第1章 HTTP服务介绍
1.1 简述用户访网站流程
a 进行域名信息的DNS解析 dig +trace 获得www.oldboyedu.com ip地址信息 b 进行与网站服务器建立连接,tcp三次握手过程 (syn ack SEQ ACK/状态转换 closed listen syn_sent syn_rcvd established ) c 和网站服务器数据传输过程(http协议原理过程-http请求过程) 查看方法curl -v/wget --debug d 和网站服务器数据传输过程(http协议原理过程-http响应过程) e 进行与网站服务器断开连接,tcp四次挥手过程 (fin ack SEQ ACK/状态转换 fin_wait1 fin_wait2 close_wait last_ack time_wait closing )
1.1.1 DNS解析原理
01. 查看本地主机缓存和hosts文件有没有域名与IP对应记录 02. 本地主机向local DNS服务器(网卡上指定配置的DNS服务器)发出请求(递归查询) 03. LOCAL DNS服务器接收到客户端主机请求,查询本地缓存信息 04. LOCAL DNS服务向根域名服务器请求,向顶级域名服务器请求,向二级域名服务器请求(迭代查询) 05. 获取到域名与IP地址的对应关系,是通过授权DNS服务中获取得到(得到的信息称为A记录) LOCAL DNS服务进行缓存A记录信息,将A记录信息发送给客户端主机 06. 客户端主机接收到A记录信息,进行本地缓存,根据A记录中记录IP地址信息,进行网络访问
1.1.2 dns树状结构图
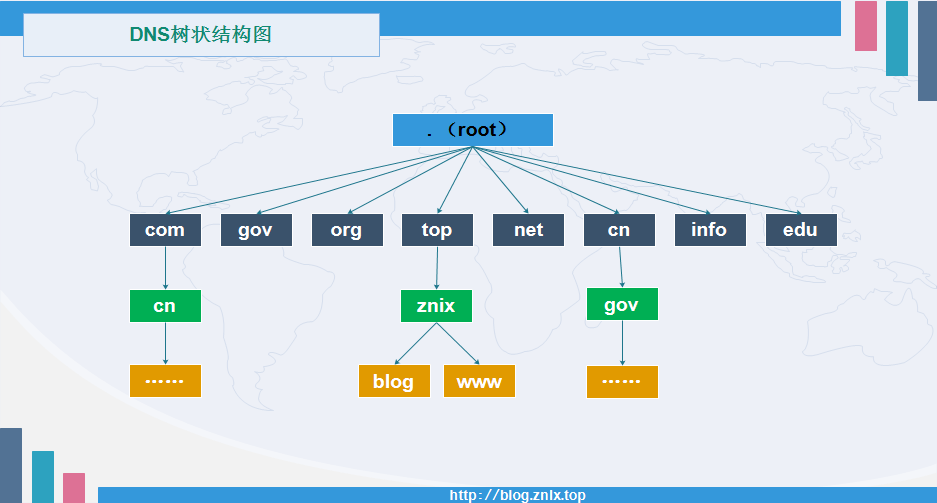
1.1.3 DNS域名解析,获悉域名对应IP地址(windows)
査看有关DNS信息方法(windows主机上):
1> 査看windows客户端本地缓存的DNS解析记录的命令如下。
c:>ipconfig /displaydns <-意思是display the contents of the DNS Resolver (显示DNS CACHE内容),"/displaydns"前面有空格
2> 清除windows客户端本地缓存的DNS解析记录的命令如下。
c:>ipconfig /flushdns <-意思为Purges the DNS Resolver cache" (清除DNS CACHE内容),"/displaydns"前面有空格
3> windows系统下hosts域名解析记录的位置如下。
c:Windowssystem32driversetchosts
1.1.4 linux上实现DNS缓存
nscd bind dnsmasq
关于BIND服务的使用可以参照:http://www.cnblogs.com/clsn/p/8424274.html
1.2 HTTP协议知识介绍
1.2.1 什么是HTTP协议
HTTP协议,全称HyperText Transfer Protocol,中文名为超文本传输协议,是互联网中最常用的一种网络协议。 HTTP的重要应用之一是 WWW服务。设计 HTTP协议最初的目的就是提供一种发布和接收HTML (一种页面标记语言)页面的方法。
HTTP协议是互联网上常用的通信协议之一。它有很多的应用,但最流行的就是用于Web浏览
器和Web服务器之间的通信,即WWW应用或称Web应用。
www ,全称World Wide Web ,常称为Web ,中文译为"万维网:它是目前互联网上最受用户欢迎的信息服务形式。 HTTP协议的 WWW服务应用的默认端口为80,另外一个加密的WWW服务应用https的默认端口为443,主要用于网银、支付等和钱相关的业务。当今,HTTP服务、WWW服务、Web服务三者的概念已经混淆了,都是指当下最常见的网站服务应用。
1.2.2 HTTP协议版本
HTTP/1.0 规定浏览器和服务器只保持短暂的连接(TCP短链接)
HTTP/1.1 支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和时间延迟(TCP长连接)
1.3 http协议原理过程
再linux系统中参看报文的方法
curl -v ---显示访问域名请求报文与响应报文信息
curl www.baidu.com -v
> 表示http请求报文 <表示http的响应报文
wget --debug www.baidu.com
1.3.1 响应http请求方法
|
HTTP方法 |
作用描述 |
|
GET |
客户端请求指定资源信悤,服务器返回指定资源 |
|
HEAD |
只请求响应报文中的 HTTP首部 |
|
POST |
将客户端的数据提交到服务器,例:注册表单 |
|
PUT |
用从客户端向服务器传送的数据取代指定的文档内容。 |
|
DELETE |
请求服务器删除 Request-URI所表示的资源。 |
|
MOVE |
请求服务器将指定的页面移至另一个网络地址。 |
1.3.2 http请求过程
|
HTTP请求报文格式 |
||
|
请求报文格式 |
报文信息 |
说明 |
|
请求行 |
GET / HTTP/1.1 |
请求的起始行(请求什么信息;协议版本) |
|
请求头 |
User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2 Host: www.baidu.com Accept: */* |
请求的头部信息(客户端有关信息说明) |
|
空行 |
|
空行信息(隔离上下文,说明请求结束) |
|
请求报文主体 |
|
请求主体内容(只有POST 方法可以提交主体) |
1.3.2.1 请求头信息说明
|
请求头内容 |
说明 |
|
Host |
接受请求的服务器地址,可以是IP:端口号,也可以是域名 |
|
User-Agent |
发送请求的应用程序名称 |
|
Connection |
指定与连接相关的属性,如Connection:Keep-Alive |
|
Accept-Charset |
通知服务端可以发送的编码格式 |
|
Accept-Encoding |
通知服务端可以发送的数据压缩格式 |
1.3.3 http响应过程
|
HTTP响应报文格式 |
||
|
请求报文格式 |
报文信息 |
说明 |
|
起始行(响应行) |
HTTP/1.1 200 OK |
响应的起始行(响应状态码 状态信息) |
|
响应头部 |
Server: bfe/1.0.8.18 Date: Mon, 23 Oct 2017 02:50:36 GMT Content-Type: text/html Content-Length: 2381 Last-Modified: Mon, 23 Jan 2017 13:27:32 GMT Connection: Keep-Alive ETag: "588604c4-94d" Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform Pragma: no-cache Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/ Accept-Ranges: bytes |
响应的头部信息(服务器有关信息介绍) |
|
空行 |
|
空行信息(隔离上下文,说明响应头部结束) |
|
响应报文主体 |
<!DOCTYPE html> …… |
响应主体的内容(请求后进行响应的返回的内容 信息) |
1.3.3.1 响应头信息说明
|
响应头 |
说明 |
|
Server |
服务器应用程序软件的名称和版本 |
|
Content-Type |
响应正文的类型(是图片还是二进制字符串) |
|
Content-Length |
响应正文长度 |
|
Content-Charset |
响应正文使用的编码 |
|
Content-Encoding |
响应正文使用的数据压缩格式 |
|
Content-Language |
响应正文使用的语言 |
1.4 HTTP协议状态码
HTTP状态码(HTTP Status Code )是用来表示Web服务器响应HTTP请求状态的数字代码。每当Web客户端向Web服务器发送一个HTTP请求时,Web服务器都会返回一个状态响应代码。这个状态码是一个三位数字代码,作用是告知Web客户端此次请求是否成功,或者是否要采取其他的动作方式。
1.4.1 HTTP协议状态码介绍
curl -v www.oldboyedu.org ---可以获取状态码信息
******************************************************************** 扩展命令说明:通过curl命令只获取状态码信息 curl -I www.nmtui.com|awk 'NR==1{print $2}' curl -I -s www.nmtui.com |awk 'NR==1{print $2}' curl -I -s -w %{http_code} www.nmtui.com curl -I -s -w %{http_code} -o /dev/null www.nmtui.com curl -I -s -w "%{http_code} " -o /dev/null www.nmtui.com curl -s -w "%{http_code} " -o /dev/null www.nmtui.com curl -I -s www.nmtui.com|head -1 curl -I 10.0.0.7 2>/dev/null|head -1 ********************************************************************
1.4.2 不同范围的状态码及其对应的作用
|
状态码范围 |
作用描述 |
|
100 - 199 |
用于指定客户端相应的某些动作 |
|
200 - 299 |
用于表示请求成功 |
|
300 - 399 |
用于己经移动的文件,并且常被包含在定位头信息中指定新的地址系信息 |
|
400 - 499 |
用于指出客户端的错误 |
|
500 - 599 |
用于指出服务端的错误 |
1.4.3 常见的状态码
|
代码 |
代码说明 |
|
301 Moved Permanently(永久跳转) |
请求的网页已永久跳转到新位置 |
|
403 Forbidden(禁止访问) |
服务器拒绝请求 |
|
404 - Not Found, |
服务器找不到请求的页面 |
|
500 |
内部服务器错误 |
|
502 |
坏的网关,一般是网关服务器请求后端服务时,后端服务没有按照http协议正确返回结果 |
|
503 - Service Unavailable (服务当前不可用) |
可能因为超载或停机维护 |
|
504 - Gateway Timeout (网关超时) |
一般是网关服务器请求后端服务时,后端服务没有在特定的时间内完成服务。 |
第2章 HTTP资源
2.1 媒体资源
互联网上的数据有很多不同的类型,Web服务器会把通过Web传输的每个对象都打上MIME类型(即MIME type)的数据格式标签。最初设计MIME(Multipurpose Internet Mall Extension,多用途因特网邮件扩展)是为了解决在不同的电子邮件系统之间搬移报文时存在的问题.MIME在电子邮件系统中工作得非常好。后来,HTTP也支持了这个功能,用它来描述数据并标记不同的数据内容类型。
当Web服务器响应HTTP谪求时,会为每一个HTTP对象数据加一个MIME类型,当Web浏览器获取到服务器返回的对象时,会去査看相关的MIME类型,并进行相应处理。
MIME类型存在与HTTP响应报文的响应头部信患里,它是一种文本标记,表示一种主要的对象类型和一个特定的子类型,中间由一条斜杠来分割。
2.1.1 MIME媒体资源
web服务可以处理的资源类型,根据扩展名进行识别(html css mp4)
2.1.2 url/uri
url:URL,全称为Uniform Resource Location,中文翻译为统一资源定位符
uri:URI,全称为Uniform Resource Identifier,中文翻译为统一资源标识符
URN:统一资源名称 (Uniform Resource Name, URN),是URI两种形式之一。
QPS: 每秒钟处理完请求的次数;注意这里是处理完。具体是指发出请求到服务器处理完成功返回结果。可以理解在server中有个counter,每处理一个请求加1,1秒后counter=QPS。 TPS:每秒钟处理完的事务次数,一般TPS是对整个系统来讲的。一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能会对应多个请求,对于衡量单个接口服务的处理能力,用QPS比较多。 并发量:系统能同时处理的请求数 RT:响应时间,处理一次请求所需要的平均处理时间 计算关系: QPS = 并发量 / 平均响应时间 并发量 = QPS * 平均响应时间
例如
网址: http://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com/ http://reg.jd.com --- 称为url /reg/person?ReturnUrl=https%3A//www.jd.com/ --- 称为uri
说明:nginx软件识别url和uri的方式和上面说明一致
2.2 网页资源种类
静态网页资源
动态网页资源
伪静态网页资源
2.2.1 静态网页资源
请求响应信息,发给客户端进行处理,由浏览器进行解析,显示的页面称为静态页面
在网站设计中,纯粹HTML格式的网页(可以包含图片、视频JS (前端功能实现)、CSS (样式)等)通常被称为"静态网页"
静态页面资源特征
01. 处理文件类型:如.html、jpg、.gif、.mp4、.swf、.avi、.wmv、.flv等-
02. 地址中不含有问号"?"或&等特殊符号。
03. 保存在网站服务器文件系统上的,是实实在在保存在服务器上的文件实体
04. 网页内容是固定不变的,因此,容易被搜索引擎收录
05. 网页页面交互性交差,因为不能与数据库配合
06. 网页程序在用户浏览器端解析,当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析)
优势:
01. 访问的效率比较高
02. 网页内容是固定不变的,因此,容易被搜索引擎收录
03. 网页程序在用户浏览器端解析,当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析)
劣势:
01. 网页页面交互性交差,因为不能与数据库配合
02. 保存在网站服务器文件系统上的,是实实在在保存在服务器上的文件实体
2.2.2 动态网页资源
所谓的动态网页是与静态网页相对而言的,也就是说,动态网页的URL后缀不是.html .htm、.xml、.shtml、.js css 等静态网页的常见扩展名形式,而是.asp、.aspx、.php、.js、.do、.cgi等形式
请求响应信息,发给屎务端进行处理,由服务端处理完成,将信息返回给客户端,生成的页面称为动态页面
动态网页资源特点
01. 网觅扩展名后缀常见为:.asp、.aspx、.php、.js、.do、.cgi
02. 网页页面交互性强,可以与数据库配合
03. 地址中含有问号"?"或 & 等特殊符号
04. 不便于被搜索引擎收录
优势:
01.客户端与服务端交互能力强
劣势:
01.访问的效率比较低
02.不便于被搜索引擎收录
2.2.3 伪静态网页资源
将动态页面伪装成静态页面,便于被搜索引擎收录
将动态页面转换为静态页面的方式(rewrite 正则表达式)
将动态页面内容转换为静态页面,去掉动态页面uri地址中的? &字符,伪装成静态页面uri信息
动态转静态(开发来配合完成)
2.3 网站流量度量术语
2.3.1 独立IP数度量值
独立IP数是指不同IP地址的计算机访问网站时被计算的总次数
在一个局域网内多个主机进行访问相同的网站地址时,独立IP数记为多少?
一般一天内(00:00-24:00)相同IP地址的客户端访问网站页面只会被计一次
记录独立IP的时间可为一天或一个月,目前通用的标准为"一天"。
2.3.2 页面浏览次数PV
页面浏览量或点击量
2.3.3 独立访客数UV
根据http请求报文:浏览器版本,OS
根据http响应报文:cookie(id)
cookie(id) 将服务端的信息保存到客户端
session 将客户端信息保存到服务器
2.3.4 【扩展知识】cookie和session区别
2.3.4.1 cookie介绍说明
cookie 存放在浏览器缓存中---浏览器进行查看(谷歌)
【设置里面】---【显示高级设置】---【隐私设置】---【内容设置】---【所有cookie和内容设置】
PS:cookie的格式信息是由开发人员进行定义,所以不同的网站所生成的cookie信息内容不太一致
cookie 数据存放在客户的浏览器上
cookie 不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
cookie 不占用服务器端资源,提升了服务器性能
cookie 保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
2.3.4.2 session介绍说明
session 存放在服务器的内存中
session 数据放在服务器上
session 从数据库的安全应用方面会更安全些
session 会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
2.3.4.3 建议性说明:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
2.4 IP PV UV 统计度量的方法
2.4.1 IP pv 统计度量的方法
1)利用awk或者相应统计命令,进行分析访问日志信息进行统计
2)在网站访问页面中嵌入统计程序代码(页面结尾处),只有全部网页加载完毕后,才进行数据统计
[root@tx ~]# curl -s www.nmtui.com|grep "hm.baidu" --color -C5 </script> <script> var _hmt = _hmt || []; (function() { var hm = document.createElement("script"); hm.src = "https://hm.baidu.com/hm.js?9aa800f882f575237396648643111698"; var s = document.getElementsByTagName("script")[0]; s.parentNode.insertBefore(hm, s); })(); </script> <script src="https://s95.cnzz.com/z_stat.php?id=1261663735&web_id=1261663735" language="JavaScript"></script>
说明:利用hm.baidu.com在页面curl时会出现,利用百度进行统计PV IP信息
利用第三方公认的统计工具进行统计,例如:百度统计工具 hm.baidu.com
2.4.2 UV统计度量的方法
通过客户端HTTP请求报文分析
通过Cookie信息鉴别统计
2.4.3 工作中常用的统计工具
网页信息统计软件-piwik pwiki统计工具:(https://piwik.org/) pwiki演示页面:https://piwik.org/demo
ELK软件介绍说明 http://blog.oldboyedu.com/elk/
2.5 网站并发连接说明
2.5.1 如何理解网站并发的概念
A种理解:网站服务器每秒能够接收的最大用户请求数。
B种理解:网站服务器每秒能够响应的最大用户请求数。
C种理解:网站服务器在单位时间内能够处理的最大连接数。(推荐)
ss -lntup|grep 80 netstat -lntup|grep 80
2.5.2 网站并发概念举例说明
饭店吃饭/酒店住宿举例
我们去餐馆吃饭(如图6-6所示),餐馆里一共有10张卓,每张桌最多坐4个人同时吃饭,那么按一般人的理解,这个餐馆能够接收的并发吃饭人数为10M ,即40个并发,其实这里就没有考虑时间问题,1秒并发可以是40个,10分钟内并发也是40个。因为这里还有一个因素,就是每个人吃饭时长的问题,如果平均每个人10分钟吃完,那么可以说10分钟内,这个餐馆的并发为40个,而不是每秒钟并发40个,因为,第一秒可以是40个人同时进来,但是第二秒就无人可进了(满员了),如果说10分钟并发是40个,下一个10分钟还是40个,第三个10分钟还可以是40个。即网站服务器在单位时间内能够处理的最大连接数。
高速公路通车举例说明
高速公路每个方向都有两条车道,那么,同一时刻并发的车辆为两辆,并且并发可以永远为2 ,如果按秒计算,每秒的并发可能就有十几辆,这个例子和餐馆不同,因为高速路处理并发不需要处理时间。但是对于Web服务器来讲,是需要花费时间处理请求的,这个请求可能是1秒或数秒,因此说,并发不应该只是用户访问的请求数,而应是服务器同时处理的并发数,并且单位时间不一定是1秒,可能是一个连接处理周期内的连接数。
2.5.3 网站并发统计计算方法
netstat -an|grep -i “est”|wc -l ss -ant|grep -ic est
说明: 在 nginx web服务中相应的软件模块进行统计
2.5.4 统计公式说明
例如:某网站的并发是5000。意味着单位时间内(理解为1秒或数秒内),正在处理的连接数,正在建立的连接数,加起来一共是5000个。
下面是国外学者对网站并发数的计算公式及参考说明:
Request Per Second + Simultaneous Browser connections + Thinking Time = Concurrent User
其中:
Concurrent User 表示网并发用户总数一
Request Per Second[RPS]表示每秒请求数(吞吐量
Simultaneous Browser connections[SBC]表示并发浏览连接数。
Thinking Time表示平均用户思考时间。
2.5.1 有关网站度量Linux企业运维问题
常见的面试题如下:
1)请问你如何理解网站并发?
2)你们公司网站访问量是多少?是怎么计算的?
—定要理解IP、PV、并发量这3个点的知识,在回答时才能有的放矢,这三个点的多少决定面试时说多大的架构,对于没有经验的新手不能在介绍有几万PV的同时描述数十台的集群架构,这样就尴尬了。
关于网站访问指标的计算,可以考虑:
运维部门的日志分析。
开发在页面嵌入的JS程序(用于统计、收集、分析)。
运营市场通过第三方公司提供的工具进行统计,例如GA统计。
2.6 知名网站访问量信息参考
|
网站 |
独立IP万/曰 |
PV数万/日 |
网站并发级别 |
机器数量 |
|
www.51cto.com |
582'000 |
1'338,600 |
10000 |
数十台 |
|
www.ganji.com |
1’734'000 |
13,872,000 |
10000-30000 |
几百台 |
|
www.58.com |
1398'000 |
22,927,200 |
10000-30000 |
几百台 |
|
www.weibo.com |
30’180'000 |
166'593’600 |
几十万 |
千台 |
|
www.taobao.com |
46,620'000 |
489,510,000 |
几十万~百万 |
万台 |
|
www.jd.com |
6'08'000 |
98,949,600 |
数万 |
千台 |
|
www.163.com |
10'320'000 |
79,154,000 |
十万 |
千台 |
|
www.suning.com |
623,250 |
3,365,550 |
10000-30000 |
百台 |
2.7 HTTP协议
所有的协议,都是为软件提供服务的
利用HTTP协议的软件,称为www服务软件或者web服务软件
2.7.1 web服务软件分类
2.7.1.1 静态解析web服务软件
Apache:这是中小型Web服务的主流,Web服务器中的老大哥。
Nginx:大型网站Web服务的主流,曾经Web服务器中的初生牛犊,现已长大。
Nginx的分支Tengine(http://tengine.taobao.org/)目前也在飞速发展。
Lighttpd:这是一个不温不火的优秀Web软件,社区不活跃,静态解析效率很高。
在Nginx流行前,它是大并发静态业务的首选,
国内百度贴吧、豆瓣等众多网站都有Lighttpd奋斗的身影。
2.7.1.2 动态解析web服务软件
PHP(FastCGI):大中小型网站都会使用,动态网页语言PHP程序的解析容器。它可配合Apache解析动态程序,
不过,这里的PHP不是FastCGI守护进程模式,而是mod_php5.so(module)。也可配合Nginx解析动态程序,此时的PHP常用FastCGI守护进程模式提供服务。
Tomcat:中小企业动态Web服务主流,互联网Java容器主流(如jsp、do)。
Resin:大型动态Web服务主流,互联网Java容器主流(如jsp、do)。
IIS(Internet information services):微软windows下的Web服务软件(如asp、aspx)
2.7.2 web服务软件官方资料整合:
apache:http://www.apache.org/ nginx: http://www.nginx.org/ Resin: http://www.caucho.com/download http://caucho.com/resin-3.1/doc/ http://caucho.com/resin/doc/install-apache.xtp Tomcat:http://tomcat.apache.org/whichversion.html http://tomcat.apache.org PHP: http://php.net