CenterNet算法介绍(学习自objects as points)
论文依据:objects as points
CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如 肢体识别或者3D目标检测 等等,我们团队当下在实现的主要是目标检测的部分。

与传统的one-stage和two-stage的区别:
- CenterNet的“anchor”(锚)仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是背景 - 因为每个目标只对应一个“anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16)。
网络结构与前提条件
-
网络结构
论文中CenterNet提到了三种用于目标检测的网络,这三种网络都是编码解码(encoder-decoder)的结构:
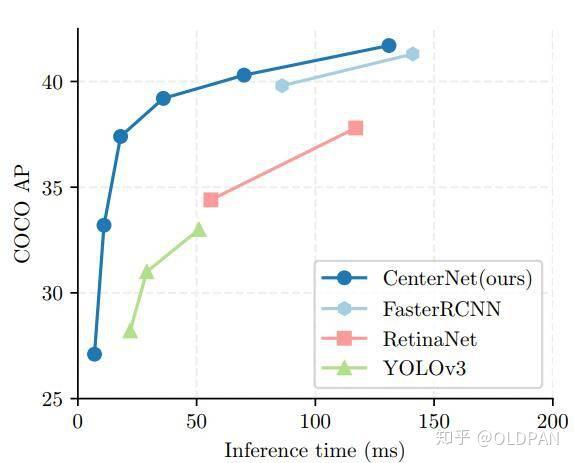
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
每个网络内部的结构不同,但是在模型的最后都是加了三个网络构造来输出预测值,默认是80个类、2个预测的中心点坐标、2个中心点的偏置。
用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量,这些值在后文中会有讲述。
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
-
检测方法
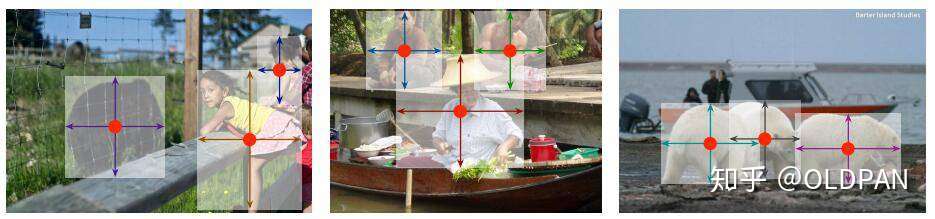
首先假设输入图像为 ![[公式]](https://www.zhihu.com/equation?tex=I+%5Cin+R%5E%7BW+%5Ctimes+H+%5Ctimes+3%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=W) 和 ![[公式]](https://www.zhihu.com/equation?tex=H) 分别为图像的宽和高,然后在预测的时候,我们要产生出关键点的热点图(keypoint heatmap): ![[公式]](https://www.zhihu.com/equation?tex=%5Chat%7BY%7D+%5Cin+%5B0%2C1%5D%5E+%7B%5Cfrac%7BW%7D%7BR%7D+%5Ctimes+%5Cfrac%7BH%7D%7BR%7D+%5Ctimes+C%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=R) 为输出对应原图的步长,而 ![[公式]](https://www.zhihu.com/equation?tex=C) 是在目标检测中对应着检测点的数量,如在COCO目标检测任务中,这个 ![[公式]](https://www.zhihu.com/equation?tex=C+) 的值为80,代表当前有80个类别。
插一段官方代码,其中 就是self.opt.down_ratio也就是4,代表下采样的因子。
# 其中input_h和input_w为512,而self.opt.down_ratio为4,最终的output_h为128
# self.opt.down_ratio就是上述的R即输出对应原图的步长
output_h = input_h // self.opt.down_ratio
output_w = input_w // self.opt.down_ratio
这样,
就是一个检测到物体的预测值,对于
,在当前
坐标中检测到了这种类别的物体,而
则表示当前当前这个坐标点不存在类别为
在整个训练的流程中,CenterNet学习了CornerNet的方法。对于每个标签图(ground truth)中的某一
类,我们要将真实关键点(true keypoint)
计算出来用于训练,中心点的计算方式为
,对于下采样后的坐标,我们设为
,其中
是上文中提到的下采样因子4。所以我们最终计算出来的中心点是对应低分辨率的中心点。
然后我们利用
来对图像进行标记,在下采样的[128,128]图像中将ground truth point以
来将关键点分布到特征图上,其中
是一个与目标大小(也就是w和h)相关的标准差。如果某一个类的两个高斯分布发生了重叠,直接取元素间最大的就可以。
这么说可能不是很好理解,那么直接看一个官方源码中生成的一个高斯分布[9,9]:

-
损失函数(中心点预测)
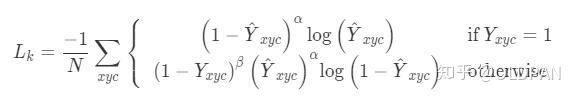
其中
和
是Focal Loss的超参数,
是图像
的的关键点数量,用于将所有的positive focal loss标准化为1。在这篇论文中
这个损失也比较关键,需要重点说一下。和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值。
当
的时候,
就充当了矫正的作用,假如
接近1的话,说明这个是一个比较容易检测出来的点,那么
就相应比较低了。而当

当
的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到
,因为当
则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为
在上文中已经提到,是一个高斯核生成的中心点,在中心点
,但是在中心点周围扩散
会由1慢慢变小但是并不是直接为0,类似于上图,因此
目标中心的偏置损失
因为上文中对图像进行了 的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,因此对于每一个中心点,额外采用了一个
local offset: 去补偿它。所有类
的中心点共享同一个
offset prediction,这个偏置值(offset)用L1 loss来训练:
上述公式直接看可能不是特别容易懂,其实 是原始图像经过下采样得到的,对于[512,512]的图像如果
的话那么下采样后就是[128,128]的图像,下采样之后对标签图像用高斯分布来在图像上撒热点,怎么撒呢?首先将box坐标也转化为与[128,128]大小图像匹配的形式,但是因为我们原始的
annotation是浮点数的形式(COCO数据集),使用转化后的box计算出来的中心点也是浮点型的,假设计算出来的中心点是[98.97667,2.3566666]。
推断阶段
在预测阶段,首先针对一张图像进行下采样,随后对下采样后的图像进行预测,对于每个类在下采样的特征图中预测中心点,然后将输出图中的每个类的热点单独地提取出来。具体怎么提取呢?就是检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),然后取100个这样的点,采用的方式是一个3x3的MaxPool,类似于anchor-based检测中nms的效果。
这里假设 为检测到的点,
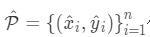
代表 类中检测到的一个点。每个关键点的位置用整型坐标表示
,然后使用
表示当前点的confidence,随后使用坐标来产生标定框:
其中
是当前点对应原始图像的偏置点,
代表预测出来当前点对应目标的长宽。
下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽:

后记
这篇论文(objects as points)厉害的地方在于:
- 设计模型的结构比较简单,像我这么头脑愚笨的人也可以轻松看明白,不仅对于two-stage( faster-rcnn ),对于one-stage( yolo )的目标检测算法来说该网络的模型设计也是优雅简单的。
- 该模型的思想不仅可以用于目标检测,还可以用于3D检测和人体姿态识别,虽然论文中没有是深入探讨这个,但是可以说明这个网络的设计还是很好的,我们可以借助这个框架去做一些其他的任务。
- 虽然目前尚未尝试轻量级的模型(这是我接下来要做的!),但是可以猜到这个模型对于嵌入式端这种算力比较小的平台还是很有优势的,希望大家多多尝试一些新的backbone(不知道mobilenetv3+CenterNet会是什么样的效果),测试一下,欢迎和我交流呀~
当然说了一堆优点,CenterNet的缺点也是有的,那就是:
- 在实际训练中,如果在图像中,同一个类别中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,也就是将这两个物体的当成一个物体来训练(因为只有一个中心点)。同理,在预测过程中,如果两个同类的物体在下采样后的中心点也重叠了,那么CenterNet也是只能检测出一个中心点,不过CenterNet对于这种情况的处理要比faster-rcnn强一些的,具体指标可以查看论文相关部分。
- 有一个需要注意的点,CenterNet在训练过程中,如果同一个类的不同物体的高斯分布点互相有重叠,那么则在重叠的范围内选取较大的高斯点。