共享存储功能支持无限并发扩展,同时 Redshift 的实例存储功能支持低延迟访问无法通过其他方式访问的数据。 这两个策略的独特组合使得 Redshift 目前具备一流的性能,并能在日后不断改进。
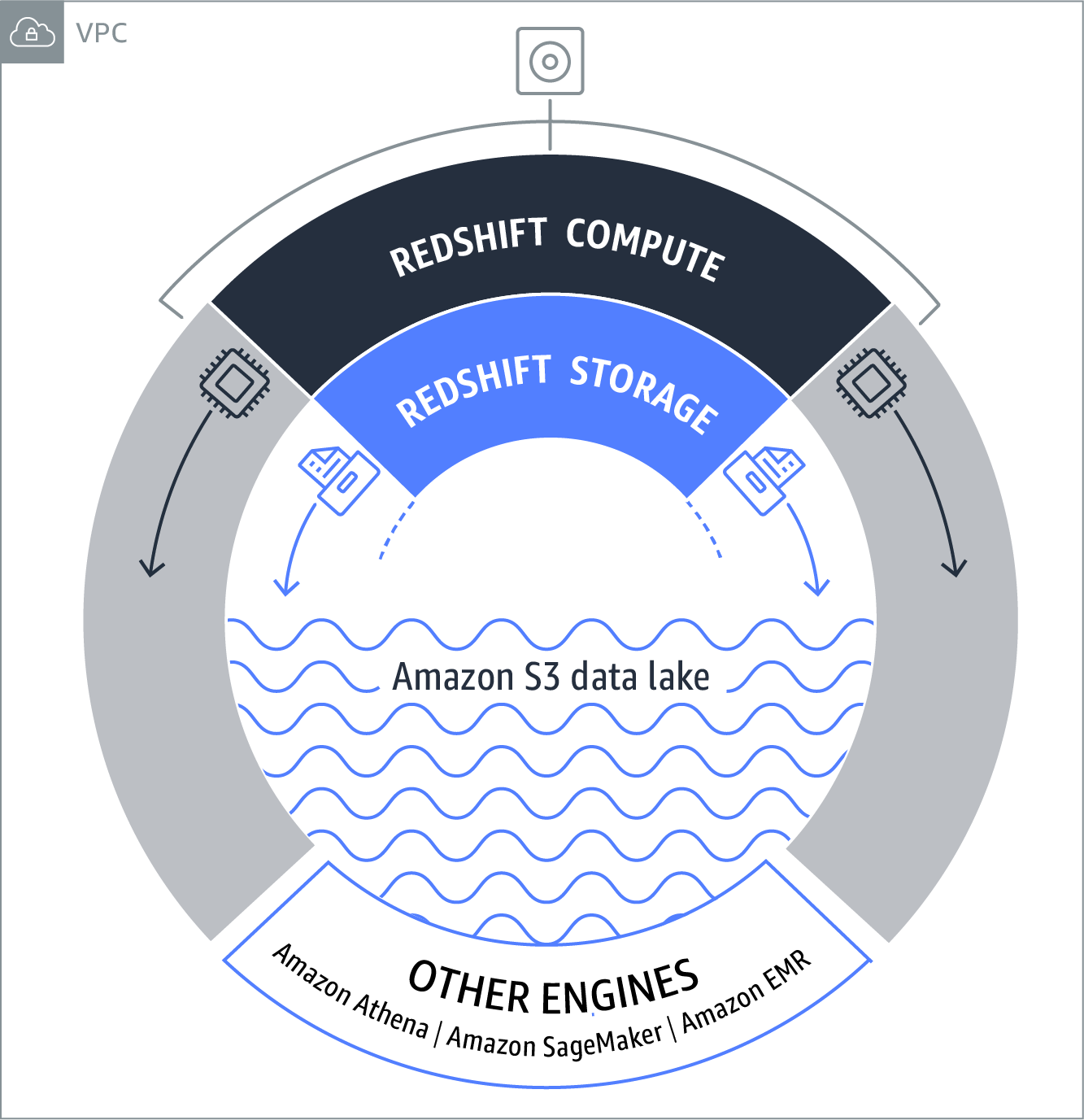
Amazon Redshift 将数据仓库查询扩展到您的数据湖,无需加载。您可以针对 Redshift 中本地存储的 PB 级数据运行分析查询,以及直接针对 Amazon S3 中存储的 EB 级数据运行分析查询。设置和自动执行大多数管理任务以及在任意规模中提供快速性能都非常简单。
Amazon S3 数据湖:Amazon Redshift 是将您的查询扩展到 Amazon S3 数据湖而无需加载数据的唯一数据仓库。您可以直接在 S3 中查询已使用的开放文件格式,例如 Avro、CSV、Grok、JSON、ORC 和 Parquet 等。
AWS 分析生态系统:Amazon Redshift 与 AWS 分析生态系统进行原生集成。AWS Glue 可以将数据提取、转换和加载 (ETL) 到 Redshift 中。Amazon Kinesis Data Firehose 是捕获、转换流数据并将其加载到 Redshift 以实现近乎实时分析的一种简单方式。您可以使用 Amazon QuickSight 创建报告、可视化和控制面板。 为了加速向 Amazon Redshift 的迁移,您可以免费使用 AWS Database Migration Service (DMS) 六个月。
Redshift Spectrum 是 Amazon Redshift 的一项功能,借助这项功能,您可以对 Amazon S3 中 EB 级非结构化数据运行查询,而无需进行加载或 ETL 操作。当您发布查询时,查询会进入 Amazon Redshift SQL 终端节点,该终端节点会生成查询方案并对其进行优化。Amazon Redshift 会确定哪些数据存储在本地以及哪些数据存储在 Amazon S3 中,然后生成一种方案来尽可能减少需要读取的 Amazon S3 数据量,从共享资源池中请求 Redshift Spectrum 工作线程来读取和处理 Amazon S3 中的数据。
Amazon Redshift 使用各种创新技术,与传统的数据仓库存储及分析用数据库相比,其性能提高将近十倍:
- 列式数据存储:Amazon Redshift 以列组织数据,并非以一系列的行来存储数据。与适用于事务处理的基于行的系统不同,基于列的系统适用于数据仓库存储及分析,在此系统中,查询经常涉及到对大型数据集进行聚合。由于仅对涉及查询的列进行处理,且列式数据按顺序存储在存储介质上,故基于列的系统所需的 I/O 要少得多,从而显著提高了查询性能。
- 高级压缩:与基于行的数据存储相比,列式数据存储可进行更大程度的压缩,因为类似的数据是按顺序存储在硬盘上。Amazon Redshift 拥有多种压缩技术,与传统的关系数据存储相比,通常可进行较大程度的压缩。此外,与传统的关系数据库系统相比,Amazon Redshift 不需要索引或具体化视图,因此使用的空间较少。将数据加载到空表中时,Amazon Redshift 会自动对您的数据进行采样并选择最合适的压缩方案。
- 大规模并行处理 (MPP):Amazon Redshift 可以自动将数据与查询负载分配到所有节点。借助 Amazon Redshift,您可以轻松将节点添加至数据仓库,而且随着您的数据仓库规模的扩大,仍能维持快速的查询性能。
- Redshift Spectrum:借助 Redshift Spectrum,您可以对 Amazon S3 中的 EB 级数据运行查询,且无需进行加载或 ETL 操作。即使没有在 Amazon Redshift 中存储任何数据,您仍然可以使用 Redshift Spectrum 查询 Amazon S3 中的 EB 级数据集。当您发布查询时,查询会进入 Amazon Redshift SQL 终端节点,该终端节点会生成查询方案。Amazon Redshift 会确定哪些数据存储在本地以及哪些数据存储在 Amazon S3 中,然后生成一种方案来尽可能减少需要读取的 Amazon S3 数据量,从共享资源池中请求 Redshift Spectrum 工作线程来读取和处理 Amazon S3 中的数据,然后将结果返回 Amazon Redshift 群集进行任何剩余处理。
您可以使用 AWS 管理控制台或 Amazon Redshift API 轻松创建 Amazon Redshift 数据仓库群集。您可以从单节点 160GB 数据仓库开始,然后在 AWS 控制台中单击几下或调用一个 API,一路扩展到 1PB 或更大。
单节点配置使您能够开始经济快速地使用 Amazon Redshift,而且随着您的需求的增长,单节点配置可扩展为多节点配置。 一个 Redshift 数据仓库群集中可以包含 1 到 128 个计算节点,具体取决于节点类型。
- 多节点配置需要一个领导节点来管理客户端的连接并接收查询,以及两个计算节点来存储数据并执行查询和计算。系统将自动为您配置领导节点,并且您无需为其付费。仅需指定您的首选可用区(可选项)、节点数量、节点类型、主机名称和密码、安全组、您对备份保留期的首选项及其他系统设置。在您选定理想配置后,Amazon Redshift 将预置所需资源并建立数据仓库群集。
- 领导节点接收来自客户端应用程序的查询,分析查询并制定执行计划,是对查询进行处理的一套有序步骤。然后领导节点和计算节点协调这些计划的并行执行,聚合来自这些节点的中间结果,并将这些结果最终返回至客户端应用程序。
- 计算节点执行执行计划所规定的步骤,并在这些计划之间传输数据,从而为这些查询进行服务。中间结果会先被送回至领导节点进行聚合,然后才会被送回至客户端应用程序。
- 密集存储 (DS) 节点类型提供两种大小:超大型节点和八倍超大型节点。超大型节点 (XL) 有 3 个硬盘,总共 2TB 的磁盘存储,而八倍超大型节点 (8XL) 有 24 个硬盘,总共 16TB 的磁盘存储。DS2.8XLarge 有 36 个 Intel Xeon E5-2676 v3 (Haswell) 虚拟内核和 244GiB RAM,DS2.XL 有 4 个 Intel Xeon E5-2676 v3 (Haswell) 虚拟内核和 31GiB RAM。请参阅定价页面了解更多详细信息。您可从每小时 0.85 USD 的单个超大型节点 2TB 数据仓库开始,然后扩展至 1PB 或更大。您可按小时付费或使用预留实例定价,将价格降低到每年每 TB 不到 1000 USD。
- 密集计算 (DC) 节点类型也提供两种大小。大型节点具有 160GB 的 SSD 存储、2 个 Intel Xeon E5-2670v2 (Ivy Bridge) 虚拟核心和 15GiB 的 RAM。八倍超大型节点是大型节点的 16 倍,具有 2.56TB 的 SSD 存储、32 个 Intel Xeon E5-2670v2 虚拟核心和 244GiB 的 RAM。您可从每小时 0.25 USD 的单个 DC2.Large 节点开始,然后一路扩展至 128 个 8XL 节点,从而具有 326TB 的 SSD 存储、3200 个虚拟内核和 24TiB 的 RAM。
- Amazon Redshift 的 MPP 架构意味着可以通过增加数据仓库群集中的节点数来提升性能。每个计算节点的最佳数据量取决于您的应用程序特点和查询性能需求。一个 Amazon Redshift 数据仓库群集中可以包含 1 到 128 个计算节点,具体取决于节点类型。
尽管 Redshift Spectrum 非常适用于对 Amazon Redshift 和 S3 中的数据运行查询,但它真的不适合企业通常需要使用 Amazon EMR 之类的处理框架进行处理的使用案例类型。Amazon EMR 的功能远不止于运行 SQL 查询。Amazon EMR 是一种托管服务,可让您使用最新版本的常用大数据处理框架(如 Spark、Hadoop 和 Presto)在完全自定义的群集上处理和分析极大的数据集。借助 Amazon EMR,您可以为机器学习、图形分析、数据转换、流式处理数据以及您可以编写代码的几乎任何应用程序运行各种扩展的数据处理任务。
您可以将 Redshift Spectrum 与 EMR 配合使用。Redshift Spectrum 存储表定义的方式与 Amazon EMR 相同。Redshift Spectrum 可以支持 Amazon EMR 使用的相同 Apache Hive 元数据仓来查询数据和表定义。如果您使用的是 Amazon EMR 并拥有 Hive 元数据仓,则只需配置 Amazon Redshift 群集即可使用 Redshift Spectrum。然后,您可以马上开始查询这些数据和 Amazon EMR 任务。因此,如果您已经在使用 EMR 处理大型数据存储,则可同时使用 Redshift Spectrum 来查询这些数据,而不会影响 Amazon EMR 任务。
Amazon Athena 是让任何员工都能对 Amazon S3 中的数据运行临时查询的最简单方式。Athena 是无服务器服务,因此您无需设置或管理基础设施,即可立即开始分析数据。
如果您拥有需要以一致且高度结构化的格式进行存储的频繁访问数据,那么您应该使用 Amazon Redshift 之类的数据仓库。这样一来,您就可以在 Amazon Redshift 中灵活存储结构化的频繁访问数据,并使用 Redshift Spectrum 将 Amazon Redshift 查询扩展到 Amazon S3 数据湖中的所有数据。此外,您还可以灵活地将数据以您想要的格式存储在您想要的位置,并在需要时即时可用。
如果数据仓库群集的可用区 (AZ) 发生故障,那么对数据仓库群集可用性和数据持久性有何影响?
如果 Amazon Redshift 数据仓库群集的可用区无法使用,那么在 AZ 的电源及网络访问恢复之前,您将无法使用您的群集。数据仓库群集的数据将被保留下来,一旦 AZ 重新可供使用,那么您就能够开始使用 Amazon Redshift 数据仓库。此外,您也可选择将任何现有快照恢复到同一区域中的新 AZ 中。Amazon Redshift 将首先恢复您最频繁访问的数据,这样您就能尽快地恢复查询。
当前 Amazon Redshift 仅支持单一可用区部署。通过将数据从同一组 Amazon S3 输入文件加载到各个 AZ 中的两个 Amazon Redshift 数据仓库群集中,您便可在多个 AZ 中运行数据仓库群集。借助 Redshift Spectrum,您可以跨可用区运行多个群集,并访问 Amazon S3 中的数据,而无需将其加载到群集中。此外,您也可将数据仓库群集从数据仓库群集快照恢复至其他可用区。
在加载数据时,Amazon Redshift 会复制数据仓库群集内的所有数据并将其连续备份至 S3。Amazon Redshift 始终尝试维持至少三份数据(计算节点上的正本数据、副本数据和 Amazon S3 上的备份数据)。Redshift 还能将您的快照异步复制到另一个区域的 S3 中进行灾难恢复。默认情况下,Amazon Redshift 以一天的保留期启用数据仓库群集的自动化备份。您可将其配置为 35 天之久。免费备份存储受限于数据仓库群集中节点上的总存储大小,并仅适用于已激活的数据仓库群集。
如何管理自动备份及快照保留期?
您可以使用 AWS 管理控制台或 ModifyDBInstance API,通过修改 RetentionPeriod 参数来管理自动备份的保留时间段。如果您希望关闭自动备份,则可以通过将保留期设置为 0(不建议)来执行该操作。Elastic Resize 几分钟内即可在单个 Redshift 集群中添加或删除节点,以管理其查询吞吐量。例如,一天内某几个小时的 ETL 工作负载或月末报告可能需要额外 Redshift 资源才能按时完成。并发扩展会添加额外集群资源来提高整体查询并发量。
Redshift Spectrum 目前支持许多开源数据格式,其中包括 Avro、CSV、Grok、Ion、JSON、ORC、Parquet、RCFile、RegexSerDe、SequenceFile、TextFile 和 TSV。
Redshift Spectrum 目前支持 Gzip 和 Snappy 压缩。