一、文本文件和二进制文件
文本文件存储的是普通“字符”文本,python 默认为unicode 字符集(两个字节表示
一个字符,最多可以表示:65536 个)。
二进制文件:二进制文件吧数据内容用‘字节’进行存储。记事本无法打开。
二、文件的几种操作方法及模式
|
模式 |
描述 |
文件不存在 |
是否覆盖已有内容 |
|
r |
只读 |
报错 |
- |
|
r+ |
可读可写 |
报错 |
是 |
|
w |
只写 |
创建 |
是 |
|
w+ |
可读可写 |
创建 |
是 |
|
a |
只写 |
创建 |
否,追加写 |
|
a+ |
可读可写 |
创建 |
否,追加写 |
|
b |
二进制(可与上述并用) |
- |
- |
文本文件的读写
with open(r"b.txt", 'r') as f: r = f.read() print(r)
运行结果:
Today it's beautiful,are you agree?
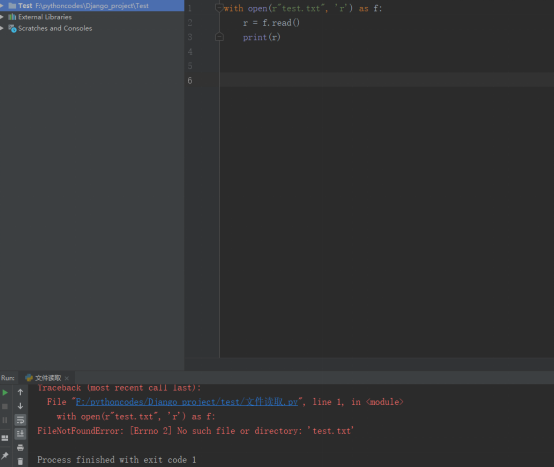
该函数表示打开一个b.txt文件,并且读写里面的内容进行打印,如果文件不存在则会报错,因为使用了with,因此不需要再使用f.close()关闭文件。如果该文件不存在则会报错,如图所示,test.txt 文件不存在,因此报错。
二进制文件的读写:
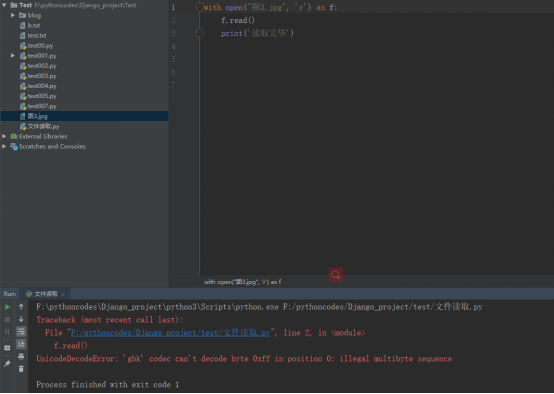
with open(r"图3.jpg", 'rb') as f: f.read() print('读取完毕')
输出结果:
读取完毕
输出结果,对于二进制文件,如果不加入”b”,则会报错。如下所示:
实例:
with open('图3.jpg', 'rb') as f: with open('tu3.jpg', 'wb') as w: for line in f.readlines(): w.write(line) print('copy success')
该程序表示读写一个名为图3.jpg的文件,然后写入tu3.jpg中。
文件对象的常用方法:
|
方法 |
描述 |
|
read(x) |
从文件中读取x个字节或字符的内容返回。若省略x,则读取到文件末尾,即一次读取文件所有内容 |
|
readline() |
从文本文件中读取一行内容 |
|
readlines() |
把文本文件中每一行都作为独立的字符串对象,并将这些对象放入 列表返回 |
|
write() |
将字符串内容写入文件 |
|
writelines(s) |
将字符串列表s 写入文件文件,不添加换行符 |
|
seek(offset ,whence) |
把文件指针移动到新的位置,offset:开始的偏移量 whence 不同的值代表不同含义: 0: 从文件头开始计算(默认值) 1:从当前位置开始计算 2:从文件尾开始计算 |
|
tell() |
返回文件指针的当前位置 |
|
truncate([size]) |
不论指针在什么位置,只留下指针前size 个字节的内容,其余全 部删除; 如果没有传入size,则当指针当前位置到文件末尾内容全部删除。 |
|
flush() |
把缓冲区的内容写入文件,但不关闭文件 |
|
close() |
把缓冲区内容写入文件,同时关闭文件,释放文件对象相关资源 |
三、python内置函数
enumerate()函数
enumerate()函数用于将一个可遍历的数据对象(如列表、元组和字符串)组合为一个索引序列,同时列出数据和数据下标
enumerate(object,[start=0])
object表示一个可以遍历的数据对象,start表示下标开始位置,默认为0。
enumerate()实例1
a = ['my name is Bob', "I'm from Asia", 'and 18 years pld'] b = enumerate(a) print(list(b))
结果:
[(0, 'my name is Bob'), (1, "I'm from Asia"), (2, 'and 18 years pld')]
enumerate()实例2:
bob = ['my name is Bob', "I'm from Asia", 'and 18 years pld'] for a, b in enumerate(bob, start=1): print(a,b)
结果:
1 my name is Bob
2 I'm from Asia
3 and 18 years pld
在上面这个实例中发现了以下操作:
对bob这个列表进行了enuerate操作,得到的结果如实例1,通过for循环进行遍历,第一个数值赋给a,第二个数值赋给b,便得到了最终结果。