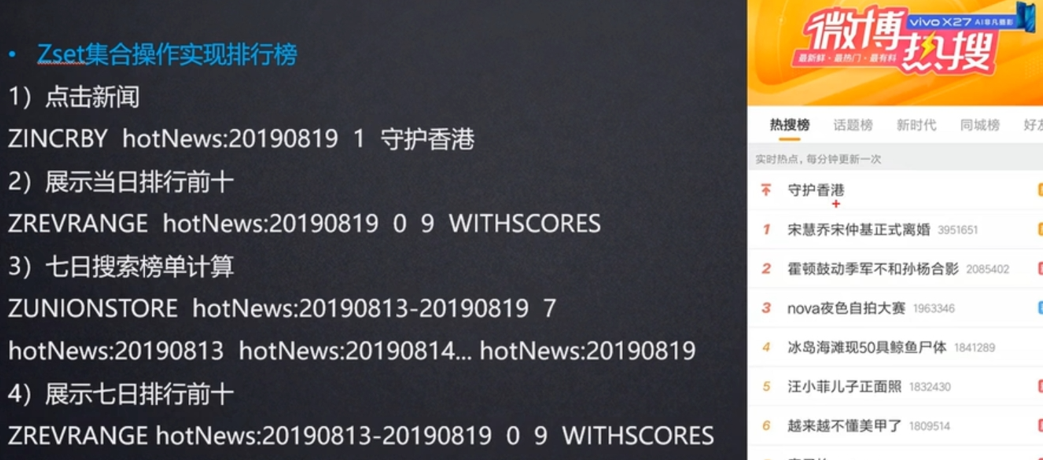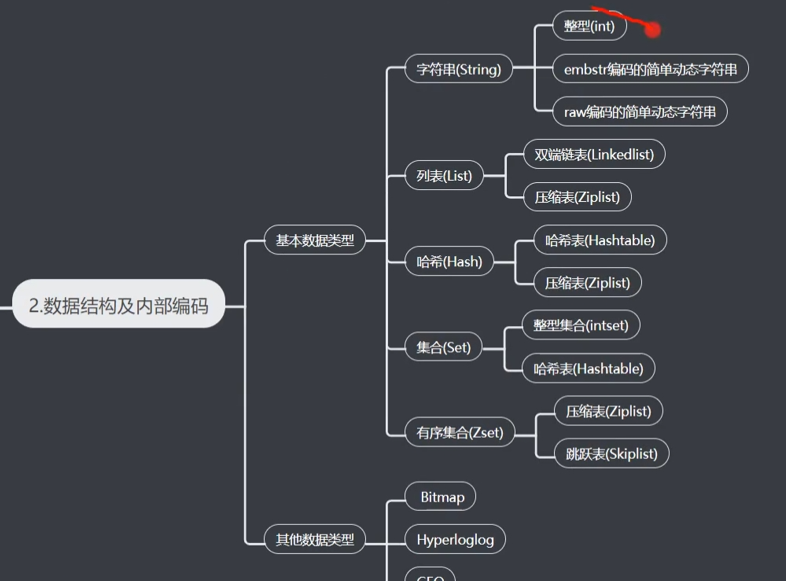
zset:默认ziplist存储,在数据量达到一定数量下(配置文件可定制),使用跳表skipList实现
二、应用场景
万亿级日访问量下,Redis在微博的9年优化历程 https://cloud.tencent.com/developer/news/462944 ~~干货满满
转载:https://blog.csdn.net/qq_42046105/article/details/95272836
首先介绍一下业务背景:总用户量大概是 5亿左右,月活 5kw,日活近 2kw 。服务端有 1000 多个 Redis 实例,100+ 集群,每个实例的内存控制在 20g 以下。
典型场景:
KV 缓存,分布式锁,延时队列,定时任务,频率控制,服务发现,位图,模糊计数,布隆过滤器
网站访问统计、分布式Session、应用排行榜、社交关系图
KV 缓存
基本使用:用 Redis 来缓存用户信息、会话信息、商品信息等等
当数据量不断增长时,就使用 Codis 或者 Redis-Cluster 集群来扩容。
除此之外 Redis 还提供了缓存模式,Set 指令不必设置过期时间,它也可以将这些键值对按照一定的策略进行淘汰。
打开缓存模式的指令是:config set maxmemory 20gb ,这样当内存达到 20gb 时,Redis 就会开始执行淘汰策略,给新来的键值对腾出空间。
这个策略 Redis 也是提供了很多种,总结起来这个策略分为两块:划定淘汰范围,选择淘汰算法。
比如我们线上使用的策略是 allkeys-lru。这个 allkeys 表示对 Redis 内部所有的 key 都有可能被淘汰,不管它有没有带过期时间,而volatile只淘汰带过期时间的。
当这个范围圈定之后,会从中选出若干个名额,怎么选择呢,这个就是淘汰算法。
最常用的就是 LRU 算法,它有一个弱点,那就是表面功夫做得好的人可以逃过优化。 Redis 4.0 里面引入了 LFU 算法,要对平时的成绩也进行考核,只做表面功夫就已经不够用了,还要看你平时勤不勤快。
最后还一种极不常用的算法 —— 随机摇号算法,这个算法有可能会把 CEO 也给淘汰了,所以一般不会使用它。
分布式锁
使用场景
给你一个亿的keys,Redis如何统计? https://new.qq.com/omn/20210105/20210105A04VDK00.html