一.urllib库简介
简介
Urllib是Python内置的HTTP请求库。其主要作用就是可以通过代码模拟浏览器发送请求。它包含四个模块:
urllib.request :请求模块
urllib.error :异常处理模块
urllib.parse url : 解析模块
urllib.robotparser :robots.txt解析模块,用的比较少
相比Python2与3变化:
其常被用到的子模块在Python3中的为urllib.request和urllib.parse,在Python2中是urllib和urllib2。
Python2: import urllib2 response=urllib2.urlopen(‘http://www.baidu.com’) Python3: import urllib.request response=urllib.request.urlopen(‘http://www.baidu.com’)
二.使用简介:
parse
用于url解析转换
dic = {'wd': '赵丽颖'}
ps = parse.urlencode(dic)
print(ps) # wd=%E8%B5%B5%E4%B8%BD%E9%A2%96
print(parse.parse_qs(ps)) # {'wd': ['赵丽颖']}
urlopen
这个函数很简单,就是请求一个url的内容。其实这就是爬虫的第一步:网页请求,获取内容。
urllib.request.urlopen(url, data=None, [timeout] *, cafile=None, capath=None, cadefault=False, context=None) # urlopen前三个分别是(网站,网站的数据,超时设置,主要前两个其他不常用)
可以看到,这个函数可以有非常多的参数,前三个用的最多,我们来逐一看看。
1.url参数
import urllib.request
response =urllib.request.urlopen('http://www.baidu.com') #把请求的结果传给response
print(response.read().decode('utf-8')) #转换成字符串
print(response.read(10).decode('utf-8')) #只读取10个
print(response.readline().decode('utf-8')) #只读取一行
在交互模式下执行以上命令就可以打印出百度首页的源代码了。
这是一种GET类型的请求,只传入了一个参数(url)。
下面演示一种POST类型的请求:
2.data参数
示例代码:
import urllib.parse import urllib.request data=bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8') #需要传入一个data参数,需要的是bytes类型,这里用了urlencode方法传入一个字典,并指定编码 response=urllib.request.urlopen('http://httpbin.org/post',data=data) #给urlopen函数传入两个参数,一个是url,一个是data print(response.read())
(http://httpbin.org/ 是一个HTTP测试页面)
可以看到打印出了一些Json字符串:

我们可以从打印结果看到,我们成功的把’word’:'hello’这个字典通过urlopen函数以POST形式把它传递过去了。这样我们就完成了一个POST的请求。
总结:加了data参数就是以POST形式发送请求,否则就是GET方式了。
3.timeout
再来看看第三个参数:超时时间。如果超过了这个时间没有得到响应的话,就会抛出异常。
示例代码:
import urllib.request response=urllib.request.urlopen('http://httpbin.org/get',timeout=1)#设置超时时间 print(response.read())
再看另一种情况,我们把超时时间设置为0.1:
import socket import urllib.request import urllib.error try: response=urllib.request.urlopen('http://httpbin.org/get',timeout=0.1) #必须在0.1秒内得到响应,否则就会抛出异常 except urllib.error.URLError as e: if isinstance(e.reason,socket.timeout):#类型判断,如果是超时错误,那么打印 print('TIME OUT')
响应(response)
获取响应类型:type()
示例:
import urllib.request response =urllib.request.urlopen('https://www.python.org') print(type(response))#打印响应的类型
通过调用这个方法我们可以看到响应的类型。

状态码、响应头
一个响应里面包含了两个比较有用的信息:状态码和响应头。

以上面提到的http://httpbin.org/ 为例,我们可以在审查中,找到状态码和响应头(上图红框所示)。
这两个信息是判断响应是否成功的非常重要的标志。
在这里我们可以用status参数获取响应的状态码,用getheaders()方法获取响应头。
示例:
import urllib.request response =urllib.request.urlopen('https://www.python.org') print(response.status)#状态码 print(response.getheaders())#响应头 print(response.getheader('Server'))#可以取得响应头中特定的信息
另外,关于read()方法,它获取的是响应体中的内容(bytes形式)
import urllib.request response =urllib.request.urlopen('https://www.python.org') print(response.read().decode('utf-8'))#将字节流解码为utf-8
请求(request)
如果我们要在请求中加入别的信息怎么办呢?用上面的urlopen函数是无法满足的。
例如我们要在请求中加上Headers参数,但是urlopen函数中是没有提供这个参数的。
如果我们想要发送一些更为复杂的请求的话,比如加上Headers,怎么办呢?
那么我可以创建一个request对象——使用Request(它也是属于urllib.request模块的)。
来看示例:
import urllib.request request=urllib.request.Request('https://python.org')#把url构造成一个request对象 response=urllib.request.urlopen(request)#再把request对象传给urlopen print(response.read().decode('utf-8'))
这样也可以成功实现请求。
有了这样的方法,我们就能更方便地指定请求的方式,还可以加一些额外的数据。
那么现在尝试构造一个POST请求,并且把headers加进来。
from urllib import request,parse #构造一个POST请求 url='http://httpbin.org/post' headers={ 'Users-Agent':'..............', 'Host':'httpbin.org' } dic={ 'name':'iron' } data=bytes(parse.urlencode(dic),encoding='utf8')#fontdata数据 req=request.Request(url=url,data=data,headers=headers,method='POST')#构建一个Request()的一个结构 response = request.urlopen(req) print(response.read().decode('utf-8'))
我们把以上代码写成一个py文件并运行:

可以看到,我们构造的Request包含了之前所提到的信息,请求的时候我们是把Request当成一个整体传递给了urlopen,就可以实现这样的请求了。
好处是整个Request的结构是非常清晰的。
此外还有另外一种实现方式,就是用add_header()方法,也可以实现相同的效果:
from urllib import request, parse
# 构造一个POST请求
url = 'http://httpbin.org/post'
dic = {
'name': 'iron'
}
data = bytes(parse.urlencode(dict), encoding='utf8') # fontdata数据
req = request.Request(url=url, data=data, method='POST') # 构建一个Request()的一个结构
req.add_header('User-Angent', '................')
req.add_header('Host', 'httpbin.org')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
add_header() 方法作为添加header的另一种方式,可以用来比较复杂的情况,比如要添加许多键值对,那么可以用一个for循环来不断调用这个方法,这也是比较方便的。
urlretrieve
直接打开url并写到本地
request.urlretrieve('http://www.baidu.com', 'baidu.html')
例如直接下载图片或者视频
url = input('你想下载的视频或图片链接:') request.urlretrieve(url, 'binfile')
Headler
Headler相当于一个辅助工具,来帮助我们处理一些额外的工作,比如FTP、Cache等等操作,我们都需要借助Headler来实现。比如在代理设置的时候,就需要用到一个ProxyHandler。更多的用法,请参阅官方文档。
1.代理
用来对ip地址进行伪装成不同地域的,防止ip在爬虫运行时被封掉。
示例:
from urllib import request proxy_handler = request.ProxyHandler( #构建ProxyHandler,传入代理的网址 {'http':'http://127.0.0.1:9743', 'https':'https://127.0.0.1:9743' }) #实践表明这个端口已经被封了,这里无法演示了 opener = request.build_opener(proxy_handler)#再构建一个带有Handler的opener response = opener.open('http://www.baidu.com') print(response.read())
2.Cookie
Cookie是在客户端保存的用来记录用户身份的文本文件。
在爬虫时,主要是用来维护登录状态,这样就可以爬取一些需要登录认证的网页了。
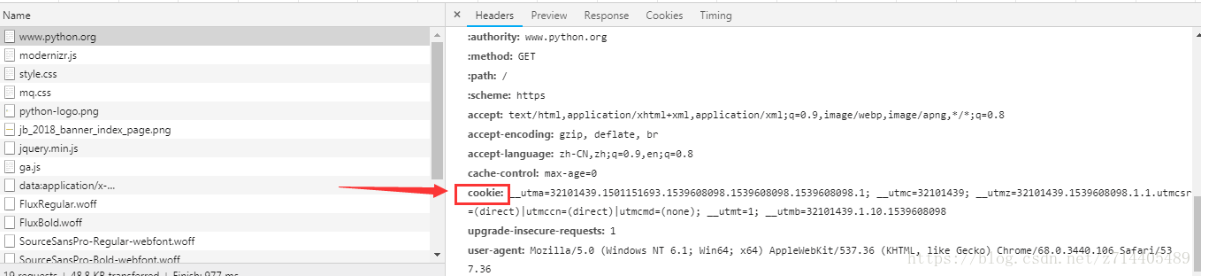
实例演示:
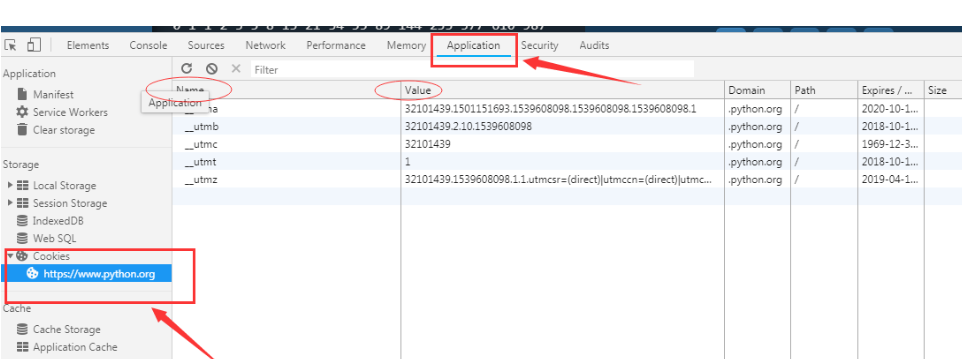
from urllib import request from http import cookiejar cookie =cookiejar.CookieJar()#将cookie声明为一个CookieJar对象 handler = request.HTTPCookieProcessor(cookie) opener = request.build_opener(handler) response =opener.open('http://www.baidu.com')#通过opener传入,并打开网页 for item in cookie:#通过遍历把已经赋值的cookie打印出来 print(item.name+'='+item.value)#通过item拿到每一个cookie并打印
3.Cookie的保存
我们还可以把cookie保存成文本文件,若cookie没有失效,我们可以从文本文件中再次读取cookie,在请求时把cookie附加进去,这样就可以继续保持登录状态了。
示例代码:
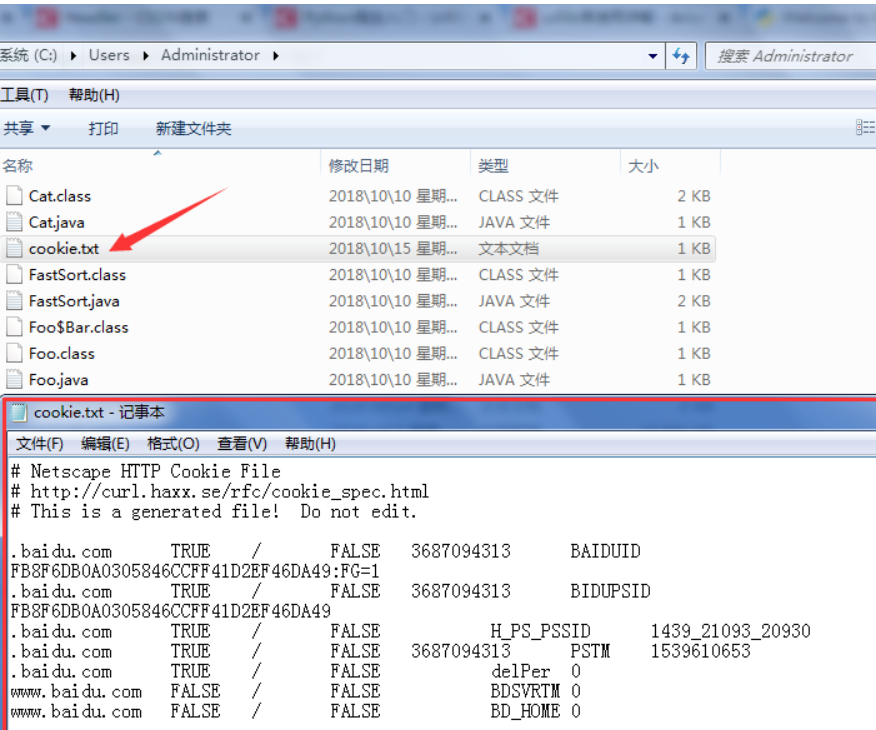
from urllib import request from http import cookiejar filename="cookie.txt" cookie=cookiejar.MozillaCookieJar(filename) #把cookie声明为cookiejar的一个子类对象————MozillaCookieJar,它带有一个save方法,可以把cookie保存为文本文件 handler=request.HTTPCookieProcessor(cookie) opener=request.build_opener(handler) response=opener.open('http://www.baidu.com') cookie.save(ignore_discard=True,ignore_expires=True)#调用save方法
执行代码后,我们就可以在运行目录下找到已经保存好的cookie文本文件了:
还有另外一种格式:
在上面那段代码的基础上,换一个子类对象就可以了:
cookie=cookiejar.LWPCookieJar(filename)
可以看到,这次生了一个不同格式的cookie文本文件:

4.Cookie的读取
我们可以选择相对应的格式来完成读取。以上面的LWP格式为例:
from urllib import request from http import cookiejar cookie=cookiejar.LWPCookieJar() #z注意选择相应的格式,这里是LWP cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True)#load方法是读取的关键 handler=request.HTTPCookieProcessor(cookie) opener=request.build_opener(handler) response=opener.open('http://www.baidu.com') print(response.read().decode('utf-8'))
以上的代码就可以完成读取了。这样,我们就可以在对网页进行请求时,自动把之前的cookie附着进去,以保持一个登录的状态了。
异常处理
这是属于urllib的另一大模块。
rom urllib import request,error #我们试着访问一个不存在的网址 try: response = request.urlopen('http://www.cuiqingcai.com/index.html') except error.URLError as e: print(e.reason)#通过审查可以查到我们捕捉的异常是否与之相符
可以看到,返回了错误信息。这样的异常处理可以保证爬虫在工作时不会轻易中断。
那么,urllib可以捕捉哪些异常呢?详见官方文档。
其实一般碰到有两个:HTTP和URL。我们一般只需要捕捉这两个异常就可以了。
from urllib import request,error #我们试着访问一个不存在的网址 try: response = request.urlopen('http://www.cuiqingcai.com/index.html') except error.HTTPError as e:#最好先捕捉HTTP异常,因为这个异常是URL异常的子类 print(e.reason,e.code,e.headers,sep=' ') except error.URLError as e: print(e.reason) else: print('Request Successfully!')
打印出错误的相关信息。
此外,e.reason也是一个类,它可以得到异常的类型。
我们试着看看:
from urllib import request,error import socket try: response = request.urlopen('http://www.baidu.com',timeout = 0.01)#超时异常 except error.URLError as e: print(type(e.reason)) if isinstance(e.reason,socket.timeout):#判断error类型 print('TIME OUT')
异常类型被打印出来了,确实是超时异常。
URL解析
这是一个工具性质的模块,即拿即用就行。
1.urlparse
这个方法将将url进行分割,分割成好几个部分,再依次将其复制。
urllib.parse.urlparse(urlstring,scheme='',allow_fragments = True) #分割成(url,协议类型,和#后面的东西)
来看具体的例子:
from urllib.parse import urlparse result = urlparse('https://www.baidu.com/s?wd=urllib&ie=UTF-8') print(type(result),result) #<class 'urllib.parse.ParseResult'> #无协议类型指定,自行添加的情况 result1 = urlparse('www.baidu.com/s?wd=urllib&ie=UTF-8',scheme = 'https') print(result1) #有指定协议类型,默认添加的情况? result2 = urlparse('http://www.baidu.com/s?wd=urllib&ie=UTF-8',scheme = 'https') print(result2) #allow_fragments参数使用 result3 = urlparse('http://www.baidu.com/s?#comment',allow_fragments = False) result4 = urlparse('http://www.baidu.com/s?wd=urllib&ie=UTF-8#comment',allow_fragments = False) print(result3,result4) #allow_fragments=False表示#后面的东西不能填,原本在fragment位置的参数就会往上一个位置拼接,可以对比result1和result2的区别
从这个例子我们也可以知道,一个url可以分成6个字段。
2.urlunparse(urlparse的反函数)
这个函数用来拼接url。
看看这个例子:
from urllib.parse import urlunparse #注意即使是空符号也要写进去,不然会出错 data = ['http', 'www.baidu.com', 'index.html','user','a=6' 'comment'] print(urlunparse(data))
3.urljoin
这个函数用来拼合url。
通过例子感受以下:
以后面的参数为基准,会覆盖掉前面的字段。如果后面的url,存在空字段而前面的url有这个字段,就会用前面的作为补充。
from urllib.parse import urljoin print(urljoin('http://www.baidu.com','FQA.html')) #http://www.baidu.com/FQA.html print(urljoin('http://www.baidu.com','http://www.caiqingcai.com/FQA.html')) #http://www.caiqingcai.com/FQA.html print(urljoin('https://www.baidu.com/about.html','http://www.caiqingcai.com/FQA.html')) #http://www.caiqingcai.com/FQA.html print(urljoin('http://www.baidu.com/about.html','https://www.caiqingcai.com/FQA.html')) #https://www.caiqingcai.com/FQA.html
4.urlencode
这个函数用来将字典对象转化为get请求参数。
from urllib.parse import urlencode params = { 'name':'zhuzhu', 'age':'23' } base_url = 'http://www.baidu.com?' url = base_url+urlencode(params)#将params对象编码转换 print(url)
robotparser
用来解析robot.txt。用的比较少,这里不再赘述。
三.由易到难的爬虫程序:
1.爬取百度首页面所有数据值
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #导包 4 import urllib.request 5 import urllib.parse 6 if __name__ == "__main__": 7 #指定爬取的网页url 8 url = 'http://www.baidu.com/' 9 #通过urlopen函数向指定的url发起请求,返回响应对象 10 reponse = urllib.request.urlopen(url=url) 11 #通过调用响应对象中的read函数,返回响应回客户端的数据值(爬取到的数据) 12 data = reponse.read()#返回的数据为byte类型,并非字符串 13 print(data)#打印显示爬取到的数据值。
#补充说明 urlopen函数原型:urllib.request.urlopen(url, data=None, timeout=<object object at 0x10af327d0>, *, cafile=None, capath=None, cadefault=False, context=None) 在上述案例中我们只使用了该函数中的第一个参数url。在日常开发中,我们能用的只有url和data这两个参数。 url参数:指定向哪个url发起请求 data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数(暂时不需要理解,后期会讲) urlopen函数返回的响应对象,相关函数调用介绍: response.headers():获取响应头信息 response.getcode():获取响应状态码 response.geturl():获取请求的url response.read():获取响应中的数据值(字节类型)
2.将爬取到百度新闻首页的数据值写入文件进行存储
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
if __name__ == "__main__":
url = 'http://news.baidu.com/'
reponse = urllib.request.urlopen(url=url)
#decode()作用是将响应中字节(byte)类型的数据值转成字符串类型
data = reponse.read().decode()
#使用IO操作将data表示的数据值以'w'权限的方式写入到news.html文件中
with open('./news.html','w') as fp:
fp.write(data)
print('写入文件完毕')
3.爬取网络上某张图片数据,且存储到本地
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
#如下两行代码表示忽略https证书,因为下面请求的url为https协议的请求,如果请求不是https则该两行代码可不用。
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
if __name__ == "__main__":
#url是https协议的
url = 'https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1536918978042&di=172c5a4583ca1d17a1a49dba2914cfb9&imgtype=0&src=http%3A%2F%2Fimgsrc.baidu.com%2Fimgad%2Fpic%2Fitem%2F0dd7912397dda144f04b5d9cb9b7d0a20cf48659.jpg'
reponse = urllib.request.urlopen(url=url)
data = reponse.read()#因为爬取的是图片数据值(二进制数据),则无需使用decode进行类型转换。
with open('./money.jpg','wb') as fp:
fp.write(data)
print('写入文件完毕')
4.url的特性:
url必须为ASCII编码的数据值。所以我们在爬虫代码中编写url时,如果url中存在非ASCII编码的数据值,则必须对其进行ASCII编码后,该url方可被使用。
案例:爬取使用百度根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦’的页面数据)
import urllib.request import urllib.parse if __name__ == "__main__": #原始url中存在非ASCII编码的值,则该url无法被使用。使用会报错需要转码 #url = 'http://www.baidu.com/s?ie=utf-8&wd=赵丽颖' #处理url中存在的非ASCII数据值 url = 'http://www.baidu.com/s?' #将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数 param = { 'ie':'utf-8', 'wd':'赵丽颖' } #使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码 param = urllib.parse.urlencode(param) #将编码后的数据和url进行整合拼接成一个完整可用的url url = url + param print(url) response = urllib.request.urlopen(url=url) data = response.read() with open('./赵丽颖.html','wb') as fp: fp.write(data) print('写入文件完毕')
5.通过自定义请求对象,用于伪装爬虫程序请求的身份。
之前在讲解http常用请求头信息时,我们讲解过User-Agent参数,简称为UA,该参数的作用是用于表明本次请求载体的身份标识。如果我们通过浏览器发起的请求,则该请求的载体为当前浏览器,则UA参数的值表明的是当前浏览器的身份标识表示的一串数据。如果我们使用爬虫程序发起的一个请求,则该请求的载体为爬虫程序,那么该请求的UA为爬虫程序的身份标识表示的一串数据。有些网站会通过辨别请求的UA来判别该请求的载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应,那么我们的爬虫程序则也无法通过请求爬取到该网站中的数据值,这也是反爬虫的一种初级技术手段。那么为了防止该问题的出现,则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识。
上述案例中,我们是通过request模块中的urlopen发起的请求,该请求对象为urllib中内置的默认请求对象,我们无法对其进行UA进行更改操作。urllib还为我们提供了一种自定义请求对象的方式,我们可以通过自定义请求对象的方式,给该请求对象中的UA进行伪装(更改)操作。
import urllib.request import urllib.parse import ssl ssl._create_default_https_context = ssl._create_unverified_context # 证书相关 if __name__ == "__main__": #原始url中存在非ASCII编码的值,则该url无法被使用。 #url = 'http://www.baidu.com/s?ie=utf-8&wd=赵丽颖' #处理url中存在的非ASCII数据值 url = 'http://www.baidu.com/s?' #将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数 param = { 'ie':'utf-8', 'wd':'赵丽颖' } #使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码 param = urllib.parse.urlencode(param) #将编码后的数据和url进行整合拼接成一个完整可用的url url = url + param #将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,从中获取UA的值 headers={ 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } #自定义一个请求对象 #参数:url为请求的url。headers为UA的值。data为post请求的请求参数(后面讲) request = urllib.request.Request(url=url,headers=headers) #发送我们自定义的请求(该请求的UA已经进行了伪装) response = urllib.request.urlopen(request) data=response.read() with open('./赵丽颖.html','wb') as fp: fp.write(data) print('写入数据完毕')