requests模块
什么是requests模块
requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位
安装
pip install requests //注意有的可能是pip3
使用流程 :
- 指定url - 基于requests模块发起请求 - 获取响应对象中的数据值 - 持久化存储
requests库7个主要方法
| 方法 | 说明 |
|---|---|
| requsts.requst() | 构造一个请求,最基本的方法,是下面方法的支撑 |
| requsts.get() | 获取网页,对应HTTP中的GET方法 |
| requsts.post() | 向网页提交信息,对应HTTP中的POST方法 |
| requsts.head() | 获取html网页的头信息,对应HTTP中的HEAD方法 |
| requsts.put() | 向html提交put方法,对应HTTP中的PUT方法 |
| requsts.patch() | 向html网页提交局部请求修改的的请求,对应HTTP中的PATCH方法 |
| requsts.delete() | 向html提交删除请求,对应HTTP中的DELETE方法 |
requests.get()
源码浅析


def request(method, url, **kwargs): # method = 请求方式(http方法) with sessions.Session() as session: return session.request(method=method, url=url, **kwargs) # 返回Session对象的request方法 # 点进去查看 def request(self, method, url, params=None, data=None, headers=None, cookies=None, files=None, auth=None, timeout=None, allow_redirects=True, proxies=None, hooks=None, stream=None, verify=None, cert=None, json=None): req = Request( method=method.upper(), url=url, headers=headers, files=files, data=data or {}, json=json, params=params or {}, auth=auth, cookies=cookies, hooks=hooks, ) prep = self.prepare_request(req) proxies = proxies or {} settings = self.merge_environment_settings( prep.url, proxies, stream, verify, cert ) send_kwargs = { 'timeout': timeout, 'allow_redirects': allow_redirects, } send_kwargs.update(settings) resp = self.send(prep, **send_kwargs) return resp
爬取网页的通用代码框架
import requests
def get_html(url, params):
try:
r = requests.get(url, params)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "raise exception"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(get_html(url))
get方法传参
request.get(url,params=None,**kwargs)
从上面的源码也可以知道,解释一下参数含义
url: 获取html的网页的url
params:url中的额外的参数,字典或字节流格式,可选
**kwargs: 12个控制访问的参数
requestsl两个重要对象
r = requests.get(url) r:是一个Response对象,一个包含服务器资源的对象 .get(url):是一个Request对象,构造一个向服务器请求资源的Request。
r.status_code HTTP请求返回状态码,200表示成功 r.text HTTP响应的字符串形式,即,url对应的页面内容 r.encoding 从HTTP header中猜测的响应内容的编码方式 r.apparent_encoding 从内容中分析响应内容的编码方式(备选编码方式) r.content HTTP响应内容的二进制形式 理解Response编码 r.encoding:如果header中不存在charset,则认为编码是ISO-8859-1,r.text根据r.encoding显示网页内容 r.apparent_encoding:根据网页内容分析处的编码方式可以看做是r.encoding的备选
response = requests.get('http://www.jianshu.com/') # 获取响应状态码 print(type(response.status_code),response.status_code) # 获取响应头信息 print(type(response.headers),response.headers) # 获取响应头中的cookies print(type(response.cookies),response.cookies) # 获取访问的url print(type(response.url),response.url) # 获取访问的历史记录 print(type(response.history),response.history)
异常
理解requests库的异常:网络链接有风险,异常处理很重要 requests.ConnectionError 网络连接异常,如DNS查询失败,拒绝连接等 requests.HTTPError #HTTP错误异常 requests.URLRequired #URL缺失异常 requests.TooManyRedirects #超过最大重定向次数,产生重定向异常 requests.ConnectTimeout #连接远程服务器超时异常 requests.Timeout #请求URL超时,产生超时异常
import requests from requests.exceptions import ReadTimeout, ConnectionError, RequestException try: response = requests.get("http://httpbin.org/get", timeout = 0.5) print(response.status_code) except ReadTimeout: # 超时异常 print('Timeout') except ConnectionError: # 连接异常 print('Connection error') except RequestException: # 请求异常 print('Error')
Requests库中的post()方法
爬取网页的通用代码框架,一般用于验证提交信息登录
import requests def get_html(url, params): try: r = requests.post(url, data) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "raise exception" if __name__ == "__main__": url = "http://url.com.login" data = { “username”:"user", "password":"password" } print(get_html(url=url,data=data))
Requests库主要方法解析
method 1. requests.request(method, url, **kwargs) 构造并发送一个Request对象,返回一个Response对象。 参数: - method – 新建 Request 对象要使用的HTTP方法 - url – 新建 Request 对象的URL - params – (可选) Request 对象的查询字符中要发送的字典或字节内容 - data – (可选) Request 对象的 body 中要包括的字典、字节或类文件数据 - json – (可选) Request 对象的 body 中要包括的 Json 数据 - headers – (可选) Request 对象的字典格式的 HTTP 头 - cookies – (可选) Request 对象的字典或 CookieJar 对象 - files – (可选) 字典,'name': file-like-objects (或{'name': ('filename', fileobj)}) 用于上传含多个部分的(类)文件对象 - auth – (可选) Auth tuple to enable Basic/Digest/Custom HTTP Auth. - timeout (浮点或元组) – (可选) 等待服务器数据的超时限制,是一个浮点数,或是一个(connect timeout, read timeout) 元组 - allow_redirects (bool) – (可选) Boolean. True 表示允许跟踪 POST/PUT/DELETE 方法的重定向 - proxies – (可选) 字典,用于将协议映射为代理的URL - verify – (可选) 为 True 时将会验证 SSL 证书,也可以提供一个 CA_BUNDLE 路径 - stream – (可选) 如果为 False,将会立即下载响应内容 - cert – (可选) 为字符串时应是 SSL 客户端证书文件的路径(.pem格式),如果是元组,就应该是一个(‘cert’, ‘key’) 二元值对 2. requests.head(url, **kwargs) 发送一个 HEAD 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - **kwargs – 见 *request* 方法接收的可选参数 3. requests.get(url, **kwargs) 发送一个 GET 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - **kwargs – 见 *request* 方法接收的可选参数 4. requests.post(url, data=None, **kwargs) 发送一个 POST 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - data – (可选) Request 对象的 body 中要包括的字典、字节或类文件数据 - **kwargs – 见 *request* 方法接收的可选参数 5. requests.put(url, data=None, **kwargs) 发送一个 PUT 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - data – (可选) Request 对象的 body 中要包括的字典、字节或类文件数据 - **kwargs – 见 *request* 方法接收的可选参数 6. requests.patch(url, data=None, **kwargs) 发送一个 PUT 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - data – (可选) Request 对象的 body 中要包括的字典、字节或类文件数据 - **kwargs – 见 *request* 方法接收的可选参数 7. requests.delete(url, **kwargs) 发送一个 PUT 请求,返回一个 Response 对象 参数: - url – 新建 Request 对象的URL - **kwargs – 见 *request* 方法接收的可选参数
简单应用
1.爬取搜狗页面数据
import requests
# 1 指定url
url = "https://www.sogou.com"
# 2 发送请求
response = requests.get(url) # 返回一个响应
# 3 获取页面数据
print(response.url) # 显示当前爬的url https://www.sogou.com/
# print(response.text, type(response.text)) # 显示当前爬的str类型的页面数据
# print(response.content, type(response.content)) # 显示当前爬的bytes类型的页面数据
print(response.headers['Content-Type']) # 请求类型 text/html; charset=UTF-8
# 4.页面数据的持久化数据
with open("sogou.html", "w", encoding="utf-8") as f:
f.write(response.text)
2.登录豆瓣电影,爬取登录成功后的页面数据
import requests
url = 'https://accounts.douban.com/login'
# 封装请求参数
data = {
"source": "movie",
"redir": "https://movie.douban.com/",
"form_email": "15027900535",
"form_password": "bobo@15027900535",
"login": "登录",
}
# 自定义请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
response = requests.post(url=url, data=data)
page_text = response.text
with open('./douban.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
3.爬取肯德基餐厅地址
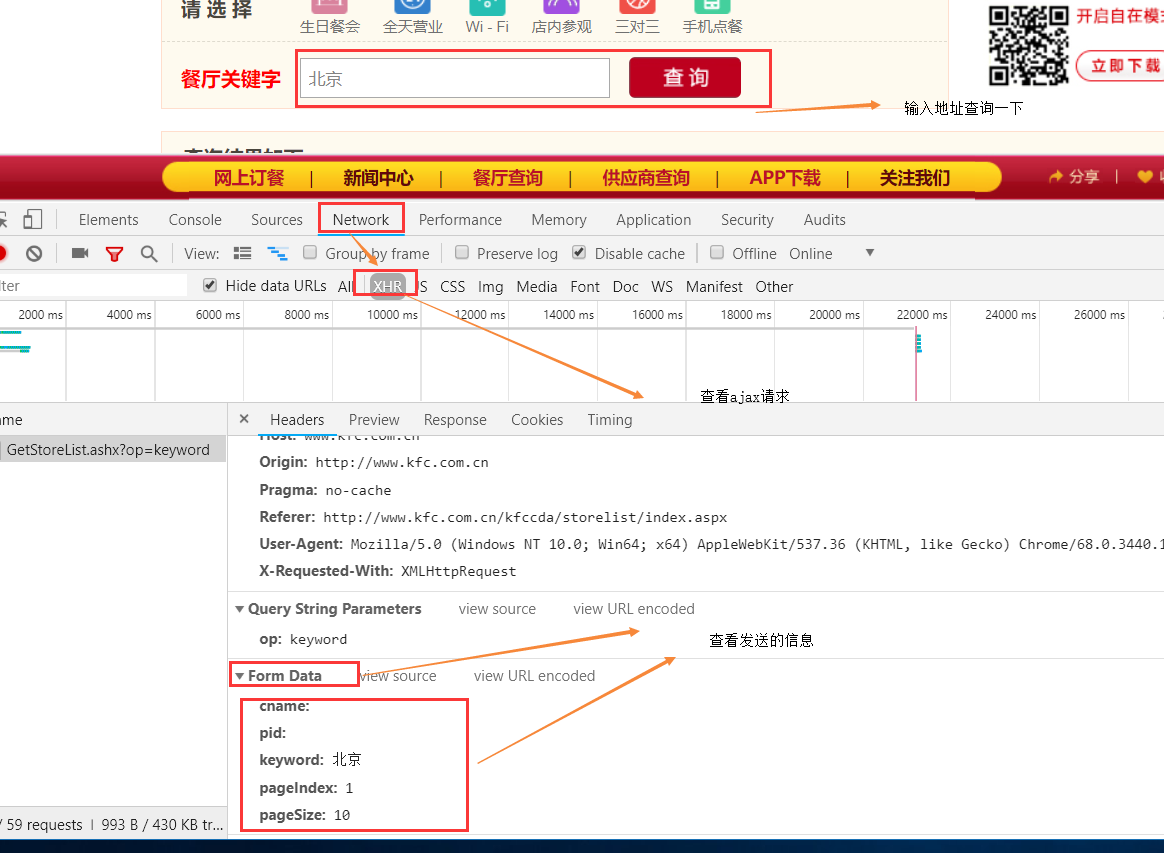
import requests
if __name__ == "__main__":
# 指定ajax-post请求的url(通过抓包进行获取)
url = 'http://www.kfc.com.cn/kfccda/storelist/index.aspx'
# 定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
# 定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
# 定制post请求携带的参数(从抓包工具中获取)
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': '1',
'pageSize': '10'
}
# 发起post请求,获取响应对象
response = requests.post(url=url, headers=headers, data=data)
# 获取响应内容:响应内容为json串
print(response.text)
4.网站爬取数据
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' pageNum = 3 all_id_list = [] for page in range(3, 5): data = { 'on': 'true', 'page': str(page), 'pageSize': '15', 'productName': '', 'conditionType': '1', 'applyname': '', 'applysn': '' } json_text = requests.post(url=url, data=data, headers=headers).json() # all_id_list = [] for dict in json_text['list']: id = dict['ID'] # 用于二级页面数据获取 all_id_list.append(id) # 该url是一个ajax的post请求 post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for id_ in all_id_list: data = { 'id': id_ } response = requests.post(url=post_url, data=data, headers=headers) # 该请求响应回来的数据有两个,一个是基于text,一个是基于json的,所以可以根据content-type,来获取指定的响应数据 if response.headers['Content-Type'] == 'application/json;charset=UTF-8': # print(response.json()) # 进行json解析 json_text = response.json() print(json_text['businessPerson'])