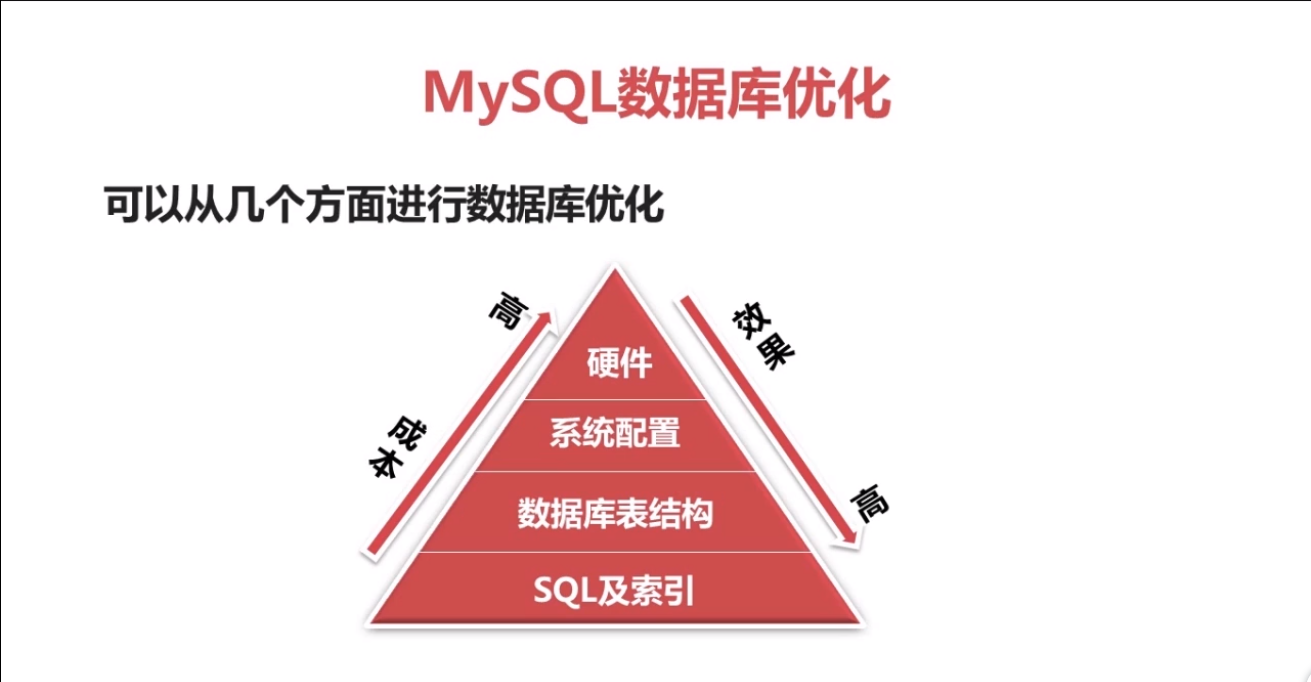
1.mysq 数据优化可以从以下几方面进行优化:
1、sql及索引优化。
2 数据库表结构,根据数据设计查询最优的表结构。
3,系统配置优化,对打开文件数和安全的限制。
4、硬件,选择最适合数据库的cpu,更快的IO,更大的内存,cpu不是越多越好, IO并不能减少锁的机制,也就是不能减少阻塞,所以说硬件的优化成本越高,效果最差。
2.sql语句优化
2-1数据准备
访问http://dev.mysql.com/doc/index-other.html
下载,解压是两个sql文件

使用navicat执行两个sql文件,先执行schema.sql,然后执行data.sql,主要不需要自己建立数据库,自动创建
2-2 MySQL慢查日志的开启方式和存储格式
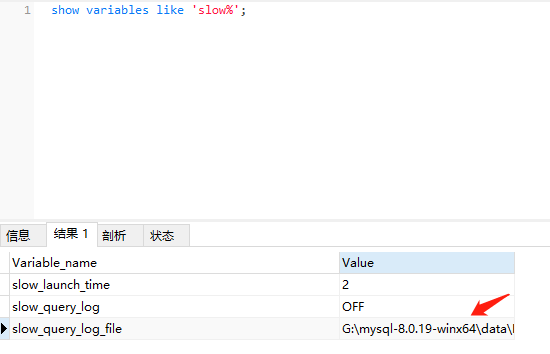
查看是否打开慢查询日志:
show variables like 'slow_query_log';
如果查到是off, 说明没有开启该功能, 使用如下命令开启:
set global slow_query_log=on;
查看是否将没有建立索引的查询列入慢查询记录:
show variables like '%log%';
显示的结果中有一项"log_queries_not_using_indexes"值为off, 说明没有开启, 使用下面的命令开启:
set global log_queries_not_using_indexes=on;
查看慢查询时间设置:
show variables like 'long_query_time';
显示的值为"0.00000"则表示要将所有查询记录到日志.
设置慢查询时间设置:
set global long_query_time=0;
设置为零则记录所有查询信息.
使用如下命令查看查询日志的文件位置:
show variables like 'slow%';
可以看到有一项"slow_query_log_file"的值为"G:mysql-8.0.19-winx64dataDESKTOP-91QBBK9-slow.log", 这就是慢查询日志文件的存放位置.
2-3 MySQL慢查日志分析工具之mysqldumpslow
mysqldumpslow工具的使用:
-
mysqldumpslow -t 3 慢查询日志文件路径 | more //表示使用mysqldumpslow工具分析3条慢查询语句
-
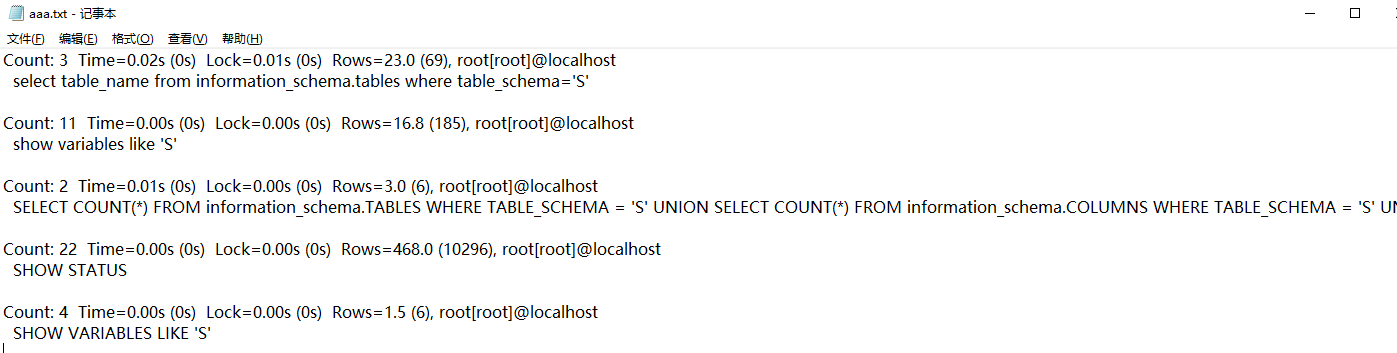
报表内容:
Count:执行的行数
Time: 执行的时间
Lock: 锁定时间
Rows: 行数
服务器信息
SQL内容等
因为我安装的是mysql 8,发现在mysql bin目录下是没有mysqldumpslow.exe文件,解决方法如下
https://blog.csdn.net/stevendbaguo/article/details/47128531
安装完成后
代表可以用了

然后我们打开G:Perlcjlog目录

打开text文件,查询访问
不会的话参考windows下使用MYSQL的mysqldumpslow进行慢日志分析
https://blog.csdn.net/qq_31879707/article/details/79501222
2.4MySQL慢查日志分析工具之pt-query-digest
因为我是window,所以需要下载pt-query-digest,然后把该文件扔到mysql的bin目录下
安装教程
https://blog.csdn.net/hansonjan/article/details/103856370
命令行

打开bbb.txt就可以查看
2.5如何通过慢查日志发现有问题的SQL

2-6 通过explain查询和分析SQL的执行计划
2.6.1max

如何分析SQL查询:
explain返回各列的含义
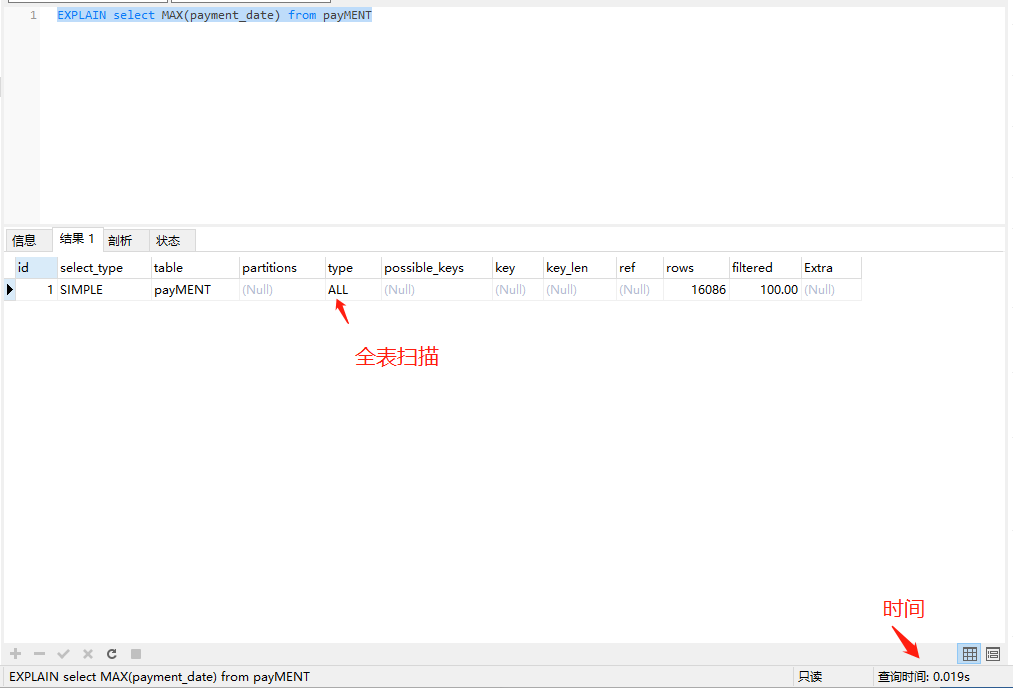
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好的到最差的连接类型为const/eq_reg/ref/range/index和ALL
possiable_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。
key:实际使用的索引。如果为Null,则没有使用索引。
key_len:使用的索引的长度,在不损失精确性的情况下,长度越短越好。
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows:MYSQL认为必须检查的用来返回请求数据的行数。

mysql中explain的type的解释https://blog.csdn.net/dennis211/article/details/78170079

2.7count()和max()的优化
EXPLAIN select MAX(payment_date) from payMENT
给支付时间列建立索引
create index idx_paydate on payMENT(payment_date);

再做查询看看
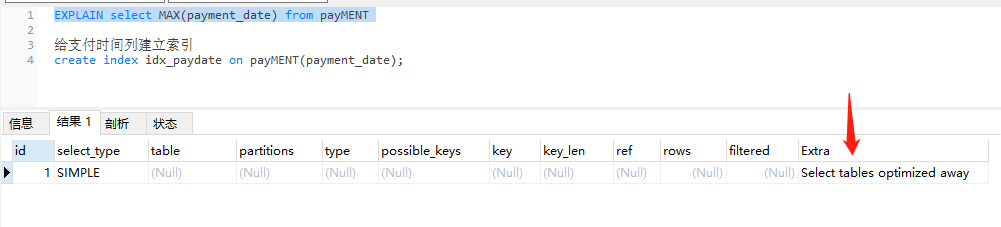
翻译解决为选择已优化的表
2.6.2count
需求:countz() 在同一条SQL中同时查询出2006和2007年电影的数量
错误示范

正常情况下我们只能分两次查询
select count(*) from film where release_year=2006; select count(*) from film where release_year=2007;
优化后如下
select count(*) from film where release_year=2007 or release_year=2006 group by release_year ORDER BY release_year;
结果,因为没有release_year=2007的情况,所以只能显示一条数据
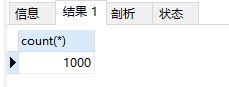
我们修改数据库中一条数据为2007

再做刚刚的查询

发现能够查询出来,但是不知道是哪个年份
继续优化
select count(release_year='2006' or null) as '2006年电影数量',count(release_year='2007' or null)as '2007年电影数量' from film;

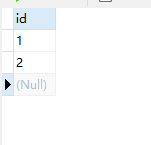
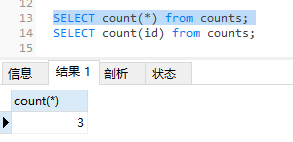
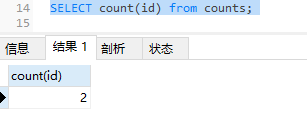
这里区分一下count(*)和count(字段的区别),两者是不一样的
创建counts表

新增表数据
2.8子查询优化
新增表counts2
插入一条数据
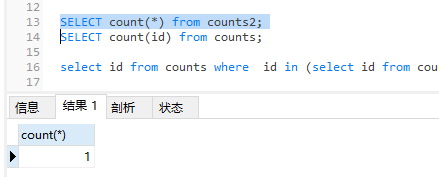
sql
select id from counts where id in (select id from counts2 );
优化sql
select c.id from counts c JOIN counts2 c2 on c.id=c2.id
存在问题,如果counts表和counts2表中数据是一对多的关系呢
在counts2表中新增一条数据id=1
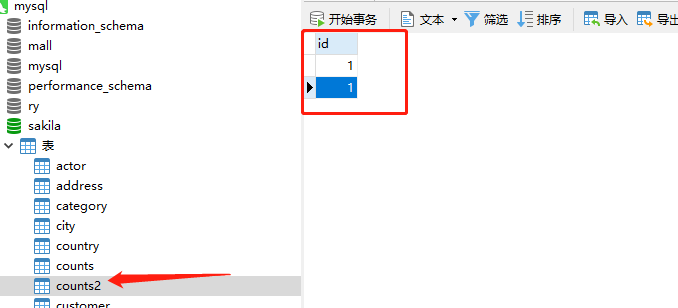
因为此时是一对多的关系,如果我们还是用上面的查询sql,就会出现多条数据
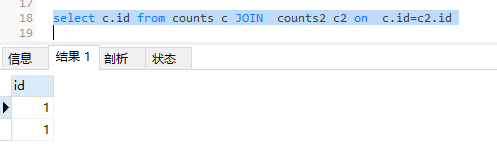
继续优化sql
select DISTINCT c.id from counts c JOIN counts2 c2 on c.id=c2.id
2.9GROUP BY优化
需求:查询演员表演了多少电影
sql如下
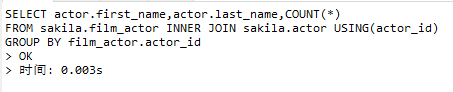
EXPLAIN SELECT actor.first_name,actor.last_name,COUNT(*)
FROM sakila.film_actor INNER JOIN sakila.actor USING(actor_id)
GROUP BY film_actor.actor_id
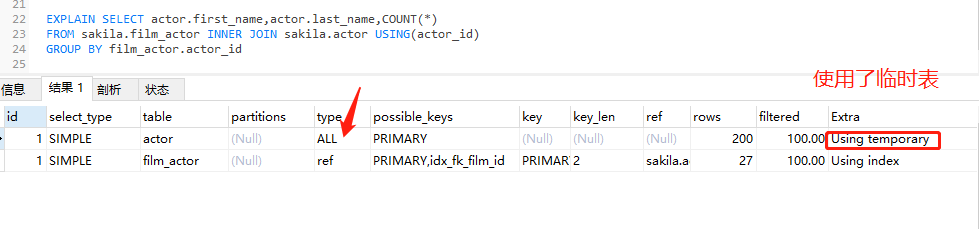
耗时
优化
EXPLAIN SELECT actor.first_name,actor.last_name,c.cnt FROM sakila.actor INNER JOIN (SELECT actor_id,count(*) AS cnt FROM sakila.film_actor GROUP BY actor_id) as c USING (actor_id)
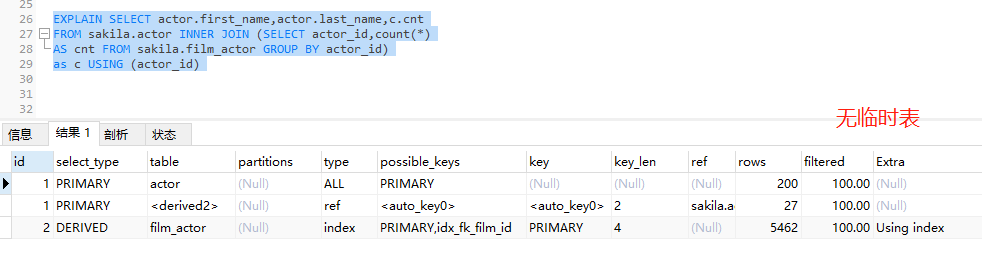
耗时
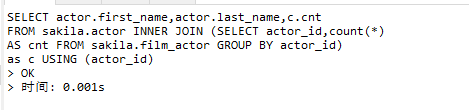
2.10limit查询的优化
limit常用于分页处理,时常会伴随order by从句使用,因此大多时候会使用Filesorts这样会造成大量的io问题
分页sql:
select film_id , description from sakila.film order by title limit 500,10

优化1.使用有索引的列或主键进行order by操作
EXPLAIN select film_id , description from sakila.film order by film_id limit 500,10

继续优化2.记录上次返回的主键,在下次查询时使用主键过滤
select film_id,description from sakila.film where film_id >500 and film_id<=510 order by film_id limit 1,10;
注意使用这种方式有一个限制,就是主键一定要顺序排序和连续的,如果主键出现空缺可能会导致最终页面上显示的列表不足5条,解决办法是附加一列,保证这一列是自增的并增加索引就可以了
3.索引优化
3.1如何选择合适的列建立索引
选择合适的索引列
1.在where,group by,order by,on从句中出现的列
2.索引字段越小越好(因为数据库的存储单位是页,一页中能存下的数据越多越好 )
3.离散度大的列放在联合索引前面
select count(distinct customer_id), count(distinct staff_id) from payment;
是index(sftaff_id,customer_id)好?还是index(customer_id,staff_id)好呢?
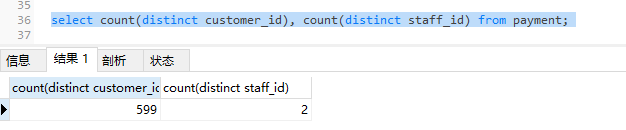
判断某一列的离散度:select count(distinct 字段名)from 表名;返回的结果值越大,说明离散度越大,建立联合索引时,应该放到前面;

3.2索引优化sql的方法
去除重复索引

冗余索引

优化方案

3.3索引维护的方法
没什么好讲的,视频讲的拉的一笔
4.数据库结构优化
4.1选择合适的数据类型

使用int来存储日期时间

创建表语句
CREATE TABLE test(id INT auto_increment not NULL ,timestr int ,PRIMARY KEY(id));
插入表语句
INSERT INTO test(timestr) VALUES (UNIX_TIMESTAMP('2020-07-16'));
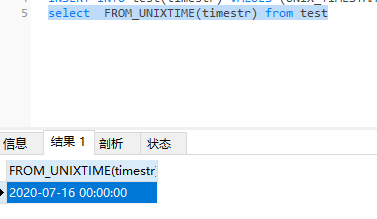
查询表语句
select FROM_UNIXTIME(timestr) from test
查询结果
使用bigint来存储IP地址,最多使用8个字节,如果使用varchar来存储的话最多得15个字节

建表sql
CREATE TABLE SESSIONs(id INT auto_increment not NULL,
ipaddress BIGINT,PRIMARY key(id));
新增sql
insert into SESSIONs(ipaddress) VALUES(INET_ATON('192.168.56.100'));
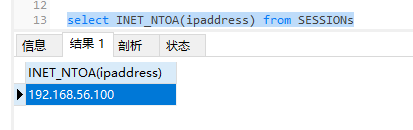
查询sql
select INET_NTOA(ipaddress) from SESSIONs
查询结果
4.2数据库表的范式化优化
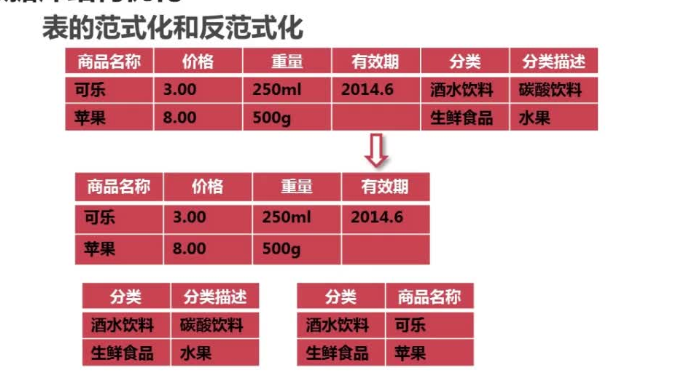
表的范式化即数据库设计的规范化:数据表不存在非关键字段对任意关键字段的传递函数依赖,则符合第三范式。
可以将一张数据表进行拆分,来满足第三范式的要求。
设计表的时候符合范式化是为了:减少数据冗余、减少表的插入、更新、删除异常
设计表的时候使用反范式化是为了:以空间换时间、增强代码的可编程性和可维护性
不符合第三范式要求的表存在以下问题:
1.数据冗余:(分类、分类描述)对于每一个商品都会进行记录
2.数据插入异常
3.数据更新异常
4.数据删除异常

解决方案(表拆分)
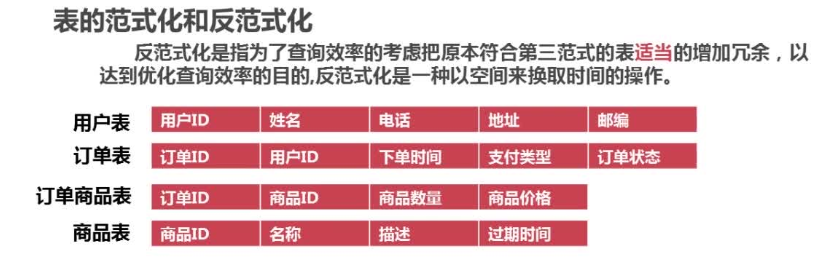
4.3数据库反范式化优化
反范式化:为了查询效率的考虑,把原本符合第三范式的表适当增加冗余,以达到优化查询效率的目的。以空间换取时间的操作
例子:
sql:

优化:
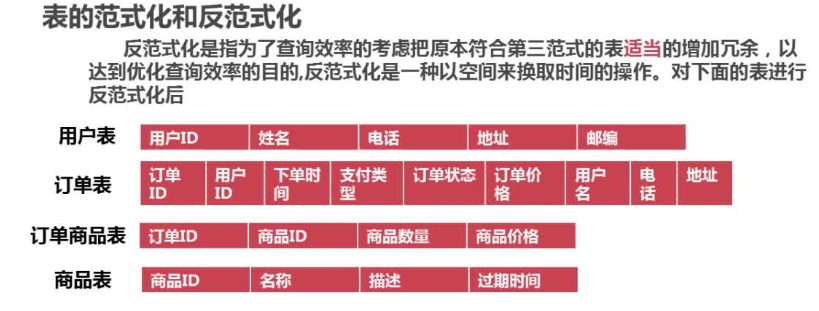
sql:

4.4数据库表的垂直拆分
表垂直拆分 1.不经常用得放在同一个表中 2.经常用得放在同一个表中 3.大的字段单独放在一个表中

例子

拆分


4.5数据库表的水平拆分
-
表的垂直拆分:将表中的不常用的列和大字段的列拆分到另外一个表或者多个表中,减少表的宽度;
-
表的水平拆分:主要是解决数据量过大的问题,水平拆分每个表的表结构都是完全一致的(当单表的数据大于一亿时,尽管加了索引,还是会比较慢);
-
水平拆分方法:对id进行hash运算(取模),如果拆分为5个表,则使用mod(id)取出0-4个值,针对不同的hashID吧数据存到不同的表中;
例子:

解决
