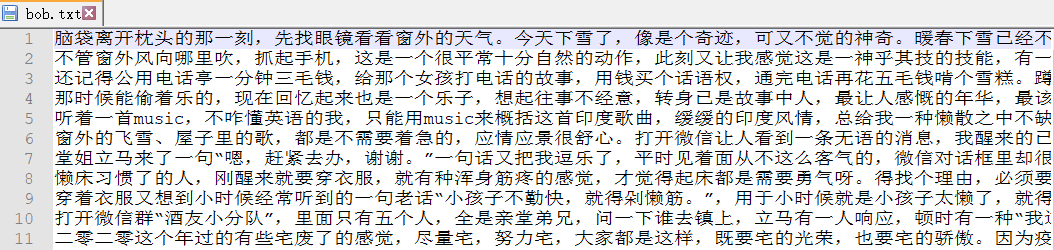
1. 准备数据源
摘录了一片散文,保存格式为utf-8
2. 准备环境
2.1 搭建伪分布式环境
上传数据源文件到hdfs中创建的in目录下
2.2 下载相关资源
下载hadoop277
链接:https://pan.baidu.com/s/1xeZx4AVxcjU33hoMLvOojA
提取码:mxic
下载hadoop可执行程序 winutils.exe
链接:https://pan.baidu.com/s/1mPsKk3_TgynAKfJN-kkjSw
提取码:3bfe
2.3 配置环境
2.3.1 配置hadoop的bin和sbin的环境变量
2.3.2 配置Administator访问权限
#两种方式都可
#2.3.2.1 关闭访问权限
<property> #core-site.xml
<name>dfs.permissions</name>
<value>false</value>
</property>
#2.3.2.2 授权
hadoop fs -chmod 777 文件路径
2.4 将资源放到对应位置
1.将hadoopBin.rar中的所有文件拷到hadoop的bin文件夹下
2.将hadoop-2.7.7/share/hadoop里common,hdfs,mapreduce,yarn四个文件夹下的jar包加入到项目中
3. 准备代码
3.1 开发Map类(继承Mapper类)
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//从文本中读出一行
String line = value.toString();
//将这一行字符串变成字符数组
char[] charArray = line.toCharArray();
//遍历每一个字符
for(char a:charArray) {
//将字符以 字符 1 的格式一行行输出到临时文件中
context.write(new Text(a+""), new IntWritable(1));
//注:MapReduce中有自己的数据类型,需进行转换
}
}
}
3.2 开发Reduce类(继承Reduce类)
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context content) throws IOException, InterruptedException {
//设计一个变量统计总数
int num = 0;
//遍历数据中整数部分
for(IntWritable v:values) {
//get()获得int类型的整数,然后累加
num += v.get();
}
//以 字符 总数 的格式输出到指定文件夹
content.write(key, new IntWritable(num));
}
}
3.3 开发Driver类
public class WordCountDriver{
public static void main(String[] arge) {
System.setProperty("hadoop.home.dir", "F:\Linux\hadoop-2.7.7");
//配置访问地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.3.8:9000");
try {
//获得job任务对象
Job job = Job.getInstance(conf);
//设置driver类
job.setJarByClass(WordCountDriver.class);
//设置Map类
job.setMapperClass(WordCountMapper.class);
//设置Map类输出的key数据的格式类
job.setMapOutputKeyClass(Text.class);
//设置Map类输出的value数据的格式类
job.setMapOutputValueClass(IntWritable.class);
//设置Reduce类 如果Reduce类输出格式类与Map类的相同,可不写
job.setReducerClass(WordCountReduce.class);
//设置Map类输出的key数据的格式类
job.setOutputKeyClass(Text.class);
//设置Map类输出的value数据的格式类
job.setOutputValueClass(IntWritable.class);
//设置被统计的文件的地址
FileInputFormat.setInputPaths(job, new Path("/in/bob.txt"));
//设置统计得到的数据文件的存放地址
//注:文件所在的文件夹需不存在,由系统创建
FileOutputFormat.setOutputPath(job, new Path("/out/"));
//true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束
job.waitForCompletion(true);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
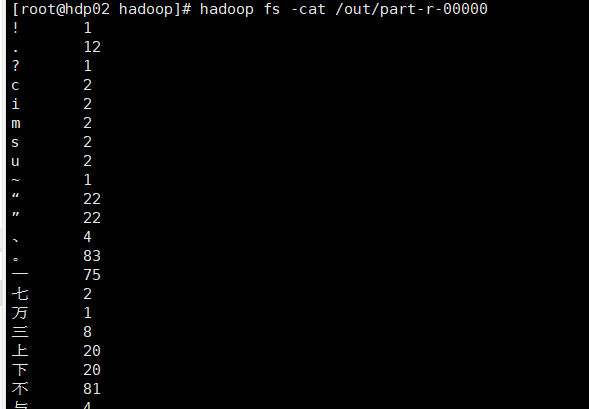
4. 统计结果

5. 相关问题
5.1 问题一
Input path does not exist: file:/in/bob.txt
解决:检查访问地址及相关配置
5.2 问题二
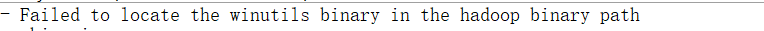
解决:环境变量没配置好或还没生效(选择以下其中一种即可)
- 配置好hadoop环境变量,重启eclipse
- 加入代码System.setProperty("hadoop.home.dir", "F:Linuxhadoop-2.7.7"),见reduce类代码
5.3 问题三

解决:见上文2.3.2
5.4 问题四
中文乱码
解决:
1.确保eclipse编码格式为utf-8
2.数据源文件保存格式为utf-8
3.使用转换流,字节流转字符流:new OutputStreamWrite(out,"UTF-8")
6. 拓展
6.1 打jar包
- 将FileInputFormat.setInputPaths(job, new Path("/in/bob.txt"))地址改为"/in/",统计in目录下所有文件
- 将此项目打成jar包上传到Linux系统/opt/test目录下
- 运行jar包,代码:hadoop jar jar包名 ,便可得到统计结果
- 以后便可将数据源文件放置于in文件夹中,直接运行jar包进行统计(统计前需删掉hdfs中的out文件夹)
6.2 使用hadoop-eclipse插件开发
6.2.1 下载hadoop-eclipse-plugin
链接:https://pan.baidu.com/s/1mC2KaCMxCmrYL5_RaGTI2w
提取码:zgqg
将该插件放入eclipse的plugin文件夹中

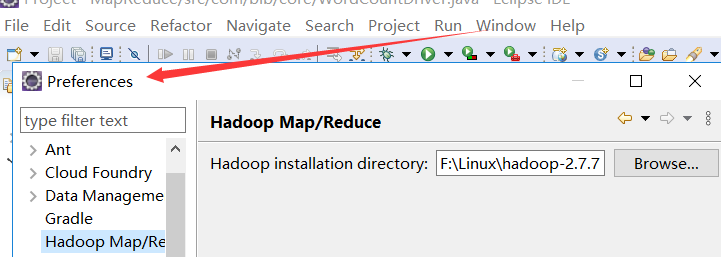
6.2.2 设置hadoop地址
6.2.3 创建项目
6.2.3.1 创建map/reduce项目
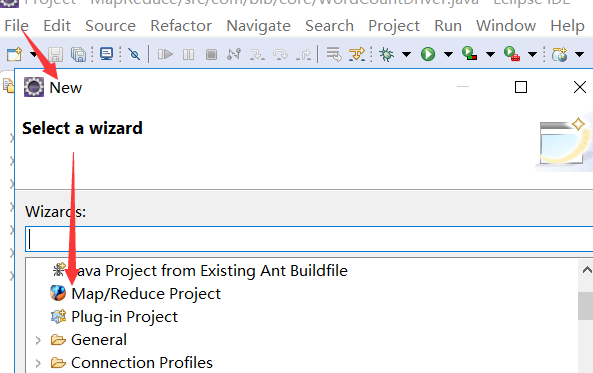
自动添加相关jar包
6.2.3.2 创建对应类
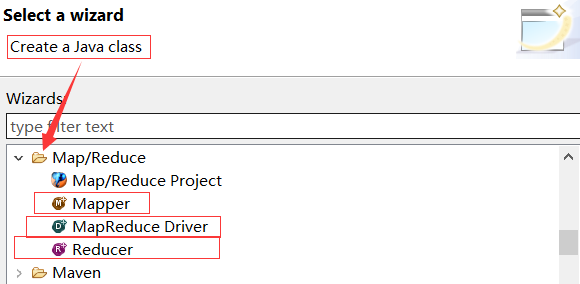
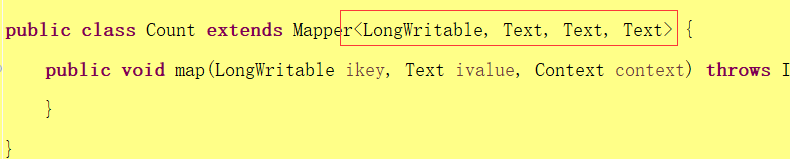
自动写入对应方法(可修改参数格式),如
6.2.4 设置MapReduce
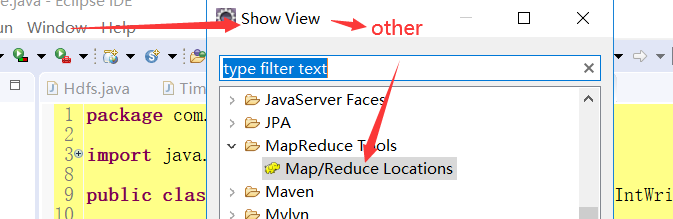

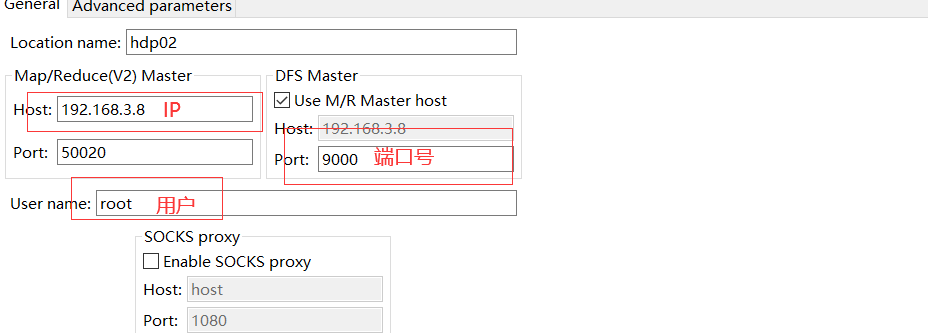

右键点击,选择操作,上传数据源文件或查看文件都便捷许多