 3 1
算法都不是太难:

package DataMining_PageRank;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.Array;
import java.text.MessageFormat;
import java.util.ArrayList;
/**
* PageRank网页排名算法工具类
*
* @author lyq
*
*/
public class PageRankTool {
// 测试输入数据
private String filePath;
// 网页总数量
private int pageNum;
// 链接关系矩阵
private double[][] linkMatrix;
// 每个页面pageRank值初始向量
private double[] pageRankVecor;
// 网页数量分类
ArrayList<String> pageClass;
public PageRankTool(String filePath) {
this.filePath = filePath;
readDataFile();
}
/**
* 从文件中读取数据
*/
private void readDataFile() {
File file = new File(filePath);
ArrayList<String[]> dataArray = new ArrayList<String[]>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
String[] tempArray;
while ((str = in.readLine()) != null) {
tempArray = str.split(" ");
dataArray.add(tempArray);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
pageClass = new ArrayList<>();
// 统计网页类型种数
for (String[] array : dataArray) {
for (String s : array) {
if (!pageClass.contains(s)) {
pageClass.add(s);
}
}
}
int i = 0;
int j = 0;
pageNum = pageClass.size();
linkMatrix = new double[pageNum][pageNum];
pageRankVecor = new double[pageNum];
for (int k = 0; k < pageNum; k++) {
// 初始每个页面的pageRank值为1
pageRankVecor[k] = 1.0;
}
for (String[] array : dataArray) {
i = Integer.parseInt(array[0]);
j = Integer.parseInt(array[1]);
// 设置linkMatrix[i][j]为1代表i网页包含指向j网页的链接
linkMatrix[i - 1][j - 1] = 1;
}
}
/**
* 将矩阵转置
*/
private void transferMatrix() {
int count = 0;
for (double[] array : linkMatrix) {
// 计算页面链接个数
count = 0;
for (double d : array) {
if (d == 1) {
count++;
}
}
// 按概率均分
for (int i = 0; i < array.length; i++) {
if (array[i] == 1) {
array[i] /= count;
}
}
}
double t = 0;
// 将矩阵转置换,作为概率转移矩阵
for (int i = 0; i < linkMatrix.length; i++) {
for (int j = i + 1; j < linkMatrix[0].length; j++) {
t = linkMatrix[i][j];
linkMatrix[i][j] = linkMatrix[j][i];
linkMatrix[j][i] = t;
}
}
}
/**
* 利用幂法计算pageRank值
*/
public void printPageRankValue() {
transferMatrix();
// 阻尼系数
double damp = 0.5;
// 链接概率矩阵
double[][] A = new double[pageNum][pageNum];
double[][] e = new double[pageNum][pageNum];
// 调用公式A=d*q+(1-d)*e/m,m为网页总个数,d就是damp
double temp = (1 - damp) / pageNum;
for (int i = 0; i < e.length; i++) {
for (int j = 0; j < e[0].length; j++) {
e[i][j] = temp;
}
}
for (int i = 0; i < pageNum; i++) {
for (int j = 0; j < pageNum; j++) {
temp = damp * linkMatrix[i][j] + e[i][j];
A[i][j] = temp;
}
}
// 误差值,作为判断收敛标准
double errorValue = Integer.MAX_VALUE;
double[] newPRVector = new double[pageNum];
// 当平均每个PR值误差小于0.001时就算达到收敛
while (errorValue > 0.001 * pageNum) {
System.out.println("**********");
for (int i = 0; i < pageNum; i++) {
temp = 0;
// 将A*pageRankVector,利用幂法求解,直到pageRankVector值收敛
for (int j = 0; j < pageNum; j++) {
// temp就是每个网页到i页面的pageRank值
temp += A[i][j] * pageRankVecor[j];
}
// 最后的temp就是i网页的总PageRank值
newPRVector[i] = temp;
System.out.println(temp);
}
errorValue = 0;
for (int i = 0; i < pageNum; i++) {
errorValue += Math.abs(pageRankVecor[i] - newPRVector[i]);
// 新的向量代替旧的向量
pageRankVecor[i] = newPRVector[i];
}
}
String name = null;
temp = 0;
System.out.println("--------------------");
for (int i = 0; i < pageNum; i++) {
System.out.println(MessageFormat.format("网页{0}的pageRank值:{1}",
pageClass.get(i), pageRankVecor[i]));
if (pageRankVecor[i] > temp) {
temp = pageRankVecor[i];
name = pageClass.get(i);
}
}
System.out.println(MessageFormat.format("等级最高的网页为:{0}", name));
}
}
下面是HITS算法的实现:
package DataMining_HITS;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
/**
* HITS链接分析算法工具类
* @author lyq
*
*/
public class HITSTool {
//输入数据文件地址
private String filePath;
//网页个数
private int pageNum;
//网页Authority权威值
private double[] authority;
//网页hub中心值
private double[] hub;
//链接矩阵关系
private int[][] linkMatrix;
//网页种类
private ArrayList<String> pageClass;
public HITSTool(String filePath){
this.filePath = filePath;
readDataFile();
}
/**
* 从文件中读取数据
*/
private void readDataFile() {
File file = new File(filePath);
ArrayList<String[]> dataArray = new ArrayList<String[]>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
String[] tempArray;
while ((str = in.readLine()) != null) {
tempArray = str.split(" ");
dataArray.add(tempArray);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
pageClass = new ArrayList<>();
// 统计网页类型种数
for (String[] array : dataArray) {
for (String s : array) {
if (!pageClass.contains(s)) {
pageClass.add(s);
}
}
}
int i = 0;
int j = 0;
pageNum = pageClass.size();
linkMatrix = new int[pageNum][pageNum];
authority = new double[pageNum];
hub = new double[pageNum];
for(int k=0; k<pageNum; k++){
//初始时默认权威值和中心值都为1
authority[k] = 1;
hub[k] = 1;
}
for (String[] array : dataArray) {
i = Integer.parseInt(array[0]);
j = Integer.parseInt(array[1]);
// 设置linkMatrix[i][j]为1代表i网页包含指向j网页的链接
linkMatrix[i - 1][j - 1] = 1;
}
}
/**
* 输出结果页面,也就是authority权威值最高的页面
*/
public void printResultPage(){
//最大Hub和Authority值,用于后面的归一化计算
double maxHub = 0;
double maxAuthority = 0;
int maxAuthorityIndex =0;
//误差值,用于收敛判断
double error = Integer.MAX_VALUE;
double[] newHub = new double[pageNum];
double[] newAuthority = new double[pageNum];
while(error > 0.01 * pageNum){
for(int k=0; k<pageNum; k++){
newHub[k] = 0;
newAuthority[k] = 0;
}
//hub和authority值的更新计算
for(int i=0; i<pageNum; i++){
for(int j=0; j<pageNum; j++){
if(linkMatrix[i][j] == 1){
newHub[i] += authority[j];
newAuthority[j] += hub[i];
}
}
}
maxHub = 0;
maxAuthority = 0;
for(int k=0; k<pageNum; k++){
if(newHub[k] > maxHub){
maxHub = newHub[k];
}
if(newAuthority[k] > maxAuthority){
maxAuthority = newAuthority[k];
maxAuthorityIndex = k;
}
}
error = 0;
//归一化处理
for(int k=0; k<pageNum; k++){
newHub[k] /= maxHub;
newAuthority[k] /= maxAuthority;
error += Math.abs(newHub[k] - hub[k]);
System.out.println(newAuthority[k] + ":" + newHub[k]);
hub[k] = newHub[k];
authority[k] = newAuthority[k];
}
System.out.println("---------");
}
System.out.println("****最终收敛的网页的权威值和中心值****");
for(int k=0; k<pageNum; k++){
System.out.println("网页" + pageClass.get(k) + ":"+ authority[k] + ":" + hub[k]);
}
System.out.println("权威值最高的网页为:网页" + pageClass.get(maxAuthorityIndex));
}
}
2个结果的输出如下:
PageRank算法;
********** 1.0 0.7499999999999999 1.25 ********** 1.125 0.75 1.1249999999999998 ********** 1.0624999999999998 0.78125 1.15625 ********** 1.078125 0.7656249999999998 1.1562499999999998 ********** 1.0781249999999998 0.7695312499999998 1.1523437499999998 ********** 1.0761718749999998 0.7695312499999998 1.1542968749999996 ********** 1.0771484374999996 0.7690429687499997 1.1538085937499996 -------------------- 网页1的pageRank值:1.077 网页2的pageRank值:0.769 网页3的pageRank值:1.154 等级最高的网页为:3
HITS算法:
0.5:1.0 0.5:0.5 1.0:0.5 --------- 0.3333333333333333:1.0 0.6666666666666666:0.6666666666666666 1.0:0.3333333333333333 --------- 0.2:1.0 0.6000000000000001:0.6000000000000001 1.0:0.2 --------- 0.125:1.0 0.625:0.625 1.0:0.125 --------- 0.07692307692307693:1.0 0.6153846153846154:0.6153846153846154 1.0:0.07692307692307693 --------- 0.04761904761904762:1.0 0.6190476190476191:0.6190476190476191 1.0:0.04761904761904762 --------- 0.029411764705882356:1.0 0.6176470588235294:0.6176470588235294 1.0:0.029411764705882356 --------- ****最终收敛的网页的权威值和中心值**** 网页1:0.029411764705882356:1.0 网页2:0.6176470588235294:0.6176470588235294 网页3:1.0:0.029411764705882356 权威值最高的网页为:网页3
结果都是网页3排名最高。