1. 前提条件
1.1 创建3台虚拟机,且配置好网络,建立好互信。
1.2 Java1.8 环境配置
1.4 Scala软件包和Spark软件包的下载
https://www.scala-lang.org/download/
http://spark.apache.org/downloads.html
2. 安装scala和spark
2.1 开启三台虚拟机,xshell连接上
2.2 打开工具栏的发送键输入到所有会话,操作三台虚拟机
2.3 上传安装包到/opt/install/目录下 rz
2.4 解压包到/opt/software/目录下,修改目录名
tar -zxvf 包 -C 目录
mv 文件夹名 新文件夹名
2.5 配置环境
vi /etc/profile
#加入
export SCALA_HOME=/opt/install//scala
export SPARK_HOME=/opt/install//spark
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin
退出使立即生效:source /etc/profile
配置spark
3.1 spark-env.sh配置
cd /opt/software/spark/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
#添加如下内容:
export JAVA_HOME=/opt/software/jdk8
export SCALA_HOME=/opt/software/scala
export HADOOP_HOME=/opt/software/hadoop277
export HADOOP_CONF_DIR=/opt/software/hadoop277/etc/hadoop
#主机名
export SPARK_MASTER_HOST=linux24
#Spark应用程序Application所占的内存
export SPARK_WORKER_MEMORY=1g
#Worker占用的CPU核数
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/software/spark
#hadoop安装目录下
export SPARK_DIST_CLASSPATH=$(/opt/software/hadoop277/bin/hadoop classpath)
3.2 slaves配置(只配主节点一台)
cp slaves.template slaves
vim slaves
#加入主机名,注意配置主机名映射
linux24
linux25
linux26
3. 启动spark
#spark目录下,防止冲突
sbin/start-all.sh
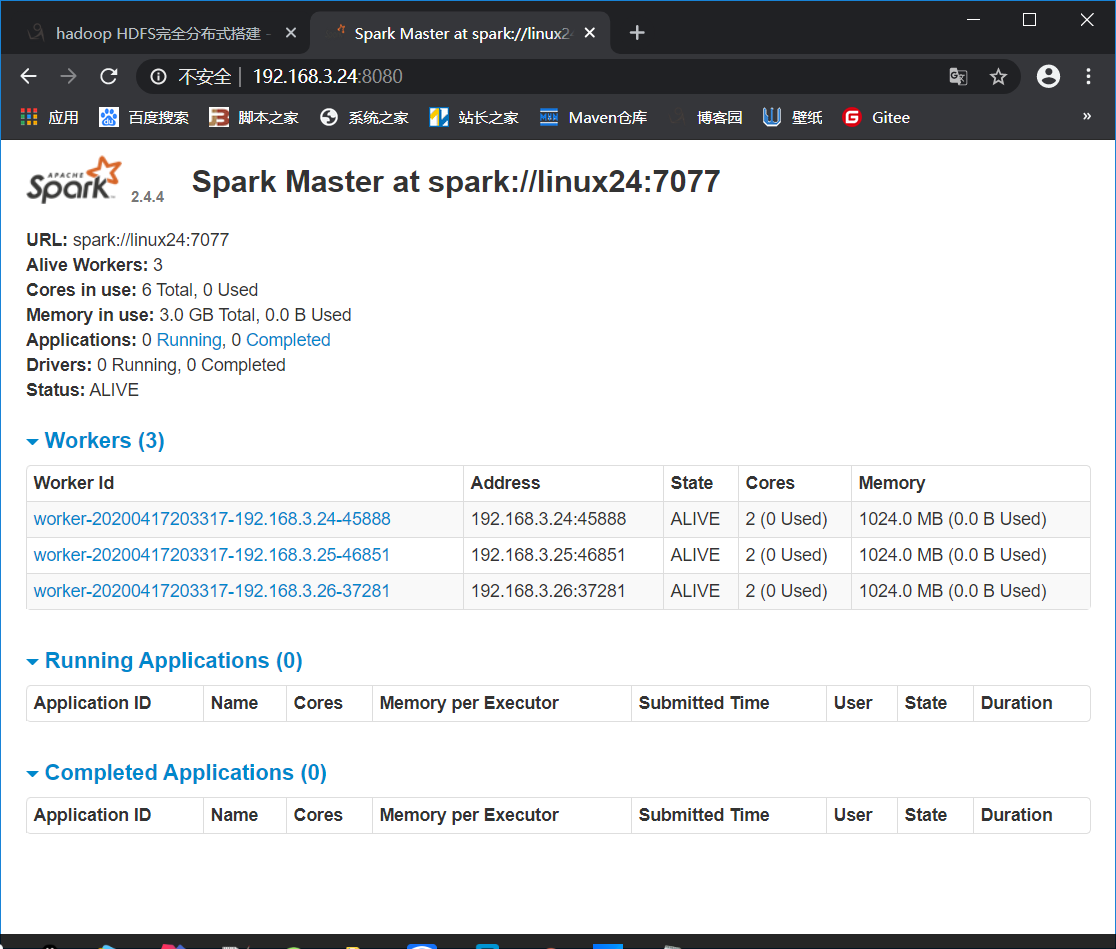
4. 查看http://主节点ip:8080