带花树算法学习笔记
难得yyb写了一个这么正式的标题
Q:为啥要学带花树这种东西啊?
A:因为我太菜了,要多学点东西才能不被吊打
Q:为啥要学带花树这种东西啊?
A:因为我做自己的专题做不动了,只能先去“预习”ppl的专题了
Q:为啥要学带花树这种东西啊?
A:因为可以用来做题啊,比如某WC题目
先推荐一个很皮很皮的带花树讲解:
戳这里嗷
QaQ
言归正传
带花树的算法用来解决一般图的最大匹配问题
说起来,是不是想起来网络流里面的最小路径覆盖?
或者二分图的最大匹配的问题?
的确,带花树解决一般图的最大匹配问题类似于这些东西。
但是肯定是有不同的。
比方说:
我们用匈牙利的思路来解决一般图
我们是可以很容易就让算法挂掉的
只需要一个奇环就可以啦
(让我偷张图片过来)
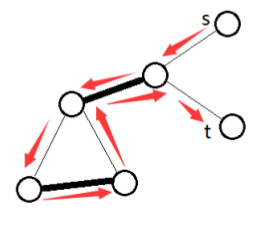
看见没有
有了一个奇环,在匹配的时候黑白就会翻转过来。
所以我们当然不能直接用匈牙利来做。
但是,这样的问题当然需要解决,
所以就有了带花树算法。
你可以理解为:
带花树算法=匈牙利算法+处理奇环
因为不打算长篇大论,
我按照带花树的步骤来写写这个算法。
(随时对比匈牙利算法)
匈牙利算法第一步:找到一个未被匹配的点,从这个点开始匹配
带花树算法第一步:找到一个未被匹配的点,从这个点开始匹配
貌似没有区别。。。
接下来匈牙利算法会用(dfs)来寻找增广路
带花树算法使用(bfs)
将当前点丢进队列里面
我们将他染个色,比如说黑色
然后开始(bfs)
首先取出队首的黑点(u)
找找和它相邻的点(v,(u,v)in E)
如果(v)是白点并且在当前的这一次匹配中已经被访问过,则不管这个点
否则,如果当前点(v)没有被访问过,并且(v)没有匹配点
那么就是找到了一条增广路
记录每一个点的前驱(pre),每个点的匹配点(match)
从当前的点(v)开始,每个点都和他的前驱两两匹配
沿着增广路全部修改回去就行了,
然后这一次的匹配结束。(这个跟匈牙利是一样的啊)
如果这个点已经有匹配点的话,则去尝试能否修改它的匹配点
因此,这个时候把(v)的前驱置为(u),然后把(v)的匹配点丢进队列里面。(这也是和匈牙利一样的啊)
继续(bfs),尝试能否修改它的匹配点。
对于上面的情况,明显和匈牙利算法是一模一样的,
但是出现了匈牙利不能解决的情况,也就是奇环。
如果当前黑点(u)的相邻点扩展出来了一个黑点(v),
意味着(u-v-u)构成了一个奇环
那么我们就要缩环啦,这就是带花树算法的重点。
对于一个奇环,它的点的个数一定是(2k+1)的形式
意味着,在奇环内最多只有(k)组匹配,
同时,一定有一个点会向外匹配(匹配点不在环内)
现在,如果我们把整个奇环都看成一个点
如果某个增广路找到了奇环上去,我们一定能够重置奇环内的匹配
无非是把增广路找到的奇环上的那个点和增广路上的其他点匹配。
然后奇环剩下的(2k)个点两两匹配。
所以,我们可以直接把奇环看成一个点来缩,这个就是开花啦
如果增广路找到了奇环上,我们就把奇环展开重新更新一下匹配就好。
可是,问题是,怎么缩奇环???
我们额外维护一个并查集,将同朵花中的节点在并查集中合并
我们先求出他们的最近花祖先
这个要怎么理解?
我们的匹配((match))和前驱((pre))都是边
如果把已经缩好的奇环都看成一个点
那么,这些边和点,就是一棵树。
假设现在出现了(u-v)这条边
意味着在树上出现了一个基环(当然也是奇环)
那么,从当前的(u,v)所在的奇环开始(如果只有一个点就是它自己啦)
不断的向上走交替地沿着(match)和(pre)边向上
当然了,每次走当然要走到他所在的奇环(并查集的根节点)所代表的那个位置啦(这是朴素的、暴力的(lca)求法)
所以求(lca)的代码如下:
int lca(int u,int v)
{
++tim;u=getf(u);v=getf(v);
while(dfn[u]!=tim)
{
dfn[u]=tim;
u=getf(pre[match[u]]);
if(v)swap(u,v);
}
return u;
}
(dfn)就是一个标记而已,你在向上跳的时候一边跳一边打标记
如果你在跳完另外一个点后发现这个位置已经被打了标记,
那么就意味着这个点就是(lca)啦
好的,我们求出来了(LCA),考虑怎么缩环(开花)
先上代码我再来解释
void Blossom(int x,int y,int w)
{
while(getf(x)!=w)
{
pre[x]=y,y=match[x];
if(vis[y]==2)vis[y]=1,Q.push(y);
if(getf(x)==x)f[x]=w;
if(getf(y)==y)f[y]=w;
x=pre[y];
}
}
(x,y)是要开花的奇环的两个点(也就是上面的(u,v))
(w)是他们的(LCA)
此时(x,y)之间可以匹配,但是他们都是黑点。
因为整朵花缩完都是一个黑点
因此,我们把(x->lca),(v->lca)的路径全部处理即可
因为两部分相同,因此只需要写一个(Blossom)函数
看看这个开花是怎么执行的
首先把(x,y)用(pre)连接起来(默认一朵花中未匹配的点就是(lca),也就是花根)
然后沿着(x)(或者(y))向上一个个点往上跳
如果跳到某个点是白点,但是花中的所有点都是黑点
所以把白点暴力染黑,然后丢进队列中增广
在跳的过程中,很可能中间跳的是若干个已经缩完的花(缩过的花也是点,但是在维护(pre)的时候,还是需要沿着这朵花暴跳,因为还需要维护每个点的匹配信息,只考虑一朵花的话没法维护所有点的信息)
所以在跳跃的过程中,暴力把所有访问到的节点和花的并查集全部合并到(lca)上面,表示他们的花根是(lca)。
感觉我写的很不清晰
总而言之,我们来总结一下带花树算法的流程
1.每次找一个未匹配的点出来增广
2.在增广过程中,如果相邻点是白点,或者是同一朵花中的节点,则直接跳过这个点
3.如果相邻点是一个未被匹配过的白点,证明找到了增广路,沿着原有的(pre)和(match)路径,对这一次的匹配结果进行更新
4.如果相邻点是一个被匹配过的白点,那么把这个点的匹配点丢进队列中,尝试能否让这个点的匹配点找到另外一个点进行匹配,从而可以增广。
(以上步骤同匈牙利算法)
5.如果相邻点是一个被匹配过的黑点,证明此时出现了奇环,我们需要将这个环缩成一个黑点。具体的实现过程是:找到他们的最近花公共祖先,也就是他们的花根,同时,沿着当前这两个点一路到花根,将花上的所有节点全部染成黑点(因为一朵花都是黑点),将原来的白点丢进栈中。同时,修改花上所有点的(pre),此时,只剩下花根并不与花内的节点相匹配。
以下是(UOJ79)模板题的代码
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<set>
#include<map>
#include<vector>
#include<queue>
using namespace std;
#define ll long long
#define RG register
#define MAX 555
#define MAXL 255555
inline int read()
{
RG int x=0,t=1;RG char ch=getchar();
while((ch<'0'||ch>'9')&&ch!='-')ch=getchar();
if(ch=='-')t=-1,ch=getchar();
while(ch<='9'&&ch>='0')x=x*10+ch-48,ch=getchar();
return x*t;
}
struct Line{int v,next;}e[MAXL];
int h[MAX],cnt=1;
inline void Add(int u,int v){e[cnt]=(Line){v,h[u]};h[u]=cnt++;}
int match[MAX],pre[MAX],f[MAX],vis[MAX],tim,dfn[MAX];
int n,m,ans;
int getf(int x){return x==f[x]?x:f[x]=getf(f[x]);}
int lca(int u,int v)
{
++tim;u=getf(u);v=getf(v);
while(dfn[u]!=tim)
{
dfn[u]=tim;
u=getf(pre[match[u]]);
if(v)swap(u,v);
}
return u;
}
queue<int> Q;
void Blossom(int x,int y,int w)
{
while(getf(x)!=w)
{
pre[x]=y,y=match[x];
if(vis[y]==2)vis[y]=1,Q.push(y);
if(getf(x)==x)f[x]=w;
if(getf(y)==y)f[y]=w;
x=pre[y];
}
}
bool Aug(int S)
{
for(int i=1;i<=n;++i)f[i]=i,vis[i]=pre[i]=0;
while(!Q.empty())Q.pop();Q.push(S);vis[S]=1;
while(!Q.empty())
{
int u=Q.front();Q.pop();
for(int i=h[u];i;i=e[i].next)
{
int v=e[i].v;
if(getf(u)==getf(v)||vis[v]==2)continue;
if(!vis[v])
{
vis[v]=2;pre[v]=u;
if(!match[v])
{
for(int x=v,lst;x;x=lst)
lst=match[pre[x]],match[x]=pre[x],match[pre[x]]=x;
return true;
}
vis[match[v]]=1,Q.push(match[v]);
}
else
{
int w=lca(u,v);
Blossom(u,v,w);
Blossom(v,u,w);
}
}
}
return false;
}
int main()
{
n=read();m=read();
for(int i=1;i<=m;++i)
{
int u=read(),v=read();
Add(u,v);Add(v,u);
}
for(int i=1;i<=n;++i)if(!match[i])ans+=Aug(i);
printf("%d
",ans);
for(int i=1;i<=n;++i)printf("%d ",match[i]);puts("");
return 0;
}