一、 fine-tuning
由于数据集的限制,我们可以使用预训练的模型,来重新fine-tuning(微调)。
使用卷积网络作为特征提取器,冻结卷积操作层,这是因为卷积层提取的特征对于许多任务都有用处,使用新的数据集训练新定义的全连接层。
何时以及如何Fine-tune
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:新数据集的大小、以及新数据和原数据集的相似程度。有一点一定记住:网络前几层学到的是通用特征,后面几层学到的是与类别相关的特征。这里有使用的四个场景:
1、新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2、新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
3、新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4、新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
我们这次的作业属于数据集与原来相似而且数据集很小的情况,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
二、代码重点
数据处理
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
#.中心裁剪:transforms.CenterCrop
#class torchvision.transforms.CenterCrop(size)
#功能:依据给定的size从中心裁剪
#参数:
#size- (sequence or int),若为sequence,则为(h,w),若为int,则(size,size)
transforms.ToTensor(),
normalize,
])
data_dir = './dogscats'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
修改全连接层,冻结卷积层的参数
for param in model_vgg_new.parameters():
param.requires_grad = False #训练时不更改参数
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) #全连接输出两类猫或者狗
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) # 数据处理
创建损失函数和优化器,训练模型
criterion = nn.NLLLoss() #设置损失函数
lr = 0.001 # 学习率
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr) # 随机梯度下降
#训练模型 (模板 建议直接背诵)
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
三、代码优化
1.数据处理
vgg_format = transforms.Compose([
#transforms.CenterCrop(224),
transforms.Resize((224,224)),
#这里选择缩放而不是中心裁剪,因为简单地选择重心裁剪会让图像的一些特征直接丢失,严重的情况下直接无法捕捉到物体(cat or dog),这样的情况下卷积也没有什么作用了
transforms.ToTensor(),
normalize,
])
下面的图片就可以看出使用缩放而不是中心裁剪的原因:原本图片的头被截去,很难判断这到底是还是。

2.学习率
learning rate在fine-turning中一般默认为10-3,但是在我的一些玄学甄选后发现0.0012的效果更好一些,所以我们选择lr=0.0012之后进行训练。
| lr | 10-3 | 115*10-5 | 12*10-4 |
|---|---|---|---|
| accuracy | 0.9645 | 0.9570 | 0.9680 |
| 听说有函数可以选择到最合适的学习率,但是我没有找到这个函数。 |
按表格自左到右顺序排列:



3.优化器
在开始的代码中我们选择了SGD作为优化器,但是在多种优化器的测试过后,我发现使用Adam情况下验证集准确率的效果最好。
| optimizer | SGD | RMSprop | Adam |
|---|---|---|---|
| accuracy | 0.9680 | 0.9840 | 0.9880 |


没有仔细实验的点:
1.SGD函数存在一个函数变量动量(Momentum),选择不同的动量的大小可能也会获得更好的效果,但是没有经过准确的实验。
2.RMSprop的一个参数alpha使用默认值,没有尝试其他数值。
3.Adam函数的一个参数betas使用默认值,没有实验其他的情况。
关于这些常见优化器的介绍:https://www.jianshu.com/p/1a1339c4acd7
4. epoch(批次)
在使用SGD作为优化器时,将批次设置为2后发现验证集的准确率得到了提升。
但是在设置Adam作为优化器后我们同样对不同的epoch分别设置为1和2,结果得到提升很小。
但是实验次数太少,不排除随机梯度下降导致的偶然性影响,默认情况下训练的批次越多,那么得到的模型对于训练的适应性就会越好,往往得到的准确率会更高,但是要注意可能会导致过拟合现象的产生。
而且我们的训练集规模太小,epoch设置1和2的提升并不是很多。
四、其他设想过的道路
1.损失函数的选择
criterion = nn.NLLLoss()
一般的分类任务往往会选择交叉熵损失函数CrossEntropyLoss()
但是老师这里选择了负对数似然函数NLLLoss()
所以我开始选择使用交叉熵损失函数替换掉负对数似然,但是得到的效果并不好
在查阅资料后我发现NLLLoss和CrossEntropyLoss做的工作很相似,但是有一点区别就是NLLLoss需要配合LogSoftmax,而在源码当中老师选择在全连接层的最后加入了这个函数。

也就是说他们两个接近等价 CrossEntropyLoss = LogSoftmax + NLLLoss
所以我的尝试没有到预期的效果。
2. 冻结不同的参数
在完成对于VGG的最后一层全连接层的训练后,查阅相关资料,我注意到了在Keras中对Resnet的更改,他选择在冻结大部分卷积层的前提下,选择训练最后一层卷积层和全连接层。
理所当然的我设想在VGG中同样采取这样的尝试,但是发现VGG并没有直接提供对于提取特征层(features)处理的方法,所以可能需要模仿构建一个新的VGG?
但是我没有对这一方面进行额外的尝试
3.Dropout
众所周知,Dropout对于处理过拟合有着很好的效果,但是一般情况下Dropout设置为0.5,VGG中也相同,所以没有更改。
五、得分
本地:

研习社:
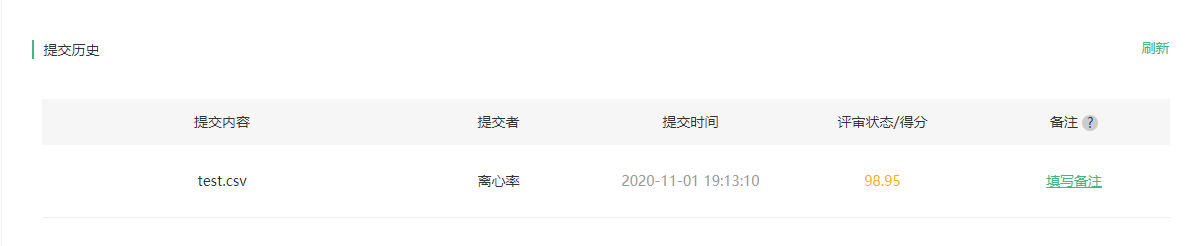
还有排名:

最后的得分是98.95
欢迎推荐 转载请评论