-
celery
http://www.pianshen.com/article/2176289575/
https://www.jianshu.com/p/9be4d8d30d8e
异步任务的调用方法:
1.result = add.delay(1, 2):这是apply_async方法的别名,但接受的参数较为简单;
2.result = add.apply_async(args=[1, 2], kwargs={'countdown':5, 'expires':60})
3.result = celeryapp.send_task('task.add', args=[1, 2]):可以发送未被注册的异步任务,即没有被celery.task装饰的任务;
apply_async 可以传递更多的参数,
eg:
countdown=5:等待5S后再执行, eta=now+tiedelta(second=20):指定任务的开始时间, expires=60:指定任务的超时时间,retry=True: 指定任务失败后是否重试
result.ready() 查看任务状态,返回布尔值, 任务执行完成, 返回 True, 否则返回 False.
result.get(timeout=5) 获取任务执行结果,可以设置等待时间
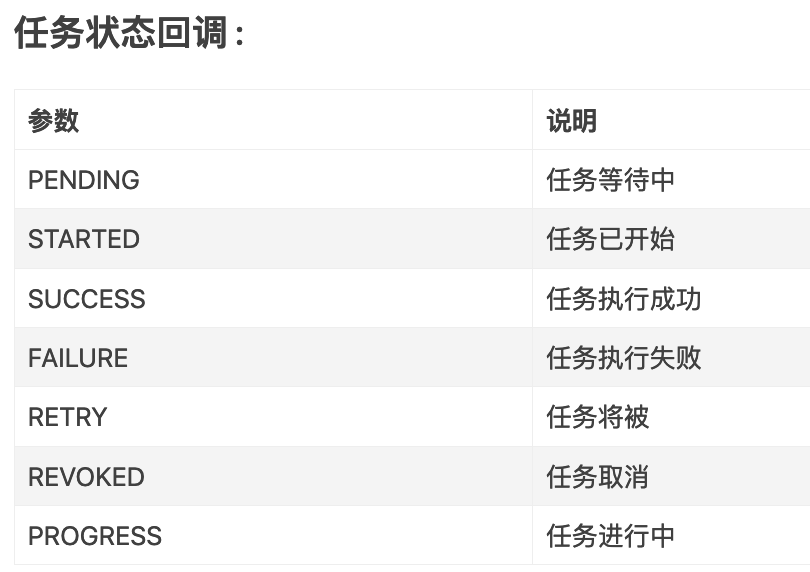
result.state # 查看任务当前的状态,
PENDING:任务等待中,
STARTED:任务已开始,
SUCCESS:任务执行成功,
FAILURE:任务执行失败,
RETRY: 任务将被重新执行,
REVOKED:任务取消,
PROCESS:任务执行中
result.traceback # 如果任务抛出异常, 可以获取完整的堆栈信息
任务的执行结果
执行结果保存到redis1号库, 在1号库会有类似下面格式的键, 其对应的值就是执行结果了.
键: celery-task-meta-080ee8b0-24c4-48a0-a2dd-a1bcebb45b5b
值: {
"status": "SUCCESS",
"result": 30,
"traceback": null,
"children": [],
"task_id": 080ee8b0-24c4-48a0-a2dd-a1bcebb45b5b
}
定时任务
from celery.schedule import crontab

crontab对象指定精确时间, 默认参数值都为'*' 意为每分钟都执行
这里指的是早上8点30


今天踩得坑是 在windows中,celery的定时任务不好使, 在linux环境下就没问题了, 不知道啥原因, 系统问题吧. 以后还是多用linux吧.
调用方法
1. delay
task.delay(args1, args2, kwargs=value_1, kwargs2=value_2)
2. apply_async
delay 实际上是 apply_async 的别名, 还可以使用如下方法调用, 但是 apply_async 支持更多的参数:
task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value})
countdown : 等待一段时间再执行.
add.apply_async((2,3), countdown=5)
eta : 定义任务的开始时间.
add.apply_async((2,3), eta=now+tiedelta(second=10))
expires : 设置超时时间.
add.apply_async((2,3), expires=60)
retry : 定时如果任务失败后, 是否重试.
add.apply_async((2,3), retry=False)
retry_policy : 重试策略.
max_retries : 最大重试次数, 默认为 3 次.
interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .
自定义发布者,交换机,路由键, 队列, 优先级,序列方案和压缩方法:
task.apply_async((2,2), compression='zlib',
serialize='json',
queue='priority.high',
routing_key='web.add',
priority=0,
exchange='web_exchange')
shell中直接调用
task.s()()
任务绑定, 记录日志, 重试
# 修改 tasks.py 文件.
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__)
@app.task(bind=True)
def div(self, x, y):
logger.info(('Executing task id {0.id}, args: {0.args!r}'
'kwargs: {0.kwargs!r}').format(self.request))
try:
result = x/y
except ZeroDivisionError as e:
raise self.retry(exc=e, countdown=5, max_retries=3) # 发生 ZeroDivisionError 错误时, 每 5s 重试一次, 最多重试 3 次.
return result
当使用 bind=True 参数之后, 函数的参数发生变化, 多出了参数 self, 这这相当于把 div 编程了一个已绑定的方法, 通过 self 可以获得任务的上下文.
信号系统
信号可以帮助我们了解任务执行情况, 分析任务运行的瓶颈. Celery 支持 7 种信号类型.
1 任务信号
before_task_publish : 任务发布前
after_task_publish : 任务发布后
task_prerun : 任务执行前
task_postrun : 任务执行后
task_retry : 任务重试时
task_success : 任务成功时
task_failure : 任务失败时
task_revoked : 任务被撤销或终止时
2 应用信号
3 Worker 信号
4 Beat 信号
5 Eventlet 信号
6日志信号
7 命令信号
# 在执行任务 add 之后, 打印一些信息.
@after_task_publish
def task_send_handler(sender=None, body=None, **kwargs):
print 'after_task_publish: task_id: {body[id]}; sender: {sender}'.format(body=body, sender=sender)
官方文档
http://docs.celeryproject.org/en/latest/userguide/signals.html#task-success
子任务与工作流:
可以把任务 通过签名的方法传给其他任务, 成为一个子任务.
from celery import signature
task = signature('task.add', args=(2,2), countdown=10)
task
task.add(2,2) # 通过签名生成任务
task.apply_async()
还可以通过如下方式生成子任务 :
from proj.task import add
task = add.subtask((2,2), countdown=10) # 快捷方式 add.s((2,2), countdown-10)
task.apply_async()
自任务实现片函数的方式非常有用, 这种方式可以让任务在传递过程中财传入参数.
partial = add.s(2)
partial.apply_async((4,))
子任务支持如下 5 种原语,实现工作流. 原语表示由若干指令组成的, 用于完成一定功能的过程.
1 chain : 调用连, 前面的执行结果, 作为参数传给后面的任务, 直到全部完成, 类似管道.
from celery import chain
res = chain(add.s(2,2), add.s(4), add.s(8))()
res.get()
管道式:
(add.s(2,2) | add.s(4) | add.s(8))().get()
2 group : 一次创建多个(一组)任务.
from celery import group
res = group(add.s(i,i) for i in range(10))()
res.get()
3 chord : 等待任务全部完成时添加一个回调任务.
res = chord((add.s(i,i) for i in range(10)), add.s(['a']))()
res.get() # 执行完前面的循环, 把结果拼成一个列表之后, 再对这个列表 添加 'a'.
[0,2,4,6,8,10,12,14,16,18,u'a']
4 map/starmap : 每个参数都作为任务的参数执行一遍, map 的参数只有一个, starmap 支持多个参数.
add.starmap(zip(range(10), range(10)))
相当于:
@app.task
def temp():
return [add(i,i) for i in range(10)]
5 chunks : 将任务分块.
res = add.chunks(zip(range(50), range(50)),10)()
res.get()
在生成任务的时候, 应该充分利用 group/chain/chunks 这些原语.
关闭不想要的功能 :
@app.task(ignore_result=True) # 关闭任务执行结果.
def func():
pass
CELERY_DISABLE_RATE_LIMITS=True # 关闭限速.
根据任务状态执行不同操作 :
# tasks.py
Task类有许多方法
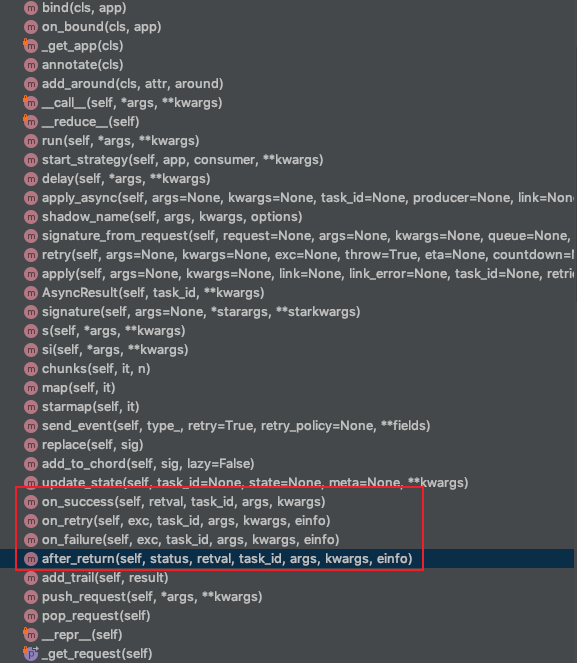
定义一个类,继承Task 对于任务执行的状态,有on_success,on_failure,afer_return, on_retry这几种,常用的就是成功后做的操作,失败后做的操作,相当于一个回调函数
class MyTask(Task):
def on_success(self, retval, task_id, args, kwargs):
#成功后的回调函数,入参为 异步任务的执行结果,任务id,任务函数的入参args,kwargs
print 'task done: {0}'.format(retval)
return super(MyTask, self).on_success(retval, task_id, args, kwargs)
def on_failure(self, exc, task_id, args, kwargs, einfo):
# 失败后的回调函数,一次为 错误的标题(NotFund这种的), 任务id , 任务函数的入参,错误的详细信息
print 'task fail, reason: {0}'.format(exc)
return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo)
可在回调函数中继续定义异步任务之后的操作,
还有一个after_return(status, retval, task_id, args, kwargs, einfo),是在在异步任务结果返回后,可以返回任务的执行状态,执行的结果/或者错误标题。任务id,参数,如果错误的详细信息
注意,当同时定义了after_return,on_success后,任务执行完只执行到after_return,on_success略过?不知道为啥,为了保险,还是 用on_success,on_failure这俩个。
# 正确函数, 执行 MyTask.on_success() :
@app.task(base=MyTask) # 调用的时候,在装饰器中定义base指定回调函数的类,在shell中调用即可触发
def add(x, y):
return x + y
# 错误函数, 执行 MyTask.on_failure() :
@app.task #普通函数装饰为 celery task
def add(x, y):
raise KeyError
return x + y
任务状态
启动方式
普通
$ celery -A proj worker -l info
使用 daemon 方式 multi :
$ celery multi start web -A proj -l info --pidfile=/path/to/celery_%n.pid --logfile=/path/to/celery_%n.log
# web 是对项目启动的标识,
# %n 是对节点的格式化用法.
%n : 只包含主机名
%h : 包含域名的主机
%d : 只包含域名
%i : Prefork 类型的进程索引,如果是主进程, 则为 0.
%I : 带分隔符的 Prefork 类型的进程索引. 假设主进程为 worker1, 那么进程池的第一个进程则为 worker1-1
常用 multi 相关命令:
$ celery multi show web # 查看 web 启动时的命令
$ celery multi names web # 获取 web 的节点名字
$ celery multi stop web # 停止 web 进程
$ celery multi restart web # 重启 web
$ celery multi kill web # 杀掉 web 进程
celery的任务回调
在每个celery任务执行完成之后,根据任务的状态 success failure等状态,有相应的回调函数,on_success on_failre等方法,在公共类里面已经有了这些方法,只需要根据需要定义的方法,即可,
在celery下的任务执行完成之后,成功失败都可以使用入参,输出/错误信息,
不过需要注意的一点是在on_success的时候, celery任务的状态并不是底下任务执行状态,而是一整套流程,
信号
定义了celery的信号,可以自己定义信号执行方法,也可以使用公有信号,例如监测某个表的对象新增,在新增的时候即可触发信号对应的方法,
问题:
2020-4-30 15:12:15,今天碰到的问题是: celery依赖的任务容错做足,状态 错误信息 都在返回结果中保存,保证函数执行绝对成功,在回调的时候都调用on_success方法,在执行on_success的时候保存任务id和相关的入参和结果中的信息,但是在入库的时候出现了记录要保存两次的问题,经过检查发现这个表对象的新增是有一个信号量在监测的,只要这个表对象增加,那么另外一个表就会新增同样的信息,但是在处理那张表数据的时候使用的是get方法,查询对象的时候返回了多条,所以报了错。因为这个表对象的新增还是在on_success流程中,所以on_success既定的流程走完之后,另一张表新增出错,随即出发了on_failure的函数,又去新增一条错误记录,所以每次执行的时候在同一张表中就出现了两条数据