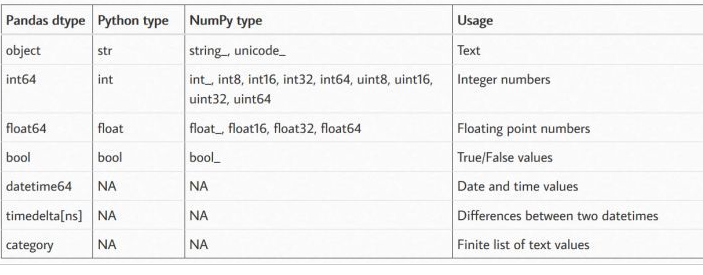

data.info()查看加载数据的相关信息
pandas的类型转化有三种,
使用astype()函数进行强制类型转换
自定义函数进行数据类型转换
使用Pandas提供的函数如to_numeric()、to_datetime()
1. astype
data['客户编号'].astype('object')
data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列

astype会失效的
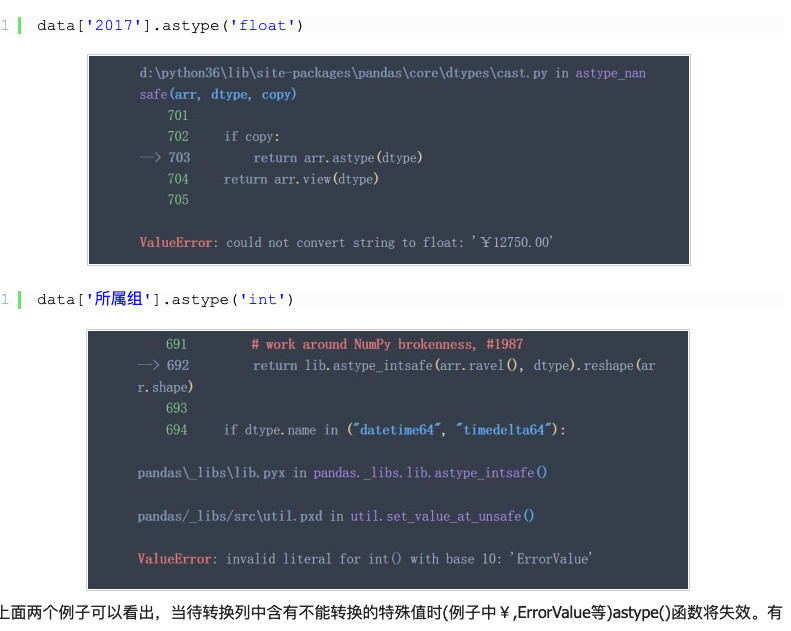
astype()函数有效的情形:
据列中的每一个单位都能简单的解释为数字(2, 2.12等)
数据列中的每一个单位都是数值类型且向字符串object类型转换
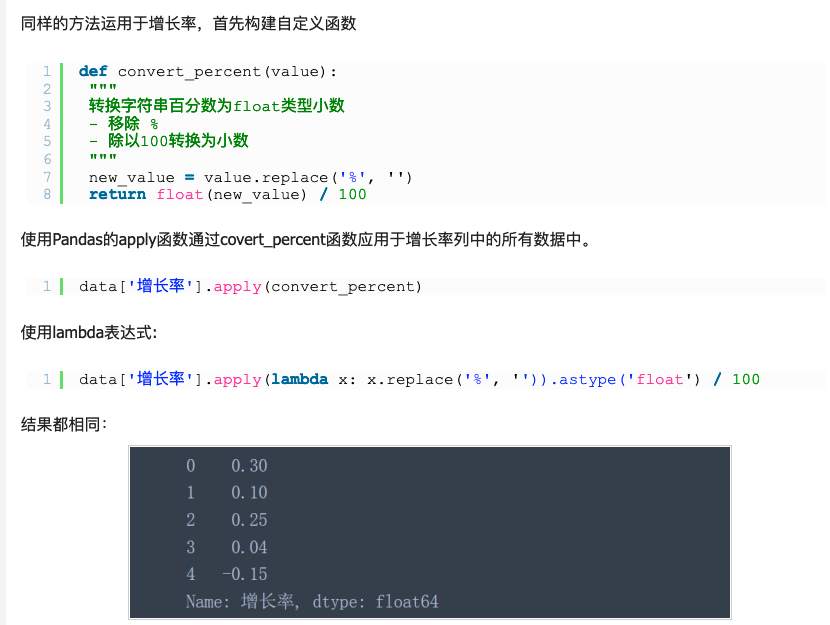
2. apply (函数内存对象) 自定义函数转化类型

#使用匿名函数
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
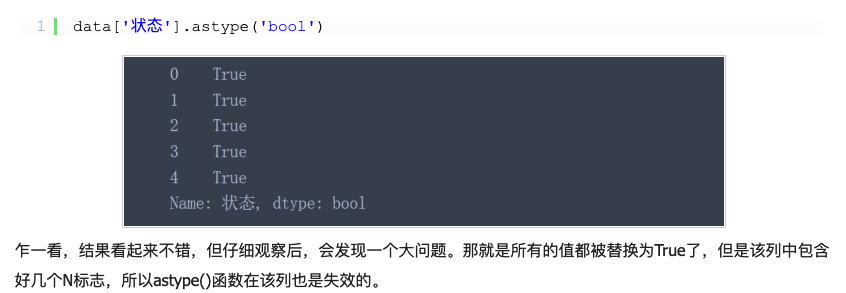
状态值的准话,可以使用numpy中的where函数,Y--True N--False
data['状态'] = np.where(data['状态'] == 'Y', True, False)
3. pandas的一些辅助函数
辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())。所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
对于astype的类型不同替换错误的问题,to_numeric做了默认值处理, 非数值的替换成了0,而且是可以指定的,
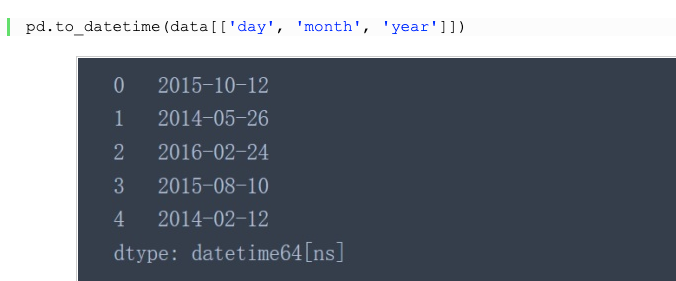
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
读取文件的时候直接进行类型转换
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')
pandas格式的问题
对于pd.style,虽然可以处理样式,也可以进行指定列的数值判断,但是有个问题是不能指定首行的样式列宽居中这些的,
所以可以重写pd的to_excel方法,在其中增加对excel的操作,
经过试验发现两个引擎,一个是openpyxl,一个xlsxwriter,这两个引擎各有优缺点
对于openpyxl,不足的一点是不能按照行按照列的处理样式,必须得一个cell一个cell的处理,虽然也可以用遍历,也能达到样式处理的效果,
使用openpyxl的好处是可以结合pd.style的样式处理,只需要专注于首行样式的处理即可。
#前提是engine使用的是openpyxl
#重写
pd.style.to_excel
from pandas.io.formats.style import Styler
#第一层继承Styler
#在内部添加需要的参数,重写write方法
#第二层继承ExcelFormatter,重写其中的write方法
from openpyxl.styles import Font, PatternFill, Alignment
header_font = Font(size=20, bold=True)
header_fill = PatternFill(fgColor='BFD1E9', fill_type='solid')
header_align = Alignment(horizontal='center', vertical='center', wrap_text=True)
header_border = Border(
left=Side(style='medium', color='FF000000'),
right=Side(style='medium', color='FF000000'),
top=Side(style='medium', color='FF000000'),
bottom=Side(style='medium', color='FF000000'),
)
for i in range(num_cols):
col_index = self.getColumnName(i + 1)
if i < 2:
worksheet.column_dimensions[col_index].width = self.col_width * 2
else:
worksheet.column_dimensions[col_index].width = self.col_width
worksheet[f'{col_index}2'].font = header_font
worksheet[f'{col_index}2'].fill = header_fill
worksheet[f'{col_index}2'].alignment = header_align
worksheet[f'{col_index}2'].border = header_border
worksheet.merge_cells(f'A1:{col_index}1')
worksheet['A1'] = '这是表的标题'
worksheet['A1'].font = header_font
worksheet['A1'].fill = header_fill
worksheet['A1'].alignment = header_align
worksheet['A1'].border = header_border
worksheet.row_dimensions[1].height = 30
writer.save()
xlsxwriter引擎
缺点是不能和pd.style配合使用,不过他自己就可以指定列来进行数值过滤。默认支持很多方法,而且支持图标生成嵌套,专注于excel表的生成,在生成之后就不能再更改,同时对行列样式的的修改支持很好
#引擎修改为xlsxwriter引擎
#第一层继承DataFrame
#加入额外的参数
#第二层继承ExcelFormatter,修改样式
workbook = writer.book
worksheet = writer.sheets[sheet_name]
first_header_font_fmt = workbook.add_format({
'font_name': u'微软雅黑',
'font_size': 18,
'align': 'center',
'valign': 'vcenter',
'bold': True,
'bg_color': '#9FC3D1',
'border': 1
})
second_header_font_fmt = workbook.add_format({
'font_name': u'微软雅黑',
'font_size': 15,
'align': 'center',
'valign': 'vcenter',
'bold': True,
'bg_color': '#D7E4BC',
'border': 1
})
body_font_fmt = workbook.add_format({
'font_name': u'宋体',
'font_size': 12,
'align': 'center',
'valign': 'vcenter',
'border': 1
})
highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2'})
# 设置列宽
worksheet.set_column('A:B', 30)
worksheet.set_column('C:{}'.format(self.getColumnName(num_cols)), 10)
# 设置数据样式
worksheet.set_column('A:{}'.format(self.getColumnName(num_cols)), cell_format=body_font_fmt)
# 设置title
worksheet.merge_range(0, 0, 0, num_cols - 1, title, first_header_font_fmt)
# 设置列名
for col_index, column_name in enumerate(self.df.columns):
worksheet.write(1, col_index, column_name, second_header_font_fmt)
len_column = len(self.df.index) + 2
filter_type = {
'between': 'between',
'not': 'notBetween',
'==': '==',
'!=': 'notEqual',
'>': 'greaterThan',
'<': 'lessThan',
'>=': 'greaterThanOrEqual',
'<=': 'lessThanOrEqual',
}
# 样式过滤,对值进行处理
highlight_info = {'type': 'cell', 'criteria': '', 'format': highlight_fmt}
for column_index, filter_type in filter_info.items():
for method, params in filter_type.items():
highlight_info['criteria'] = method
if method in ['between', 'notBetween']:
minimum, maximum = params.split(',')
highlight_info.update({'maximum': float(maximum), 'minimum': float(minimum)})
else:
highlight_info.update({'value': float(params)})
worksheet.conditional_format('{0}3:{0}{1}'.format(self.getColumnName(column_index), len_column),
highlight_info)
if need_save:
writer.save()
对于pd导出excel的参数中。startrow startcol可以给行列预留位置,然后指定样式,完美
pd.loc[4],包含4
pd.iloc[4] 不包含4
‘
pd导出多sheet的excel
