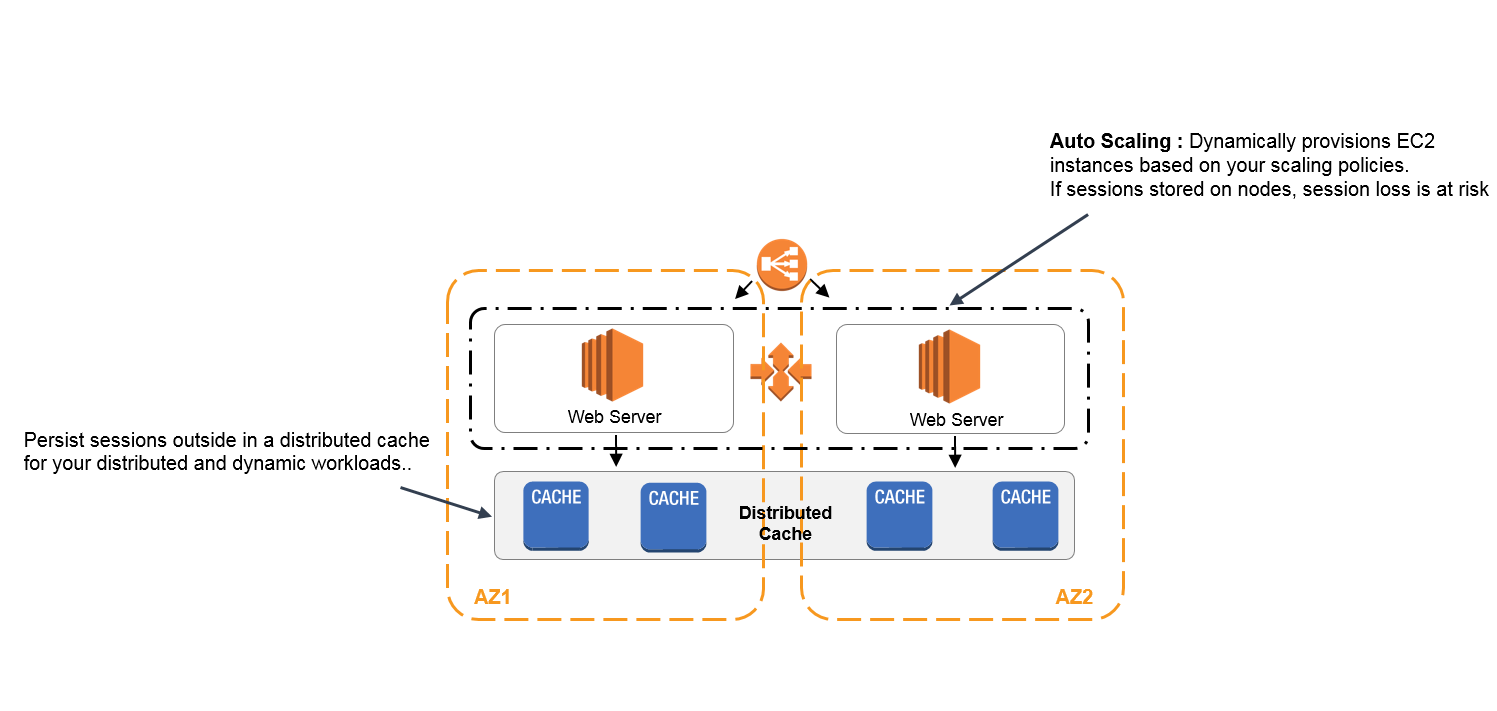
1,AWS session保护方案 ElastiCache
2,In Amazon Kinesis, the producers continually push data to Kinesis Data Streams and the consumers process the data in real time. Consumers (such as a custom application running on Amazon EC2, or an Amazon Kinesis Data Firehose delivery stream) can store their results using an AWS service such as Amazon DynamoDB, Amazon Redshift, or Amazon S3.

3,如何改进单个 Amazon Aurora 数据库的可用性?
您可以添加 Amazon Aurora 副本。同一 AWS 区域中的 Aurora 副本与主实例共享用一个底层存储。任何 Aurora 副本都可在不损失任何数据的情况下被提升为主实例,因此,它可用于在主数据库实例发生故障时提高容错能力。要想提高数据库可用性,只需在 3 个可用区的任何一个创建 1 到 15 个副本,且 Amazon RDS 将在发生数据库运行中断时将其纳入故障转移主选择中。
如果您希望数据库跨越多个 AWS 区域,可以使用 Aurora 全球数据库。这样可以在不影响数据库性能的情况下复制您的数据,并在区域范围的中断中提进行灾难恢复。
问:执行故障转移时会发生什么状况?这种情况会持续多长时间?
Amazon Aurora 会自动处理故障转移,以便您的应用程序可以尽快恢复数据库操作,而无需人工管理干预。
- 如果您在相同或不同的可用区中有 Amazon Aurora 副本,当进行故障转移时,Aurora 会翻转您的数据库实例的别名记录 (CNAME),以指向运行状态正常的副本;相应地,此副本会晋升为新的主实例。从开始到结束,故障转移通常会在 30 秒内完成。
- 如果您没有 Amazon Aurora 副本(即单个实例),则 Aurora 会先尝试在原始实例的可用区中新建数据库实例。如果不能这么做,则 Aurora 会尝试在不同的可用区中新建数据库实例。从始至终,通常会在 15 分钟内完成故障转移。
您的应用程序应在连接丢失时重试数据库连接。
跨区域进行灾难恢复是一个手动过程,在此期间,您可以提升辅助区域以获取读/写工作负载。
Amazon Aurora 副本与同一 AWS 区域内的主实例共享同一个数据卷,因此几乎没有复制滞后。据我们观察,滞后时间一般在 10 毫秒内。对于 MySQL 只读副本,复制滞后可根据更改/应用率以及网络通信的延迟无限增长。不过,一般情况下,1 分钟以内的复制滞后是很常见的。
对于使用逻辑复制的跨区域副本,其滞后时间会受到更改/应用速度以及所选区域之间的网络通信延迟情况的影响。使用 Aurora 全球数据库的跨区域副本通常有不到一秒的滞后时间。
4, S3 存储桶的命名规则:
-
存储桶名称在 Amazon S3 中的所有现有存储桶名称中必须唯一。
-
存储桶名称必须符合 DNS 命名约定。
-
存储桶名称的长度必须为至少 3 个字符,且不能超过 63 个字符。
-
存储桶名称不能包含大写字符或下划线。
-
存储桶名称必须以小写字母或数字开头。
-
存储桶名称必须是一系列的一个或多个标签。相邻标签通过单个句点 (.) 分隔。存储桶名称可以包含小写字母、数字和连字符。每个标签都必须以小写字母或数字开头和结尾。
-
存储桶名称不得采用 IP 地址格式(例如,192.168.5.4)。
-
当通过安全套接字 (SSL) 使用虚拟托管式存储桶时,SSL 通配符证书仅匹配不包含句点的存储桶。要解决此问题,请使用 HTTP 或编写自己的证书验证逻辑。在使用虚拟托管式存储桶时,建议您不要在存储桶名称中使用句点(“.”)。
5, shared responsibility model.

安全性和合规性是 AWS 与客户的共同责任。这种共担模式可以减轻客户的运营负担,因为 AWS 运行、管理和控制从主机操作系统和虚拟层到服务运营所在设施的物理安全性的组件。客户负责管理来宾操作系统(包括更新和安全补丁)、其他相关应用程序软件以及 AWS 提供的安全组防火墙的配置。
AWS 负责“云本身的安全” – AWS 负责保护运行所有 AWS 云服务的基础设施。该基础实施由运行 AWS 云服务的硬件、软件、网络和设备组成。
客户负责“云内部的安全” – 客户责任由客户所选的 AWS 云服务确定。这决定了客户在履行安全责任时必须完成的配置工作量。
6,AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务,让客户能够轻松准备和加载数据进行分析。您只需在 AWS 管理控制台中单击几次,即可创建并运行 ETL 作业。您只需将 AWS Glue 指向存储在 AWS 上的数据,AWS Glue 便会发现您的数据,并将关联的元数据(例如表定义和架构)存储到 AWS Glue 数据目录中。存入目录后,您的数据可立即供 ETL 搜索、查询和使用。
AWS Glue 为以下位置存储的数据提供原生支持:Amazon Aurora、Amazon RDS for MySQL、Amazon RDS for Oracle、Amazon RDS for PostgreSQL、Amazon RDS for SQL Server、Amazon Redshift 和 Amazon S3,以及 Amazon EC2 上运行的 Virtual Private Cloud (Amazon VPC) 中的 MySQL、Oracle、Microsoft SQL Server 和 PostgreSQL 数据库。您可以从 Amazon Athena、Amazon EMR 和 Amazon Redshift Spectrum 轻松访问存储在 AWS Glue 数据目录中的元数据。您还可以编写自定义 Scala 或 Python 代码,并在 Glue ETL 作业中导入自定义库和 Jar 文件,以访问 AWS Glue 原生不支持的数据源。
AWS Glue 编写 ETL 代码,使用 Scala 或 Python。
AWS Database Migration Service (DMS) 可帮助您轻松并安全地将数据库迁移至 AWS。如果需要将数据库从本地迁移至 AWS 或需要本地源与 AWS 上的源之间进行数据库复制,我们建议您使用 AWS DMS。一旦数据位于 AWS 中,您就可以使用 AWS Glue 将数据源中的数据移动到另一个数据库或数据仓库(比如 Amazon Redshift)中并进行转换。
7,Glacier is a cost-effective archival solution for large amounts of data. Bulk retrievals are S3 Glacier’s lowest-cost retrieval option, enabling you to retrieve large amounts, even petabytes, of data inexpensively in a day. Bulk retrievals typically complete within 5 – 12 hours. You can specify an absolute or relative time period (including 0 days) after which the specified Amazon S3 objects should be transitioned to Amazon Glacier.
Glacier has a management console which you can use to create and delete vaults. However, you cannot directly upload archives to Glacier by using the management console. To upload data, such as photos, videos, and other documents, you must either use the AWS CLI or write code to make requests, by using either the REST API directly or by using the AWS SDKs.
8,如果我的 Spot 实例中断,我将如何付费?
如果 Spot 实例在第一个小时内被 Amazon EC2 终止或停止,那么您无需支付使用费。但是如果您自己终止了实例,您就需要按使用秒数付费。如果 Spot 实例在第一个小时后的任何时间被 Amazon EC2 终止或停止,那么您需要按使用秒数付费。如果您在 Windows 上运行并且自己终止了实例,您就需要支付一整个小时的费用。
9,Amazon Elastic File System (EFS)
要访问您的文件系统,您需要使用标准 Linux 挂载命令和文件系统的 DNS 名称将文件系统挂载到基于 Linux 的 Amazon EC2 实例上。挂载完成后,您就可以像使用本地文件系统一样,使用您的文件系统中的文件和目录。Amazon EFS 使用 NFSv4.1 协议。
10,我无法使用 SSH 连接到 Amazon Elastic Compute Cloud (Amazon EC2) 实例,并且收到以下错误消息:“Server refused our key”。我如何解决此问题?
在以下情况下,您可能无法登录 EC2 实例:
- 您正在使用 SSH 私有密钥,但 authorized_keys 文件中没有相应的公有密钥。
- 您没有 authorized_keys 文件的权限。
- 您没有 .ssh 文件夹的权限。
- 您的 authorized_keys 文件或 .ssh 文件夹命名不正确。
- 您的 authorized_keys 文件或 .ssh 文件夹已被删除。
- 您的实例是在没有密钥的情况下启动的,或者是使用不正确的密钥启动的。
要在收到“Server refused our key”错误后连接到 EC2 实例,您可以更新实例的用户数据,将指定的 SSH 公有密钥附加到 authorized_keys文件,该文件用于为 SSH 目录和其中包含的文件设置适当的所有权和文件权限。
https://amazonaws-china.com/cn/premiumsupport/knowledge-center/ec2-server-refused-our-key/
11,AWS Trusted Advisor 是一个在线工具,可为您提供实时指导以帮助您按照 AWS 最佳实践预置资源。
AWS Trusted Advisor 提供了一组丰富的最佳实践检查和建议,涵盖以下五个类别:成本优化、安全性、容错能力、性能和服务限制。
https://amazonaws-china.com/cn/premiumsupport/technology/trusted-advisor/best-practice-checklist/
12,The default termination policy is designed to help ensure that your network architecture spans Availability Zones evenly. With the default termination policy, the behavior of the Auto Scaling group is as follows:
1. If there are instances in multiple Availability Zones, choose the Availability Zone with the most instances and at least one instance that is not protected from scale in. If there is more than one Availability Zone with this number of instances, choose the Availability Zone with the instances that use the oldest launch configuration.
2. Determine which unprotected instances in the selected Availability Zone use the oldest launch configuration. If there is one such instance, terminate it.
3. If there are multiple instances to terminate based on the above criteria, determine which unprotected instances are closest to the next billing hour. (This helps you maximize the use of your EC2 instances and manage your Amazon EC2 usage costs.) If there is one such instance, terminate it.
4. If there is more than one unprotected instance closest to the next billing hour, choose one of these instances at random.
默认终止策略
Auto Scaling 在发生缩减事件时使用的默认终止策略。默认终止策略旨在帮助确保在可用区之间平均分配实例,以获得高可用性。默认策略会保留通用性和灵活性,旨在满足各种场景的需要。
使用默认终止策略时,Auto Scaling 组的行为如下所示:
-
确定哪些可用区包含最多实例,并且至少有一个实例不受缩减保护。
-
[仅适用于Auto Scaling 组具有多个实例类型和购买选项]
确定要终止的实例,以便将剩余实例与要终止的按需或 Spot 实例的分配策略、当前选择的实例类型,以及在 N 个最低价格 Spot 池之间分配保持一致。如果有一个此类实例,则终止该实例。否则,应用下一个条件。
-
[适用于使用启动模板的 Auto Scaling 组]
确定是否有任何实例使用最旧的启动模板。如果有一个此类实例,则终止该实例。(请注意存在一个例外情况:如果组最初使用启动配置。Amazon EC2 Auto Scaling 会首先终止使用启动配置的实例,然后再终止使用最旧启动模板的实例。)
-
[适用于使用启动配置的 Auto Scaling 组]
确定是否有任何实例使用最旧的启动配置。如果有一个此类实例,则终止该实例。
-
在应用 2 到 4 中的所有条件后,如果要终止多个不受保护的实例,确定哪些实例最接近下一个计费小时。如果有一个此类实例,则终止该实例。(通过终止最接近下一个计费小时的实例,将帮助您最大程度地使用按小时计费的实例。)
自定义终止策略
-
OldestInstance。终止组中最旧的实例。当您将 Auto Scaling 组中的实例升级为新的 EC2 实例类型,此选项十分有用。您可以逐渐将较旧类型的实例替换为较新类型的实例。 -
NewestInstance。终止组中最新的实例。如果要测试新的启动配置但不想在生产中保留它时,此策略非常有用。 -
OldestLaunchConfiguration。终止采用最旧启动配置的实例。如果要更新某个组并且逐步淘汰先前配置中的实例时,此策略非常有用。 -
ClosestToNextInstanceHour。终止最接近下个计费小时的实例。此策略将帮助您最大程度地使用您的实例并管理 Amazon EC2 使用成本。 -
Default。根据默认终止策略终止实例。如果该组有多个扩展策略,此策略非常有用。 -
OldestLaunchTemplate。终止采用最旧启动模板的实例。利用此策略,会首先终止使用非当前启动模板的实例,然后终止使用当前启动模板的最旧版本的实例。如果要更新某个组并且逐步淘汰先前配置中的实例时,此策略非常有用。 -
AllocationStrategy。终止 Auto Scaling 组中的实例,使剩余实例与所终止实例类型的分配策略匹配(Spot 实例或按需实例)。当您首选的实例类型发生变化时,可使用该策略。您可以逐渐在 N 个最低价 Spot 池中重新平衡分布 Spot 实例。您也可以使用较高优先级类型的按需实例逐渐替代较低优先级类型的按需实例。