索引的本质
索引是帮助mysql高效获取数据的排好序的数据结构
索引数据结构
常见的数据结构有:
二叉树
红黑树
hash表
B-Tree
下面以具体示例了解各索引结构的工作模式
示例:select * from t where t.col2=89;
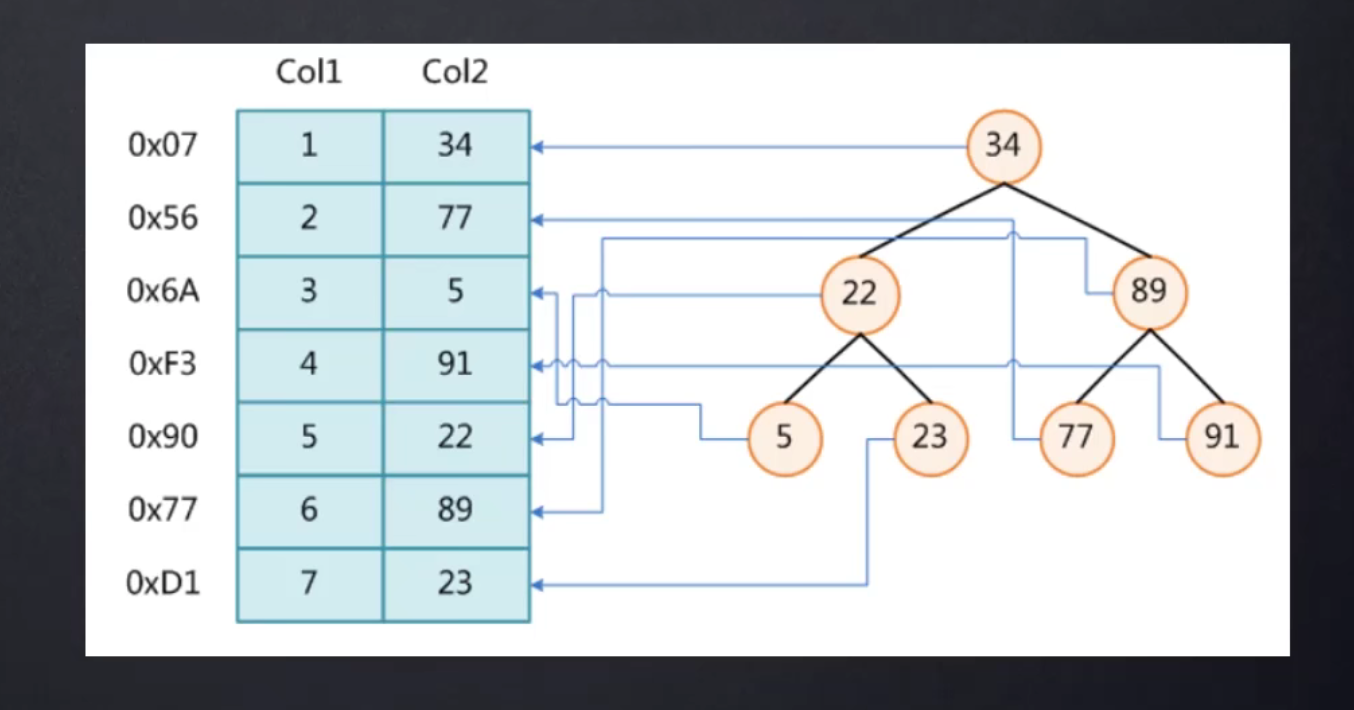
没有索引的情况下,是要一条一条去查询
学习数据结构的一个国外的网站:www.cs.usfca.edu/~galles/visualization/Algorithms.html
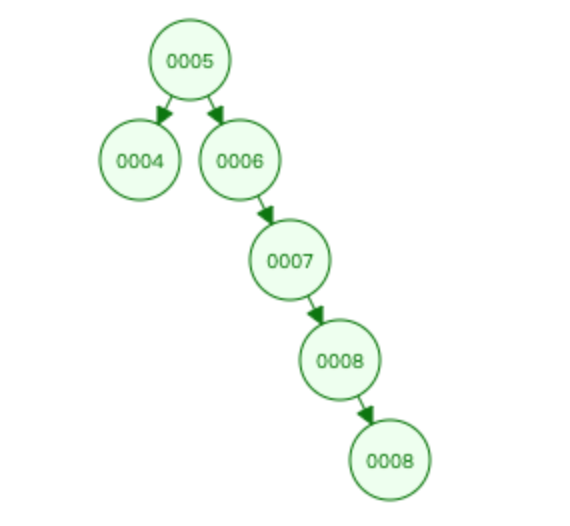
二叉树不适合单边增长的数据结构
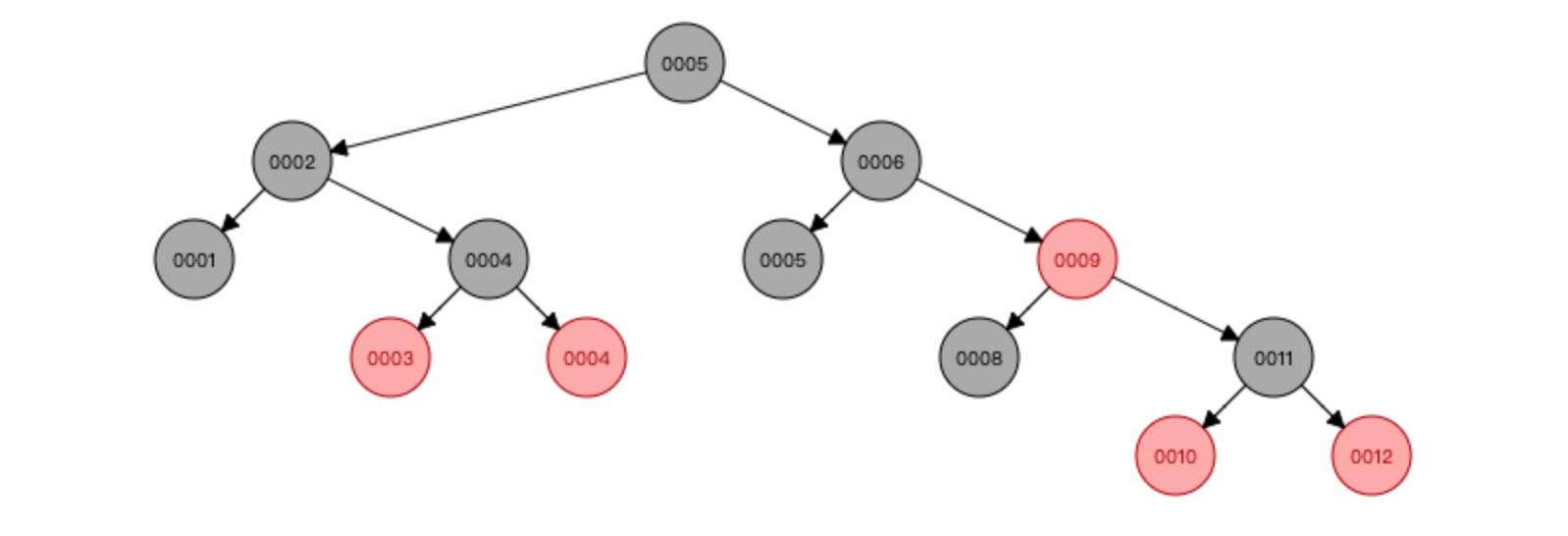
红黑树也叫二插平衡树 会自平衡,但是当数据量非常大的时候,它的树的高度是不可控的。
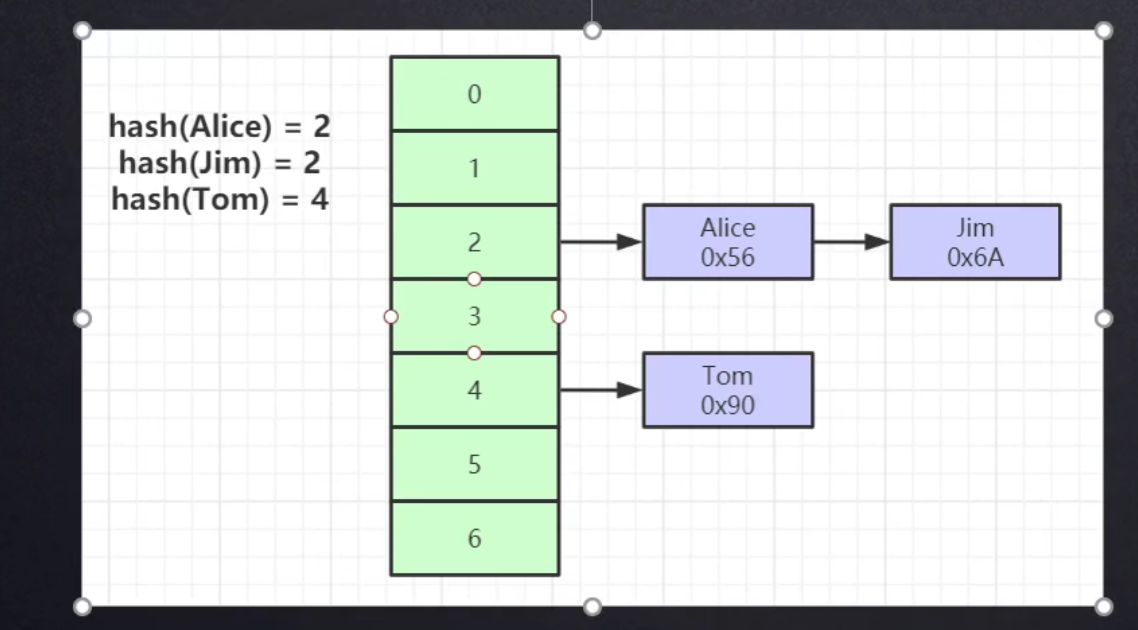
Hash表
对索引的key进行一次hash计算就可以定位出数据存储的位置
很多时候Hash索引要比B+ 树索引更高效
仅能满足“=” ,“IN”,不支持范围查询
hash冲突问题
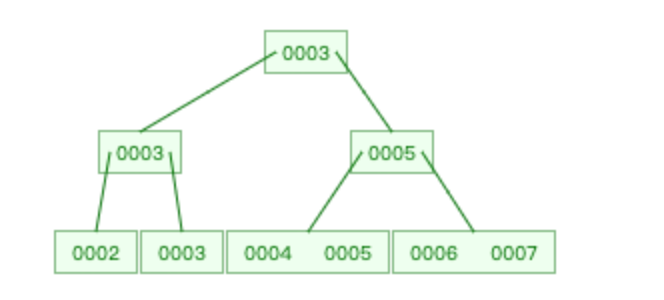
B-Tree
B-Tree是对红黑树进行的改进
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列


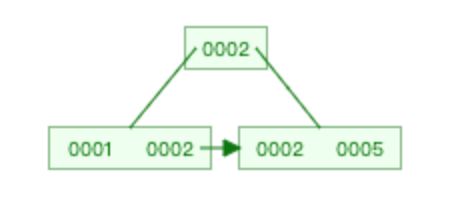
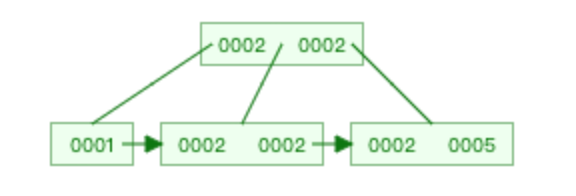
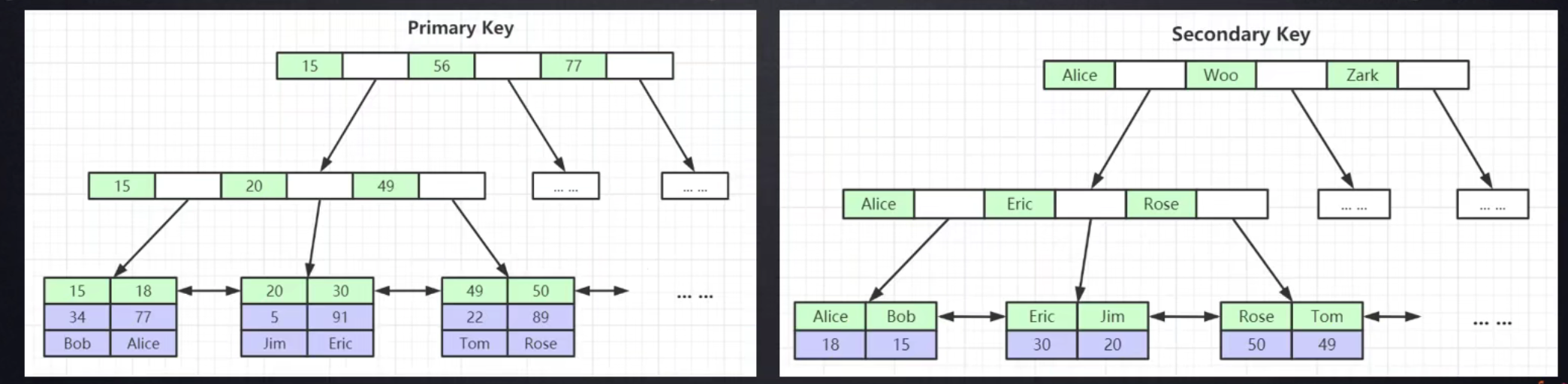
B+ Tree(B-Tree变种)
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能
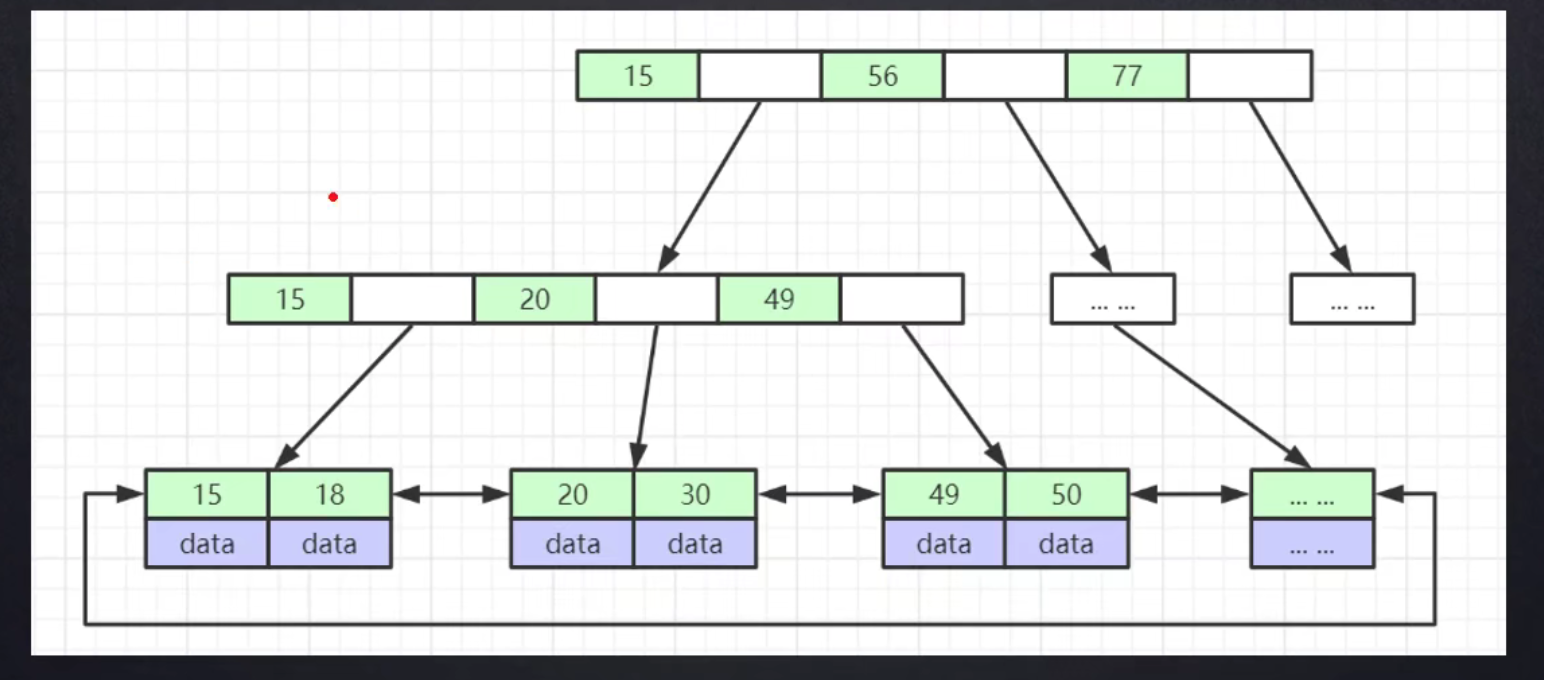
问题1:B - Tree和B+ Tree有何区别?
B-树的索引节点带有数据,而B+树非叶子节点不带有数据; B树叶子节点的指针为空,B+树叶子节点用指针连接,提高了区间访问的性能。
问题2:所有节点如果都放在一行,一次IO行不行?
肯定不行,数据量小还没什么,但是几千万个索引数据都加载到内存中,内存空间肯定会爆炸。而且全部加载到内存中,查找起来也不见得会有多快。
mysql设置的默认页大小查询
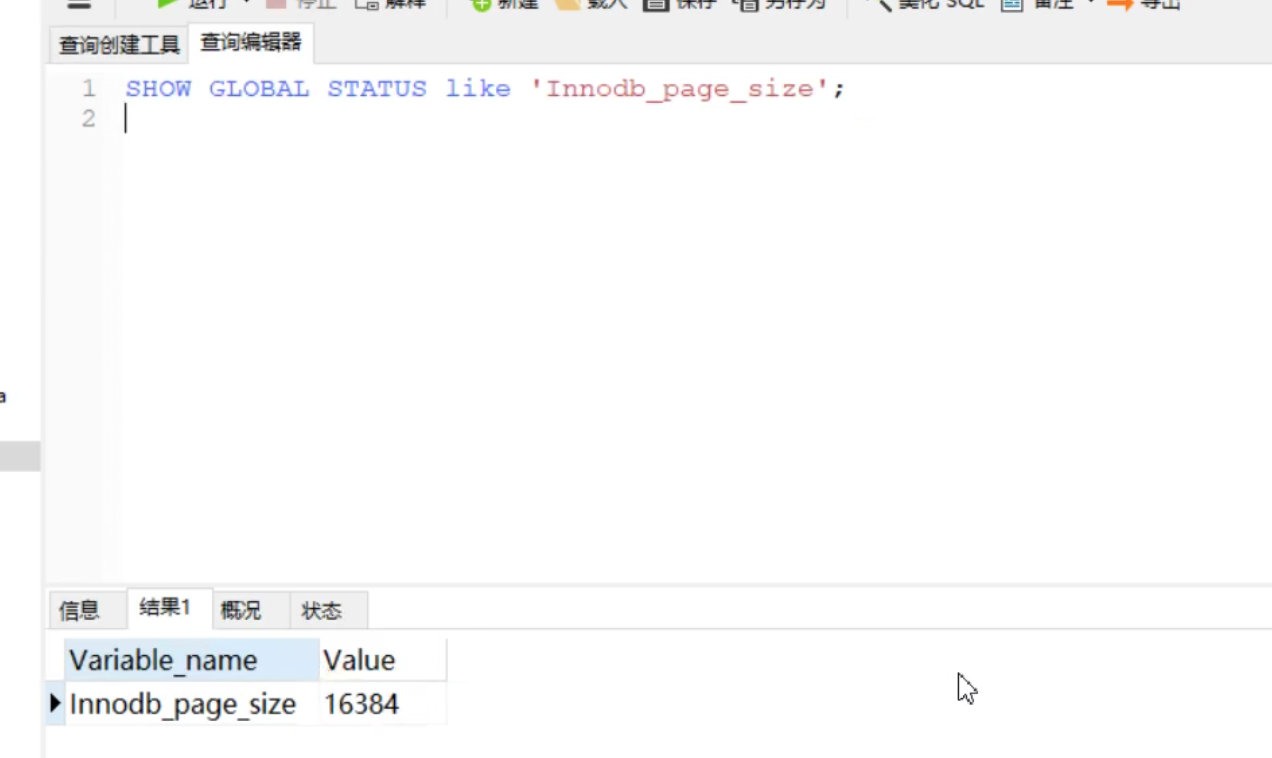
默认页大小大约为16kB大小
那么我们来计算一下,B+树大概能存放多少数据?
假设B+树的深度为3,我们的索引用bigint来修饰,每个索引占8个字节,存储一个索引时那个分叉节点的磁盘文件地址大约占6个字节,所以存储一个索引大概需要14个字节,那么这个页存满索引时大概能存储多少个索引?16KB/14B=1170个。
叶子节点的数据假设为1KB,一个叶子节点大概能放16KB/1KB=16个索引元素,那么叶子节点都放满后,大概能放1170*1170*16=2000多万个索引元素。
MyISAM存储引擎索引实现
MyISAM索引文件和数据文件是分离的(非聚集)
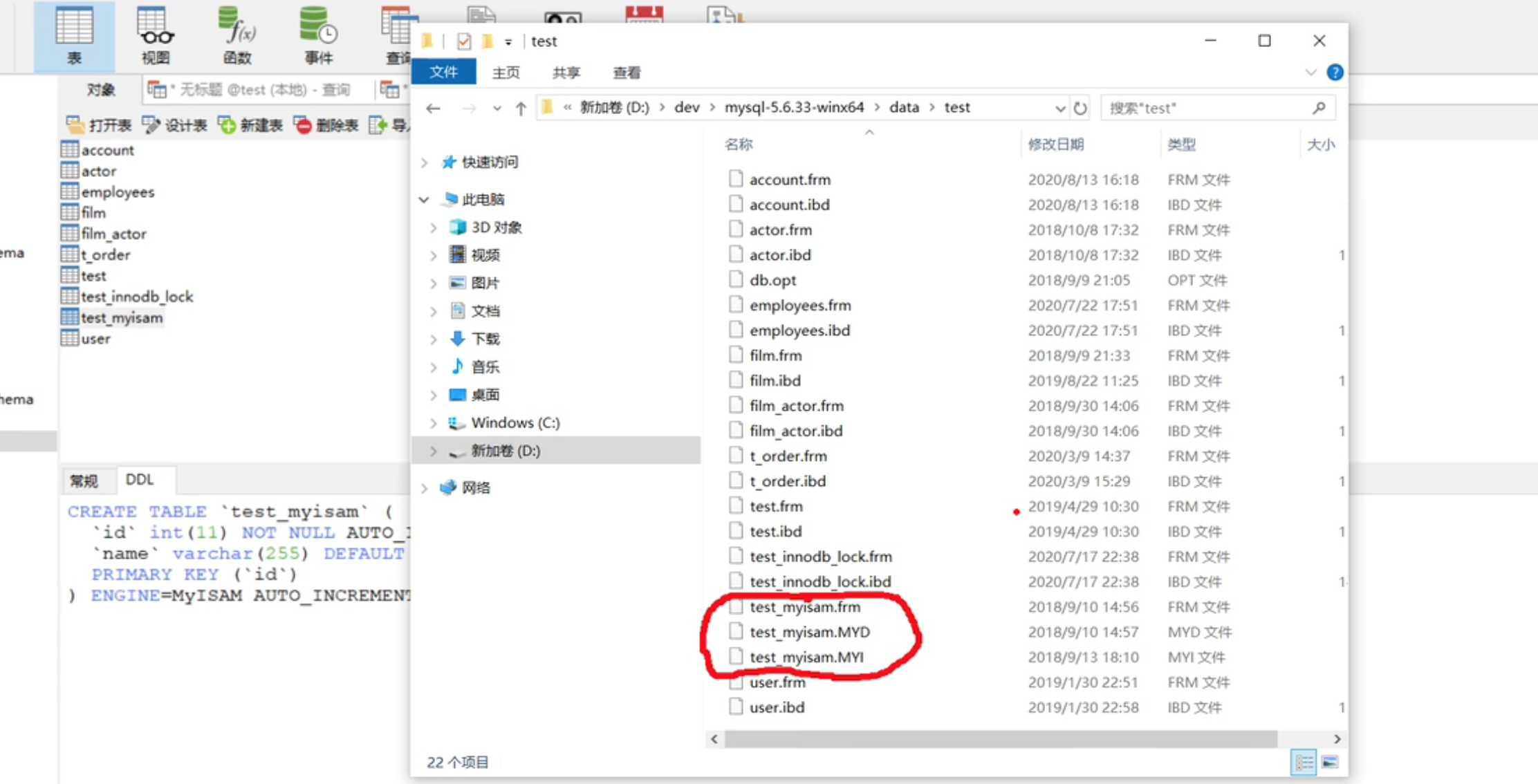

myisam:叶子节点中索引对应的data元素存储的是索引所在行的磁盘文件的地址
执行过程:实际上第一步是到MYI文件中定位到这个索引所在行的磁盘文件地址,然后拿着这个地址到MYD文件中快速的定位到这一行的记录。
InnoDB索引实现(聚集)
表数据文件本身就是按B+ Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
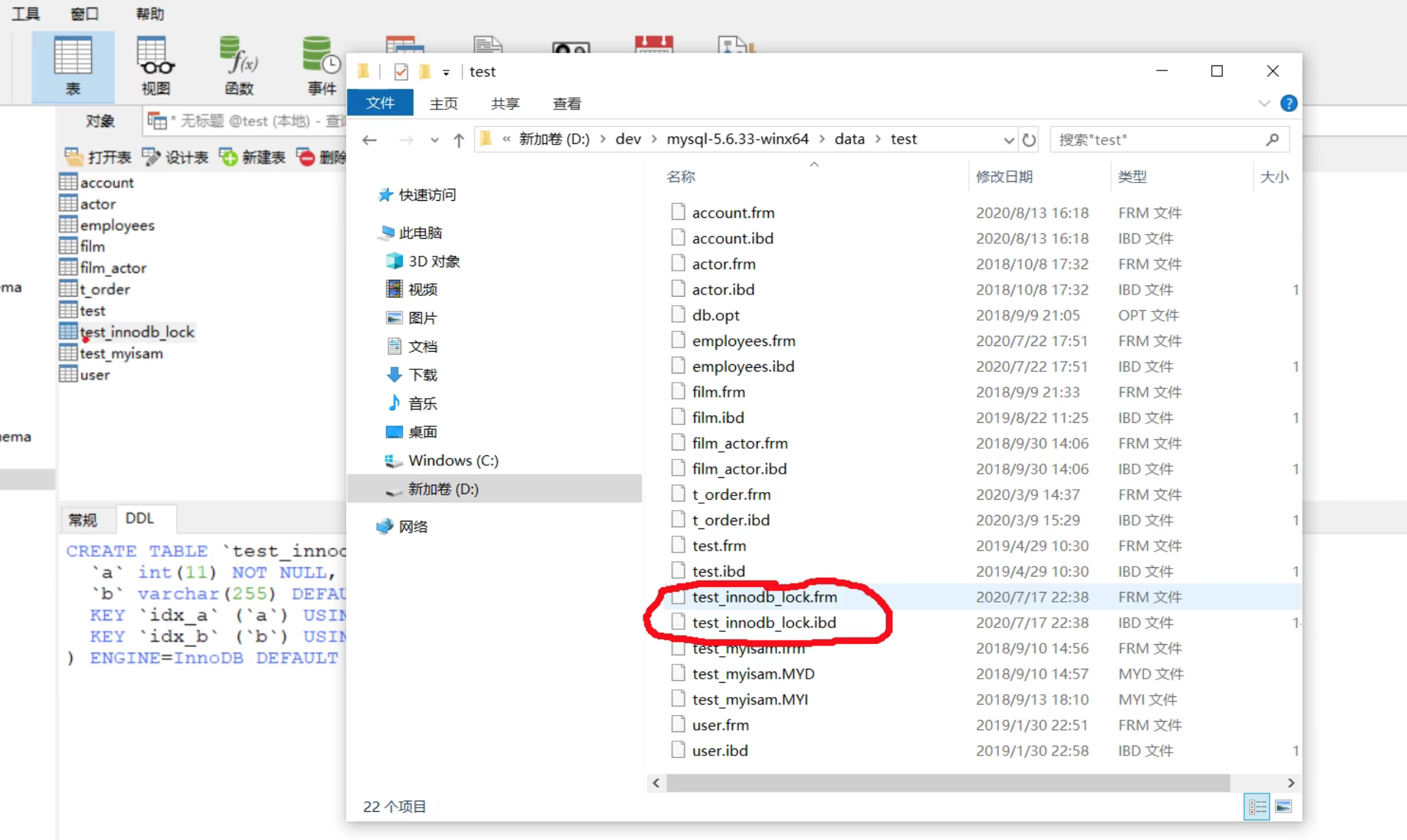
frm存储的是表结构,ibd存储的是索引和数据
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
如果没有建索引,mysql会自动去表中找一列不相等的数据到B+树中来维护整张表的所有数据。如果没有找到,mysql会在后台帮你建一隐藏列数据,比如rowid。这显然是不合适的。所以我们要建主键。
整型的效率要高一点,整型占用的空间要小。不用自增的主键的话会影响数据写入表里面的性能。
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)