前言
本系列是笔者阅读Kafka经典书籍《Kakfa技术内幕》的笔记,对这份阅读笔记想写成什么样子有以下几个设想:
- 不是对书中内容的摘抄。因此想要对该书详细内容有更多了解的同学,可以自行购书翻阅。
- 每章或每节形成一张思维导图。目的是总结书中内容,构建自己的知识架构。
- 提炼问题并给出答案。答案尽量用自己组织的语言通俗易懂的表达出来,而非复制粘贴。
第1章 Kafka 入门
思维导图
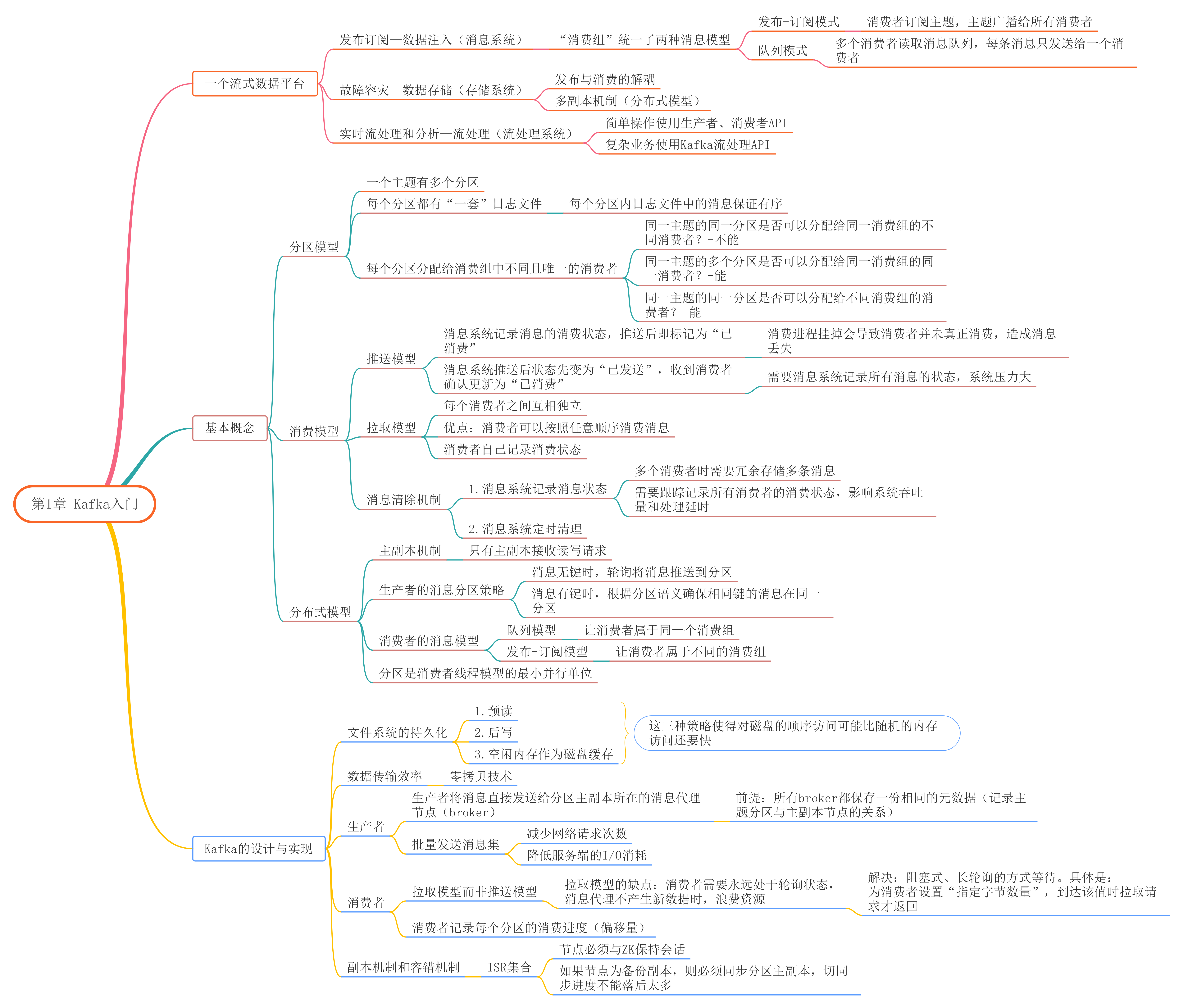
问题思考
Kafka的主题与分区内部是如何存储的,它有什么特点?(分区模型)
Kafka集群为每个主题维护了分布式的分区日志文件,物理意义上把主题看作分区的日志文件。
特点:
- 每个分区内的日志文件中的消息保证有序。
- 对同一消费组来说,同一主题的每个分区只会分配给的消费组中唯一的一个消费者。
- 分区是消息处理的并行单元,是Kafka中消息处理的最小粒度。
与传统的消息系统相比,Kafka的消费模型有什么优点?(消费模型)
Kafka的消费模型是“拉取模型”,传统的消息系统是“推送模型”。优点:
- 推送模型要求消息代理记录消息的消费状态,如果采用消息代理推送消息后即将消息的状态更新为“已消费”,则有可能在消费者挂掉的情况下导致消息丢失;如果消息代理在发送之后先更新为“已发送”,需要在接收到消费者的确认消息之后才将消息的状态更新为“已消费”,这就需要消息代理不仅记录消息的状态,还需要跟踪处理来自消费者的确认请求,使得消息代理的系统压力增大。
- 拉取模型使得各个消费者之间互相独立,各自管理自己的消费状态。
- 拉取模型允许消费者以从消息队列中的任意偏移量处消费消息(可以处理之前已经处理过的消息)。
Kafka如何实现分布式的数据存储与数据读取?(分布式模型)
Kafka的分区有“多副本机制”,每个分区会以副本的方式复制到多个消息代理节点上,所有的外部读写消息请求都由主副本处理。
数据存储方面,涉及到生产者的消息分区策略:消息有键时,根据分区语义确保相同键的消息在同一分区;消息无键时,以轮询的方式为消息分配分区。
数据读取方面,消息模型采用“队列模式”和“发布-订阅模式”的结合。对不同消费组的消费者来说,获取消息属于“发布-订阅模式”,对于同一消费组的消费者来说,获取消息属于“队列模式”。
谈一谈Kafka的消息模型和消费模型
消息模型指的是对于Kafka来说,消息的一个流转方式,分为“队列模式”和“发布-订阅模式”。
消费模型指的是对于消费者来说,消息的获取方式,分为“拉取模型”和“推送模型”。
Kakfa是如何高效地持久化日志文件和加快数据传输消息的?
高效地持久化日志文件,利用操作系统的优化技术如预读、后写、空闲内存作为磁盘缓存,使得对于磁盘的顺序访问可以与随机访问内存的速度相比。
加快数据传输消息,采用“零拷贝”技术。
Kafka生产者如何批量地发送消息?
生产者会在内存中尝试收集足够数据,并在请求一个请求中一次性发送一批数据。生产者可以设置“在指定的时间内收集不超过指定数量的消息”,如设置消息大小上限为64字节,延迟时间为100ms,那么如果在100ms内消息大小达到64字节则会立即发送,否则不论消息大小,在100ms时会把已经收集到的消息发送出去。
Kafka的副本机制如何工作,当故障发生时,怎么确保数据不会丢失?
只有主副本负责处理外界的读写请求,当主副本出现故障时,备份副本会替换旧主副本成为新的主副本,继续处理读写请求;备份副本始终尽量保持与主副本的数据同步,Kafka中有一个 ISR (In Sync Replias)的概念,想进入ISR的副本需满足以下两点:
- 节点必须和ZK保持会话(表明节点是存活的)。
- 如果该节点是备份副本,则它必须复制主副本的写操作,并且复制的进度不能太落后。
发生故障时,主副本机制如何确保数据不会丢失呢?Kafka中,只有成功提交到生产者的消息才能被消费者看见从而消费。而“成功提交”的定义是:消息必须被ISR集合的所有副本都运用到本地的日志文件。这就保证了,如何时刻,只要ISR至少有一个副本是存活的,Kafka就可以保证“一条消息被提交,就不会丢失”。