filter().delete()
ret = xxx.objects.filetrer(id=1).delete()
ret返回的是一个元组
-
当filter不到对象,是一个空对象时,delete也可以执行
(0, {})
返回的ret 0 代表影响的数据行数,代表0行,{}空字典代表没有数据影响
(6, {'plan.Boy': 1, 'plan.Boy_girl': 5})
6代表删除了6条数据, 其中字典中显示的详情,boy表中删除了一条,关联的girl中删除了5条数据,一共六条
日期字段直接转换成时间戳
r.start_time.timestamp()
filter中可以添加多个过滤天条件,并非单条件
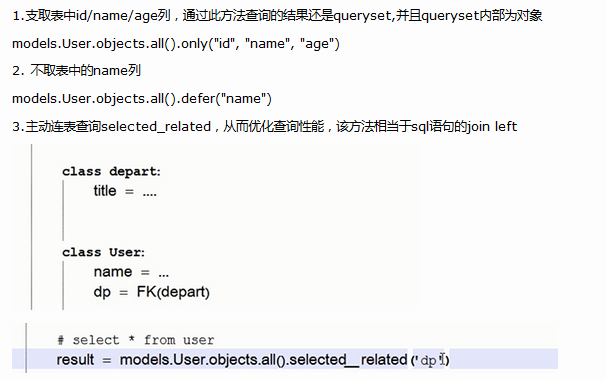
defer('id','name'):取出对象,字段除了id和name都有
only('id','name'):取的对象,只有id和name
查出的对象还可以继续用.来获取其他的属性值,
但是不要点了,因为取没有的列,会再次查询数据库
ret=models.Author.objects.only('nid')
for i in ret:
# 查询不在的字段,会再次查询数据库,造成数据库压力大
print(i.name)
聚合函数的使用
xx.objects.aggregate(Sum('result_0__sum')) #result_0__sum 字段名
可以获得该字段的聚合函数得到的值,对于字符型,数字型的类型返回的对象都是字典,但是字典对应的value是不同的
字典获取值的方法 .get('result_0__sum')
多对象创建
obj = []
obj.append(xxx(name=xxx,age=xxx,sex=xxx))
xxx.objects.bulk_create(obj)
将列表中的多个信息创建成一个个的对象。
字段查询谓词表

模型类说明




一个app关联另外一个app的模型
zabbix_group = models.ForeignKey('zabbix.Group', on_delete=models.CASCADE,null=True)
在modules文件中都不需要导入,直接使用app名.模型名称即可做外键关联
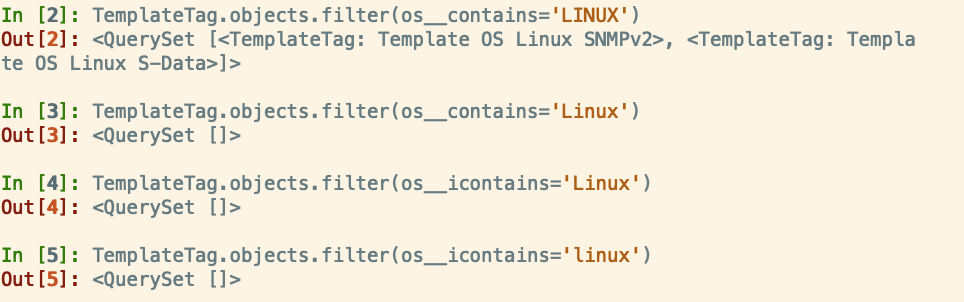
filter exclude结合使用
template = TemplateTag.objects.filter(os__icontains='LINUX'.exclude(name__icontains='SNMP')
查询出os名称包含LINUX,但是name不包含SNMP的对象,
contains icontains的作用 问题

应该是大小写的问题,可是我在使用的时候却查不出来,不知道为啥
xxx.objects.value_list('id','ip','type','rule','transferInfo')
生成的是一个queryset对象,list之后生成的是[(),(),()]
[(1013, '192.168.1.66', 'redis', None, 'logbeat'),
(1015, '192.168.1.66', 'kafka', 1, '51924'),
(1016, '192.168.1.66', 'icinga', None, ''),
(1120, '192.168.1.171', 'tomcat', None, 'logbeat'),
(1121, '192.168.1.66', 'nginx', 7, '35146'),
(1122, '192.168.1.66', 'mysql', 2, '57007')]
c = Collector.objects.values('id','ip','type','rule','transferInfo')
[{'id': 1013,
'ip': '192.168.1.66',
'type': 'redis',
'rule': None,
'transferInfo': 'logbeat'},
{'id': 1015,
'ip': '192.168.1.66',
'type': 'kafka',
'rule': 1,
'transferInfo': '51924'},
{'id': 1016,
'ip': '192.168.1.66',
'type': 'icinga',
'rule': None,
'transferInfo': ''},
{'id': 1120,
'ip': '192.168.1.171',
'type': 'tomcat',
'rule': None,
'transferInfo': 'logbeat'},
{'id': 1121,
'ip': '192.168.1.66',
'type': 'nginx',
'rule': 7,
'transferInfo': '35146'},
{'id': 1122,
'ip': '192.168.1.66',
'type': 'mysql',
'rule': 2,
'transferInfo': '57007'}]
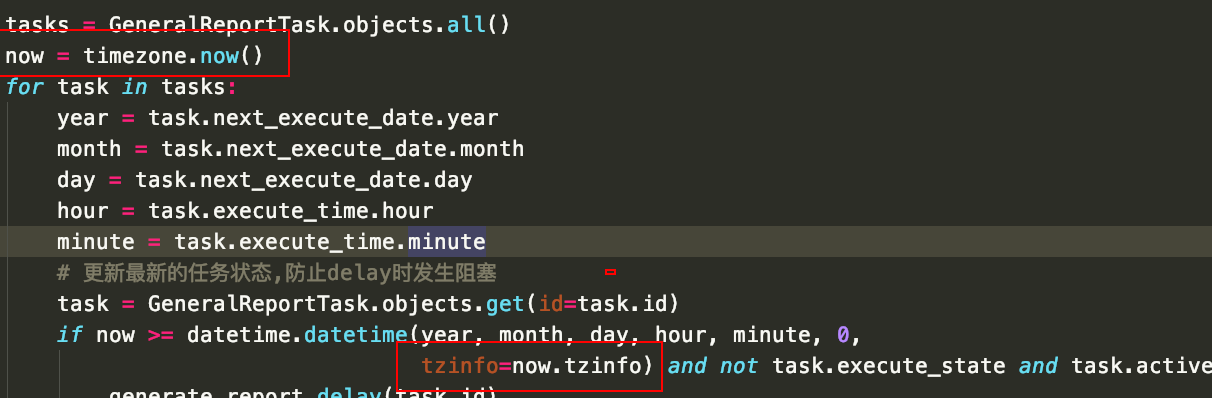
模型的自动添加时间
models.DateTimeField('下载时间', auto_now_add=True) 在新建对象的时候会自动添加,以后对象再有变化 时间是不会变的
auto_now 对象新建的时候也是会自动添加,但是这个对象在以后更新保存的时候,下载时间也会同步到当前时间,
模型在使用timezone的时候回使用数据库的时间进行保存,为utc时间,这样会导致一个问题,超前或者滞后8小时,
在展示timezone类型的时间对象时,可以在对象上使用astimezone()来转化成当前时间g.last_execute_time.astimezone()
datetime添加时区
使用anotate将数据模型对象的键名进行修改

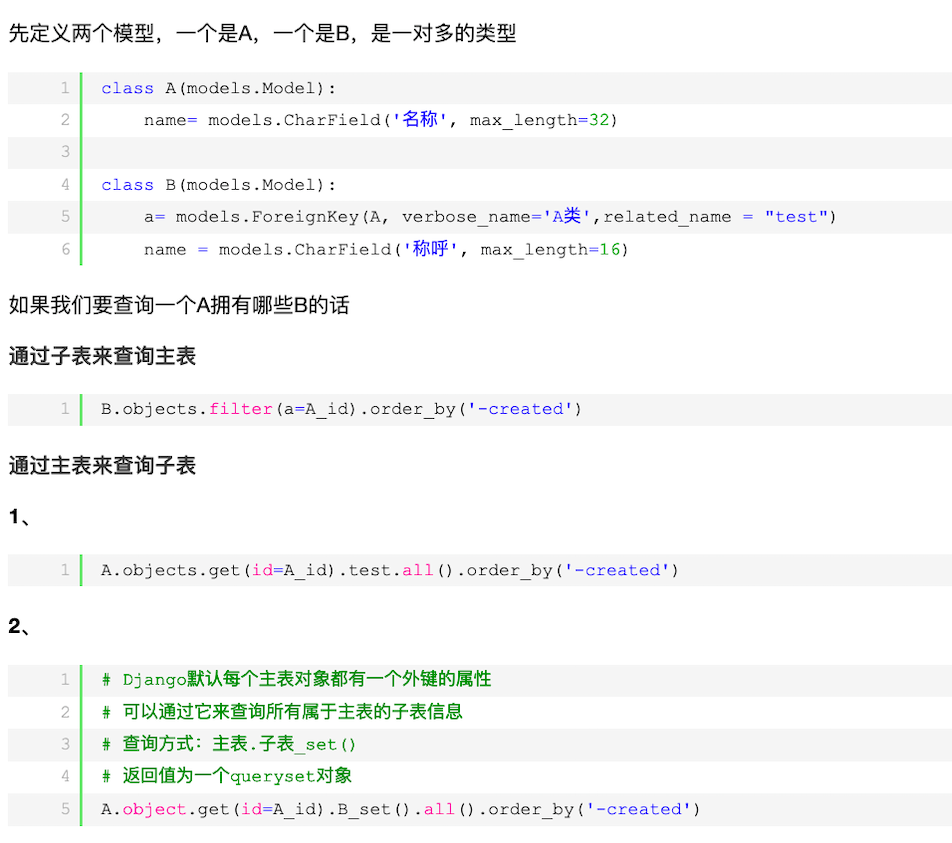
反向查找
使用序列化器的时候,如果要展示一个不再模板中的字段,可以在定义序列化的时候添加一个自定义字段,设定他的类型,然后再返回值字段 中指定__all__即可返回所有数据
django的信号,数据库级别的调用
from django.db.models.signals import *
post_save 通过监控一个表对象的新增,另一个表做操作
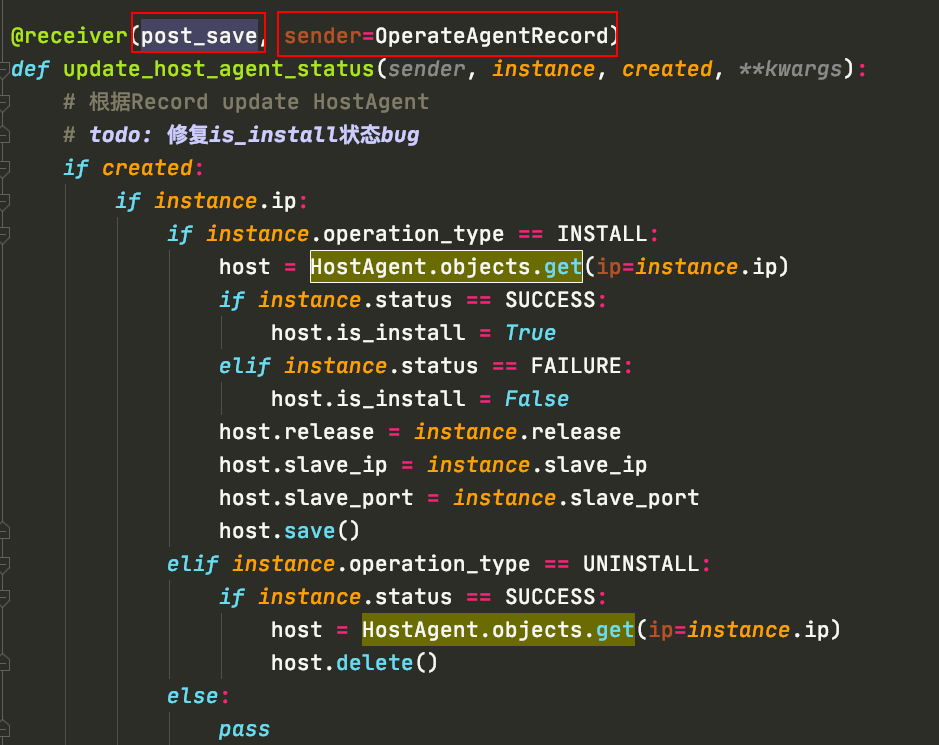
通过监听OperateAgentRecord 对象的新增信号 post_save,开启后续的操作,sender就是信号的来源,instance就是该对象的示例。到时候通过程序新建对象来触发,或者在django框架下如admin页面中添加对象,都是可以触发这个动作的
预缓存多表联查的数据 prefetch_related
AlertRule.objects.prefetch_related('application', 'agg_method', 'user', 'group').all()
在AlertRule对象的多对多对象查询中,使用prefetch_related可以预缓存出多对象,在AlertRule对象调用user等多关系属性的时候即可使用缓存中的数据,这样下来就减少了sql查询的数量,一次查询出所有的结果
values中指定跨表联查的字段
__ 实现跨表操作
TaFiles.objects.values('vc_agency__agencyno', 'vc_agency__agencyname',)
多对多表关系查询耗时的问题
当一个对象的字段涉及到了多对多关系,在all() 的时候,sql查询会吧所有的关联统统查询出来,耗时很多,在get的时候也是这样,直接用id查询一个对象也会查询出所有的关联项,建议使用annotate进行values查询转化,这样会省很多时间
GeneralReport有字段fileters config 为manytomany,如果后期还要用到缓存数据,可以使用prefetch_related进行缓存,如果不用可以不写,能节省一部分时间,
annotate解析器可以完成字段名称转换。进而获取关联项的名称等作用
filter_name=F('filters__name') 将多对多关联的filters对象的name属性转化为filter_name字段,在本次查询结果中展示
config_model_name = F('config__model__model_name') 将多对多关系的config对象中的外键关联对象model对象的model_name转化为config_model_name在结果中展示,注意多个__ __ 连接
GeneralReport.objects.prefetch_related('filters', 'config').annotate(
filter_name=F('filters__name'),
config_id=F('config__id'),
config_model_name = F('config__model__model_name')
).order_by('id').values()
统计
