这是4月2日17:30~19:30之间发生在阿里云上的故事。
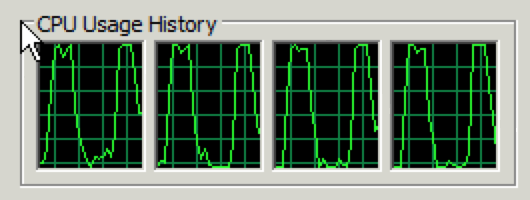
标题中的“看不见”是指阿里云的监控系统没有监控到;“CPU在坐过山车”是指CPU占用的瞬间波动(见下图);“磁盘IO在蹦极”是指磁盘IO的瞬间波动。
(图1)
4月2日17:30左右开始,访问博客园首页有时会遇到502 Bad Gateway错误,如下图:
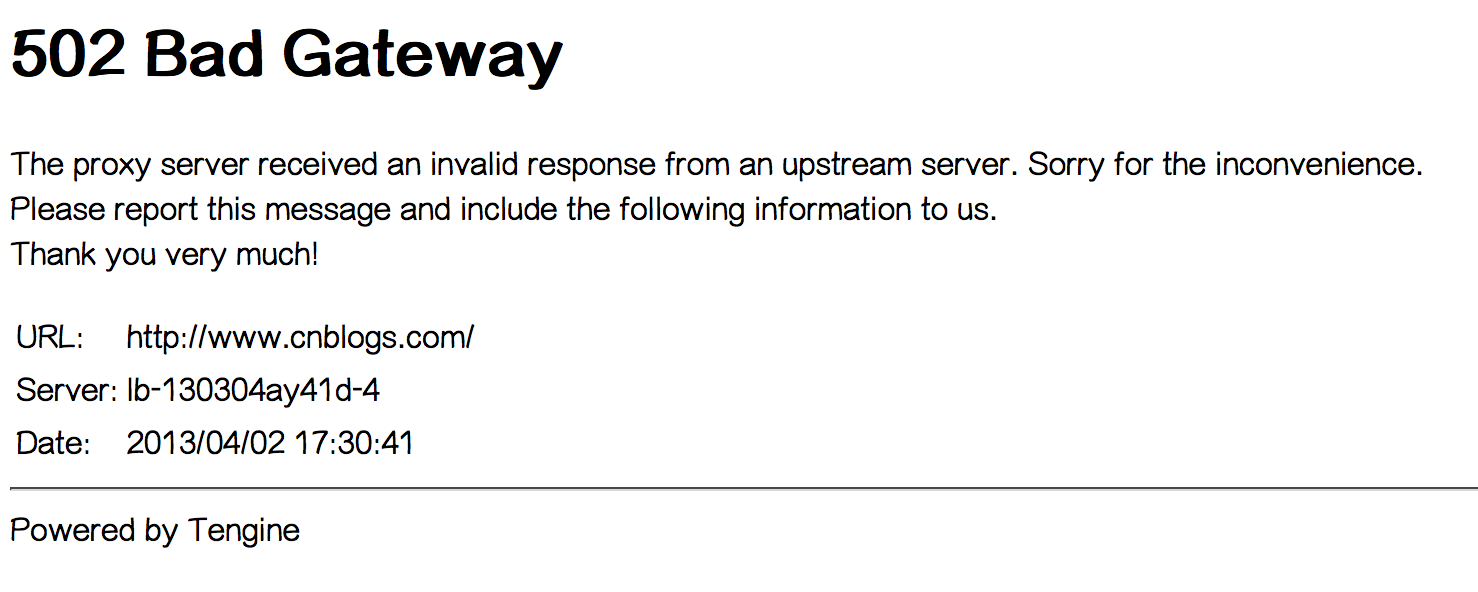
这是由阿里云负载均衡SLB返回的错误信息。
发现这个问题后,我们立即登上负载均衡中的2台云服务器,查看Windows性能监视器发现CPU占用波动很大(见之前的图1),有如坐过山车,瞬间冲到100%(如果在这时访问网站就会遇到502错误),然后又回落。接着,打开阿里云网站上的管理控制台,查看系统资源监控,奇迹出现了——阿里云监控显示CPU占用平稳,最高也没超过60%。
当时以为是阿里云监控系统出了问题,于是向阿里云提交了工单。
18:00左右,我们与阿里云客服都未进行任何操作,CPU占用突然恢复了正常。
CPU坐完过山车后不久,18:30左右开始,我们收到用户的反馈,说在博客后台发布博文时出现提示:“Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding.”(数据库写入超时)。我们对这个错误记忆犹新,3月14日经历过(详见云计算之路-迁入阿里云后:20130314云服务器故障经过),那次是由于云服务器所在的集群硬盘IO负载高引起的。我们断定这次肯定还是云服务器磁盘IO的问题。于是又进入阿里云网站上的管理控制台,查看系统资源监控以验证磁盘IO是否高,奇迹又一次出现——阿里云监控显示磁盘IO正常。
19:30左右,"Timeout expired"错误消失。
我们又向阿里云提交了工单,阿里云客服依据监控数据,认为阿里云自身的系统正常。我们当然不认同,我们的应用本身不会引发这个罕见的"Timeout expired"错误,而且这段时间数据库写入操作并不多。
我们查看了这段时间数据库中的数据,发现也有不少博文正常发布了。说明当时如果磁盘IO有问题,应该是处于一种波动情况。用户在波峰时提交,就会遇到数据库写入超时故障。
可奇怪的是为什么阿里云监控系统监控不到磁盘IO的波动?更奇怪的是两次问题,阿里云监控系统都没监控到。
。。。
第二天,接到阿里云客服的电话,说我们在阿里云网站的管理控制台上看到的监控数据是5分钟采一次样,阿里云客服看到的监控数据是1分钟采一次样(两处的监控都没监控到)。对于瞬间波动,阿里云监控系统的确很难监控到。
接了电话之后,我们分析了一下,然后豁然开朗。
阿里云监控系统每1分钟巡视一下我们的云服务器, CPU坐过山车、磁盘IO蹦极发生在秒级。阿里云监控过来巡视时,CPU已经或者还没坐过山车,磁盘IO已经或者还没蹦极。这种瞬间波动情况正好躲过了阿里云监控系统的监控,就好像CPU、硬盘IO和阿里云监控系统玩起了捉迷藏。
虽然问题只发生波动的瞬间,但确确实实多位用户遭遇了这个问题,这就是一种故障,是故障就要找出原因。我们不害怕问题,害怕的是不明不白的问题。
于是,我们将分析情况通过工单反馈给了阿里云。
一段时间之后,阿里云客服的回复终于让真相大白:在那段时间,云服务器所在的物理机出现了硬件故障,后来紧急修复了故障。