话不多说,直接看代码--这里是写入文件的,想看写入MySQL的往下猛翻。
1 from bs4 import BeautifulSoup 2 import requests 3 import time 4 for i in range(1,7018): 5 url='https://www.autohome.com.cn/all/'+str(i)+'/' 6 response=requests.get(url=url) 7 response.encoding=response.apparent_encoding#防止解码出现乱码 8 9 soup=BeautifulSoup(response.text,features='html.parser') 10 target=soup.find(id='auto-channel-lazyload-article') 11 li_list=target.find_all('li') 12 13 14 for item in li_list: 15 a=item.find('a')#find_all 是列表 16 try:#nonetype 没有 attrs,则需要加一个异常处理机制 17 href=a.attrs.get('href') 18 title=a.find('h3').text 19 img_src=a.find('img').attrs.get('src') 20 print('链接: '+href) 21 print('标题 :'+title) 22 print('图片地址: '+img_src) 23 time_write=time.asctime( time.localtime(time.time()) ) 24 print('写入时间',time_write) 25 print('=========================================================') 26 with open(r'1.txt','a+') as f: 27 f.write(href+' '+title+' '+img_src+' '+time_write+' '+'=========================================='+' ') 28 29 except Exception as e: 30 pass
====================更新==========================
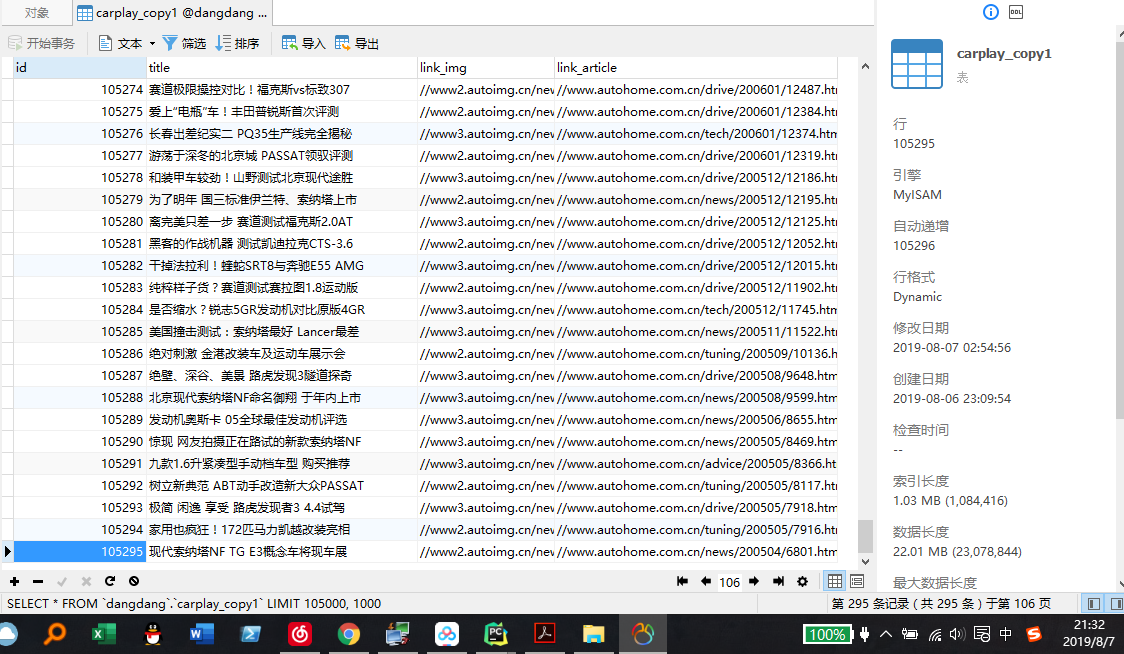
写入MySQL(使用pymsql库),总共105295条记录。
1 from bs4 import BeautifulSoup 2 import requests 3 import time 4 import pymysql 5 for i in range(1,7018): 6 url='https://www.autohome.com.cn/all/'+str(i)+'/' 7 response=requests.get(url=url) 8 response.encoding=response.apparent_encoding#防止解码出现乱码 9 10 soup=BeautifulSoup(response.text,features='html.parser') 11 target=soup.find(id='auto-channel-lazyload-article') 12 li_list=target.find_all('li') 13 14 15 for item in li_list: 16 a=item.find('a')#find_all 是列表 17 try:#nonetype 没有 attrs,则需要加一个异常处理机制 18 href=a.attrs.get('href') 19 title=a.find('h3').text 20 img_src=a.find('img').attrs.get('src') 21 print('链接: '+href) 22 print('标题 :'+title) 23 print('图片地址: '+img_src) 24 time_write=time.asctime( time.localtime(time.time()) ) 25 print('写入时间',time_write) 26 print('=========================================================') 27 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='dangdang') 28 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) 29 cursor.execute("insert into carplay_copy1(title,link_img,link_article)values(%s,%s,%s)", [title,img_src,href]) 30 conn.commit() 31 # cursor.close() 32 # conn.close() 33 # with open(r'1.txt','a+') as f: 34 # f.write(href+' '+title+' '+img_src+' '+time_write+' '+'=========================================='+' ') 35 36 except Exception as e: 37 pass
注意
w+:先清空所有文件内容,然后写入,然后你才可以读取你写入的内容 r+:不清空内容,可以同时读和写入内容。 写入文件的最开始 a+:追加写,所有写入的内容都在文件的最后