前言
在上一篇文章中,我主要是讲解了DAG阶段的处理,spark是如何将一个job根据宽窄依赖划分出多个stage的,在最后一步中是将生成的TaskSet提交给了TaskSchedulerInmpl的。
此次我们从taskScheduler.submitTasks开始讲,深入理解TaskScheduler的运行过程,这个地方是如何将taskSetManager和pool联系在一起的。
taskSetManager类继承了Schedulable,这个继承类是pool之间的桥梁,也是调度算法的桥梁。pool也继承了Schedulable,请带着疑问看源码吧。
taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
taskScheduler.submitTasks()
override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasks logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks") this.synchronized { //创建TaskSetManager val manager = createTaskSetManager(taskSet, maxTaskFailures) val stage = taskSet.stageId val stageTaskSets = taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager]) stageTaskSets(taskSet.stageAttemptId) = manager val conflictingTaskSet = stageTaskSets.exists { case (_, ts) => ts.taskSet != taskSet && !ts.isZombie } if (conflictingTaskSet) { throw new IllegalStateException(s"more than one active taskSet for stage $stage:" + s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}") }
//将manager信息加入到调度器,这个地方是根据前面的调度算法,重写了addTaskSetManager方法。 schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) if (!isLocal && !hasReceivedTask) { starvationTimer.scheduleAtFixedRate(new TimerTask() { override def run() { if (!hasLaunchedTask) { logWarning("Initial job has not accepted any resources; " + "check your cluster UI to ensure that workers are registered " + "and have sufficient resources") } else { this.cancel() } } }, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS) } hasReceivedTask = true } backend.reviveOffers() }
CoarseGrainedSchedulerBackend.reviveOffers()

看到这是不是有些眼熟?如果你是先看的如何启动driver,如何启动app的,如何启动executor的,你可能就瞬间想起来了,因为在driver的时候就用了这个,只是他自己给我自己发送了一个空Object,进行验证而已。
回忆一下:CoarseGrainedSchedulerBackend的start会生成driverEndpoint,它是一个rpc的终端,一个RpcEndpoint接口,它由ThreadSafeRpcEndpoint接口实现,而ThreadSafeRpcEndpoint,CoarseGrainedSchedulerBackend的内部类DriverEndpoint实现。CoarseGrainedSchedulerBackend的reviveOffers就是发送给这个rpc的终端ReviveOffers信号,ReviveOffers就是一个case class。
CoarseGrainedSchedulerBackend.revive()
继续回忆一下:DriverEndpoint有两种发送信息的函数。一个是send,发送信息后不需要对方回复。一个是ask,发送信息后需要对方回复。 对应着,也有两种接收信息的函数。一个是receive,接收后不回复对方:
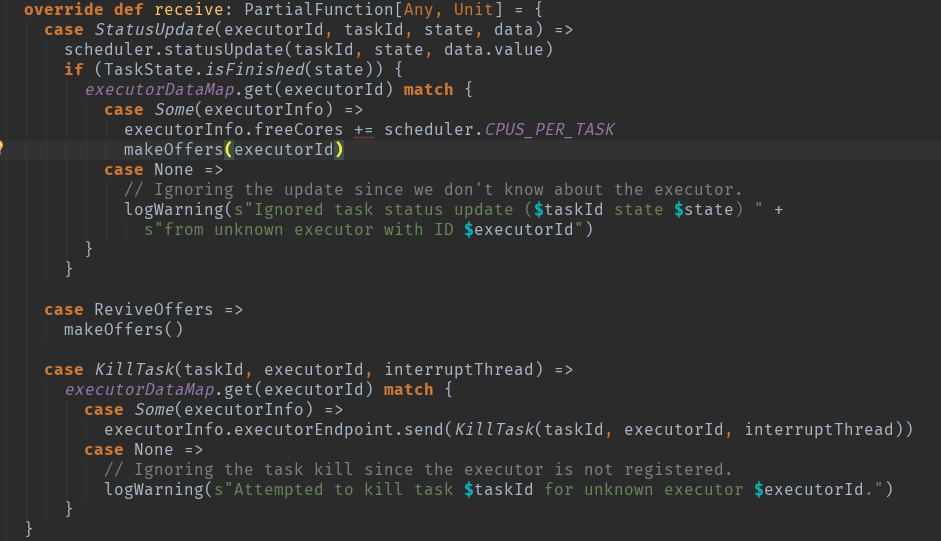
看源码可以看到,调用了makeOffers()方法
CoarseGrainedSchedulerBackend.makeOffers()
private def makeOffers() { // Filter out executors under killing //过滤掉要被移除的和缺失的executor val activeExecutors = executorDataMap.filterKeys(executorIsAlive) //根据activeExecutors生成workOffers, //即executor所能提供的资源信息 val workOffers = activeExecutors.map { case (id, executorData) => new WorkerOffer(id, executorData.executorHost, executorData.freeCores) }.toSeq //scheduler.resourceOffers分配资源, //并launchTasks发送任务 launchTasks(scheduler.resourceOffers(workOffers)) }
接下来让我们看看是如何给task分派资源的resourceOffers()方法,既然是给task分配资源那可定是TaskSchedulerImpl的事情了。
TaskSchedulerImpl.resourceOffers()
我们先梳理一下思路:
TaskSchedulerImpl.resourceOffers()整体任务资源分配===>resourceOfferSingleTaskSet()当个task任务分配===>TaskSetManager.resourceOffer()分配task
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized { // Mark each slave as alive and remember its hostname // Also track if new executor is added var newExecAvail = false for (o <- offers) { //循环可用的每个workoffer的资源 executorIdToHost(o.executorId) = o.host //主机和executor进行绑定 executorIdToTaskCount.getOrElseUpdate(o.executorId, 0) //在每个executor上执行的task数量 if (!executorsByHost.contains(o.host)) { executorsByHost(o.host) = new HashSet[String]() executorAdded(o.executorId, o.host) newExecAvail = true } //为每个主机添加或者更新任务跟踪者 for (rack <- getRackForHost(o.host)) { hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host } } // Randomly shuffle offers to avoid always placing tasks on the same set of workers. // 为了避免将Task集中分配到某些机器,随机的打散它们 val shuffledOffers = Random.shuffle(offers) // Build a list of tasks to assign to each worker. //构建分配给每个worker的任务列表 val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores)) //记录各个worker的available Cpus val availableCpus = shuffledOffers.map(o => o.cores).toArray //获取按照调度策略排序好的TaskSetManager val sortedTaskSets = rootPool.getSortedTaskSetQueue for (taskSet <- sortedTaskSets) { logDebug("parentName: %s, name: %s, runningTasks: %s".format( taskSet.parent.name, taskSet.name, taskSet.runningTasks)) //如果有新的executor加入 //则需要从新计算TaskSetManager的就近原则 if (newExecAvail) { taskSet.executorAdded() } } // Take each TaskSet in our scheduling order, and then offer it each node in increasing order // of locality levels so that it gets a chance to launch local tasks on all of them. // NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY var launchedTask = false // 得到调度序列中的每个TaskSet, // 然后按节点的locality级别增序分配资源 // Locality优先序列为: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) { do { //resourceOfferSingleTaskSet为单个TaskSet分配资源, //若该LocalityLevel的节点下不能再为之分配资源了, //则返回false launchedTask = resourceOfferSingleTaskSet( taskSet, maxLocality, shuffledOffers, availableCpus, tasks) } while (launchedTask) } if (tasks.size > 0) { hasLaunchedTask = true } return tasks }
TaskSchedulerImpl.resourceOffersSingleTaskSet()
单个TaskSet分配资源:
private def resourceOfferSingleTaskSet( taskSet: TaskSetManager, maxLocality: TaskLocality, shuffledOffers: Seq[WorkerOffer], availableCpus: Array[Int], tasks: Seq[ArrayBuffer[TaskDescription]]) : Boolean = { var launchedTask = false for (i <- 0 until shuffledOffers.size) { val execId = shuffledOffers(i).executorId val host = shuffledOffers(i).host if (availableCpus(i) >= CPUS_PER_TASK) { try { for (task <- taskSet.resourceOffer(execId, host, maxLocality)) { tasks(i) += task val tid = task.taskId taskIdToTaskSetManager(tid) = taskSet taskIdToExecutorId(tid) = execId executorIdToTaskCount(execId) += 1 executorsByHost(host) += execId availableCpus(i) -= CPUS_PER_TASK assert(availableCpus(i) >= 0) launchedTask = true } } catch { case e: TaskNotSerializableException => logError(s"Resource offer failed, task set ${taskSet.name} was not serializable") // Do not offer resources for this task, but don't throw an error to allow other // task sets to be submitted. return launchedTask } } } return launchedTask }
TaskSetManager.resourceOffer()
根据TaskScheduler所提供的单个Resource资源包括host,executor和locality的要求返回一个合适的Task,TaskSetManager内部会根据上一个任务的成功提交的时间,自动调整自身的Locality匹配策略,如果上一次成功提交任务的时间间隔很长,则降低对Locality的要求(例如从最差要求Process Local降低为最差要求Node Local),反之则提高对Locality的要求。这一动态调整Locality的策略为了提高任务在最佳Locality的情况下得到运行的机会,因为Resource资源是在短期内分批提供给TaskSetManager的,动态调整Locality门槛有助于改善整体的Locality分布情况。


def resourceOffer( execId: String, host: String, maxLocality: TaskLocality.TaskLocality) : Option[TaskDescription] = { if (!isZombie) { val curTime = clock.getTimeMillis() var allowedLocality = maxLocality if (maxLocality != TaskLocality.NO_PREF) { allowedLocality = getAllowedLocalityLevel(curTime) if (allowedLocality > maxLocality) { // We're not allowed to search for farther-away tasks allowedLocality = maxLocality } } dequeueTask(execId, host, allowedLocality) match { case Some((index, taskLocality, speculative)) => { // Found a task; do some bookkeeping and return a task description val task = tasks(index) val taskId = sched.newTaskId() // Do various bookkeeping copiesRunning(index) += 1 val attemptNum = taskAttempts(index).size val info = new TaskInfo(taskId, index, attemptNum, curTime, execId, host, taskLocality, speculative) taskInfos(taskId) = info taskAttempts(index) = info :: taskAttempts(index) // Update our locality level for delay scheduling // NO_PREF will not affect the variables related to delay scheduling if (maxLocality != TaskLocality.NO_PREF) { currentLocalityIndex = getLocalityIndex(taskLocality) lastLaunchTime = curTime } // Serialize and return the task val startTime = clock.getTimeMillis() val serializedTask: ByteBuffer = try { Task.serializeWithDependencies(task, sched.sc.addedFiles, sched.sc.addedJars, ser) } catch { // If the task cannot be serialized, then there's no point to re-attempt the task, // as it will always fail. So just abort the whole task-set. case NonFatal(e) => val msg = s"Failed to serialize task $taskId, not attempting to retry it." logError(msg, e) abort(s"$msg Exception during serialization: $e") throw new TaskNotSerializableException(e) } if (serializedTask.limit > TaskSetManager.TASK_SIZE_TO_WARN_KB * 1024 && !emittedTaskSizeWarning) { emittedTaskSizeWarning = true logWarning(s"Stage ${task.stageId} contains a task of very large size " + s"(${serializedTask.limit / 1024} KB). The maximum recommended task size is " + s"${TaskSetManager.TASK_SIZE_TO_WARN_KB} KB.") } addRunningTask(taskId) // We used to log the time it takes to serialize the task, but task size is already // a good proxy to task serialization time. // val timeTaken = clock.getTime() - startTime val taskName = s"task ${info.id} in stage ${taskSet.id}" logInfo(s"Starting $taskName (TID $taskId, $host, partition ${task.partitionId}," + s"$taskLocality, ${serializedTask.limit} bytes)") sched.dagScheduler.taskStarted(task, info) return Some(new TaskDescription(taskId = taskId, attemptNumber = attemptNum, execId, taskName, index, serializedTask)) } case _ => } } None }
CoarseGrainedSchedulerBackend.DriverEndpoint.launchTasks
launchTasks(scheduler.resourceOffers(workOffers))
这时我们在继续看一下lanchTasks这个
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) { for (task <- tasks.flatten) { val serializedTask = ser.serialize(task) //若序列话Task大小达到Rpc限制,则停止。 if (serializedTask.limit >= akkaFrameSize - AkkaUtils.reservedSizeBytes) { scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr => try { var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " + "spark.akka.frameSize (%d bytes) - reserved (%d bytes). Consider increasing " + "spark.akka.frameSize or using broadcast variables for large values." msg = msg.format(task.taskId, task.index, serializedTask.limit, akkaFrameSize, AkkaUtils.reservedSizeBytes) taskSetMgr.abort(msg) } catch { case e: Exception => logError("Exception in error callback", e) } } } else { val executorData = executorDataMap(task.executorId) // 减少改task所对应的executor信息的core数量 executorData.freeCores -= scheduler.CPUS_PER_TASK //向executorEndpoint 发送LaunchTask 信号 executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))) } } }
executorEndpoint接收到LaunchTask信号(包含SerializableBuffer(serializedTask) )后,会开始执行任务。这样task就发送到了对应的executor上了。至此,TaskScheduler在发送任务给executor前的工作就全部完成了。