 大数据(BigData):大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据(BigData):大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
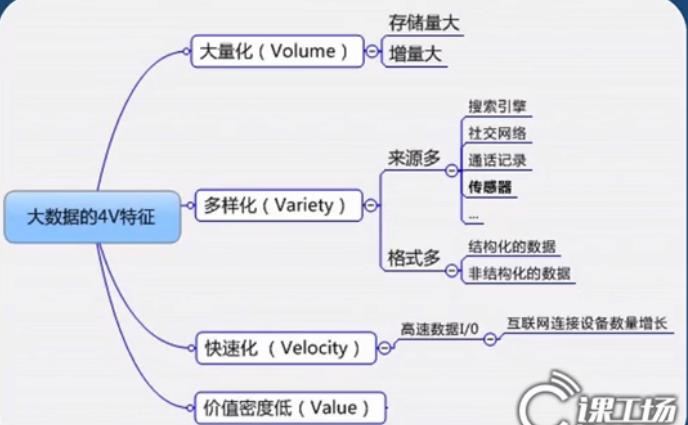
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
Hadoop是根据谷歌的论文开发出来的分布式系统基础架构。(图片取自课工场视频的截图)

BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。(数据库)
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。(存储系统)
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"(计算)
大数据带来的革命性变革
1)成本降低,能用PC机,就不会大型机或者高端存储设备。
2)软件容错、硬件故障视为常态,通过软件来保证高可靠。
3)简化分布式并行计算,无需控制节点同步和数据的交换。
Hadoop是什么:

Hadoop框架的三大部分:

Hadoop的生态圈:

Hive:提供了sql查询功能
R语言:一种统计性语言
Mahout:机器学习库(已停止更新) 现在大家都使用Spark。
pig:用于写脚本统计数据。
Oozie:工作流(通常在多个场景中相互配合使用)
zookeeper:分布式的协调性服务。
Flume:用于日志文件的收集。
Sqoop:描述数据的交换,关系型数据库和大数据系统进行交换。
Hbase:建立在HFDS上的面向列的数据库,用于快速读写大量数据,由zookeeper进行管理。
Hadoop的版本选择:


对于Apache的顶级项目,网站有一定的规则
hadoop: hadoop.apache.org
hive: hive.apache.org
spark: spark.apache.org
hbase
zookeeper
CDH下载地址:http://archive.cloudera.com/cdh5/cdh/5/
cdh5.7.0
CM: 通过web就能够快速的搭建集群
================================================================================================================================
写在后面的话:
这篇博客是我第一篇关于学习技术的博客,记录的是我看课工场视频学习的记录,截图取自视频,一些定义取自百度,可能写的不好,并且也没什么自己的理解。我个人写博客的原因是朋友的建议,因为
在培训班培训了6个多月只会写SSM框架,现在找工作很难,面试官的要求以我现在的水平根本达不到,现在都要求会spingboot和springcloud,会处理抢购网站的高并发请求,
我觉得我的培训经历很失败,朋友建议我自己照着API文档撸一遍代码,并且写技术博客来记录自己的学习,我自己希望能通过自己的学习达到用人单位的要求,找到一份合适的工作,
在博客里面如果有大佬觉得写的有问题的话请指出来,我来修改;如果有像我一样想要转行的小白,希望我们能共勉,一起努力学习,早日找到满意的工作。最后希望看到这篇博客的读者如果
发现有错误的地方能指出来,我在此表示感谢。(培训班不要报某鸟,我觉得我进天坑了~。~)