note:
-
最小环
-
是枚举已有的最短路和k点连接的两条边, 保证三个点不重合。
for(R int k = 1; k <= n; k ++) {
for(R int i = 1; i < k; i ++)
for(R int j = i + 1; j < k; j ++) {
if(e[i][j] < 1e9)
ans = min(ans, a[i][k] + a[k][j] + e[i][j]);
}
-
矩阵乘法不代表( ext{floyed, floyed})在于枚举一个新点,用其他点经过这个点的路径来更新最短路。矩阵乘法中的乘法的(k)是枚举一个中间点,使得两个图中的路径可以连接。同时, 本题经过(n)条边的最短路事实上是严格可以经过(n)条边的,这也是为什么这题看起来做了(log_n)次但是却看起来实现了个和( ext{floyed})差不多的玩意。
-
( ext{Dijkstra}) 解决负权边问题
先建出(0)号点, 向所有点连一条边权为(0)的边,防止图不连通,然后从(0)号点开始用( ext{spfa})跑出所有点的最短路, 然后对于每一条边((u, v)), 加上权值(dis[u] - dis[v]), 由于(dis[u] + w >= dis[v]),所以每条边的权值在修改后会大于0.按照这个方法直接跑( ext{dijskra}),最后的结果加上(dis[end] - dis[start])即可。注意判负环的时候由于新加入了一个点,要到访问次数(>=n +1)的时候退出。
-
卡SPFA
-
差分约束 : (dis[a]+w[i]>=dis[b]))
-
带权并查集
在合并以前进行路径压缩,则(x)点直接指向(rt_x),(y)点直接指向(rt_y),若要把(x)合并到(y)上, 设(k)为(x)和(y)之间的距离, 有(d_{x -> fx} + d_{fx -> fy} = k + d_{y -> fy}),所以可以求出(d_{fx->fy}),直接更新即可。在路径压缩的时候, (d[x] += d[tmp]),(tmp)是路径压缩以前的父节点。所以事实上,一个点的(d)值, 描述的是这个点到这个点的父节点的距离而不是到根的距离。所以带全并查集在查询之前应先对点进行路径压缩。
inline int find(int x) { if(x != fa[x]) { int tmp = fa[x]; fa[x] = find(fa[x]); dep[x] = (dep[x] + dep[tmp] + 3) % 3; } return fa[x]; } -
拓扑排序相关题目反过来建图有奇怪的好处。
-
长链剖分
- 解决(k)级祖先时, 在所有长链的链头存下,由于(k)级祖先所在长链的长度必定大于等于(k),取$2^r <= k $且(2^{r + 1}> k),当前点的(2^r)次祖先所在的长链长度必定大于(2^r), 所以可以在(vector)上直接确定(k)级祖先。预处理倍增即可。
- 优化(dp)的时候利用指针继承重儿子数组, 然后听说复杂度(O(n)),先把(dp)学好再搞。[POI2014]HOT-Hotels
-
欧拉路 & 欧拉回路
-
欧拉路直接从奇点(dfs)完事。
-
欧拉回路从任意一点开搜, (dfs)的时候及时修改表头, 防止复杂度退化, 同时标记已经访问的边, 在回溯的时候把点压到栈中, 倒序输出即可获得点序列。魔改一下就是边序列。
-
-
双连通分量
- 关于点双,两个情况
- 当(x != rt), 当( ext{dfs})树上点(y)的子树无法指向(x)以上的点, 则(x)是割点, 即(low[y] >= dfn[x])。
- 当(x == rt), 当(x)有两棵以上子树的时候,这是割点。
- 关于边双,( ext{dfs})的时候存一条边防止访问到父节点,当(low[y] > dfn[x])则为割边。
- 关于点双,两个情况
-
仙人掌
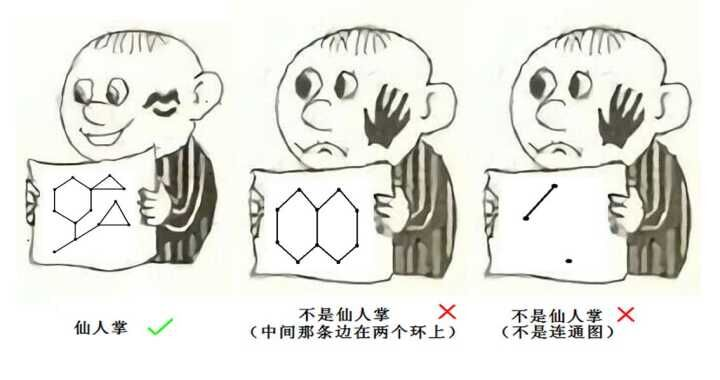
-
仙人掌图的判定
-
仙人掌首先是个强连通图, 所以先跑( ext{tarjan}), 然后在( ext{dfs})的时候可能会有返祖边, 这个时候就是找到了一个环, 对这个环暴力打标记, 如果打了两次以上立刻退出, 显然复杂度是(O(n + m))的。模板 (有点问题)
- 咕咕
-
圆方树
-
暴力对每个点双建树就完了。注意出栈的判定。
-
一点性质就是可以用方点保存整个点双的信息。
-
可以考虑方点只维护儿子圆点的权值。
-
while(1) { int v = stk[tp]; add(v, tot); add(tot, v); tp --; if(v == y) break; } -
-
2-SAT
-
考虑拆点, 如果一个状态选了, 另一个状态必选, 就从这个状态向另一个状态连边。
-
如果两个冲突点在一个强连通分量里, 无解
-
对于每一组拆开的点,选择拓扑序较大的那个点, 也就是强连通分量标号较小的那个点, 因为选了拓扑序小的就一定要选所有和它相连的可能就会要求选大的, 但是选了大的一定不会对小的造成影响。也就是说这样一定可以构造出一组合法的解。
-
对于要求答案字典序的话可以使用(dfs),从而做到(O(n(n +m))).
-
-
匹配
-
匈牙利算法
-
Hall定理
-
-
网络流
-
最大流
- 注意(bfs)的时候重置(cur)数组。
- (bfs)的时候要当当前点未访问过且当前边有流量再扩展
- (dfs)的时候及时更新表头(cur)数组
- 初始的时候(cnt)设为1方便改反向边流量
- (dfs)的时候要求下一个点是下一层且走这条边有流量才更新, 当前点限制满了以后直接退出。
-
最小费用最大流
- 每次从(S)点开始跑(spfa)
- 可以更新最短路且这条边有流量的时候更新,更新的时候记录前驱点, 这条边, 更新(y)处的流限制。
- 跑出路以后, 先给费用加上流乘距离, 然后从汇点开始倒推, 正向边减,反向边加即可。
- 注意建边的时候反向边的权值为负
-
无源汇有上下界可行流
- 先把下界流满, 然后建立虚拟源点向流入量大于流出量的点连边权为这个差的边, 流入量小于这个点的流出量的点向汇点连边, 边权为这个差的相反数, 然后跑最大流。此时跑最大流时边权的限制就是上界减去下界。如果跑满了,也就是和源点相连的点都满流了, 答案就是最大流加上这条边的下界。
-
有源汇有上下界最大/小流
- 从汇点向源点连容量巨大边, 转化为上者。
- 求最大流就跑最大流, 最小流就跑反过来的最大流, 用下界和减去这个流, 求最大流的时候就是用下界和加上这个流。
-