周一,晴,记录生活分享点滴
参考博客:https://www.cnblogs.com/resn/p/5800922.html
推荐阅读:https://www.runoob.com/linux/linux-tutorial.html
crontab
crontab 计划任务输入格式
crontab -u-u user:用来设定某个用户的crontab服务; -e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。 -l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。 -r:从/var/spool/cron目录中删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。 -i:在删除用户的crontab文件时给确认提示
计划任务显示样式
* * * * * command to be executed - - - - - - | | | | | | | | | | | --- 预执行的命令 | | | | ----- 表示星期0~7(其中星期天可以用0或7表示) | | | ------- 表示月份1~12 | | --------- 表示日期1~31 | ----------- 表示小时1~23(0表示0点) ------------- 表示分钟1~59 每分钟用*或者 */1表示
补充:
计划任务有时系统没有默认安装,需要 apt-cache search crontab 查看是否安装
在写计划任务时,不要超过64个字节,因为在某些Linux中无法读取,尽量简短,如果无法简短,将其写到一个文件里面
tar
tar压缩文件方式
tar zcvf a.tar.gz ./*.py aa # 压缩:tar+参数+f+压缩后的文件名+指定源文件(需要进行压缩的文件名) tar xf a.tar.gz # 解压 -c :创建一个压缩文件(create 的意思); -x :解压一个压缩文件 # 特别注意 c/x 同时仅能存在一个,因为不可能同时压缩与解压缩。 -t :查看 tarfile 里面的文件内容 -z :指定压缩方式 gzip -j :指定压缩方式 bzip2 ,压缩率更高 -v :显示压缩过程中的文件,不建议用在背景执行过程 -f :指定文件名,注意:在 -f 之后必须接文件名,放在所有参数的后面 -p :保证原文件的原来属性(属性不会依据使用者而变) -P :在压缩时使用绝对路径 -N :比后面接的日期(yyyy/mm/dd)还要新的才会被打包进新建的文件中
tar具体使用方法
# 将当前目录下所有.txt文件打包并压缩归档到文件this.tar.gz tar czvf this.tar.gz ./*.txt # 将当前目录下的this.tar.gz中的文件解压到当前目录 tar xzvf this.tar.gz ./ # 将整个 /etc 目录下的文件全部打包成为 /tmp/etc.tar tar -cvf /tmp/etc.tar /etc # 仅打包,不压缩! tar -zcvf /tmp/etc.tar.gz /etc # 打包后,以 gzip 压缩 tar -jcvf /tmp/etc.tar.bz2 /etc # 打包后,以 bzip2 压缩 # 解压文件 tar -xf a.tar.gz # tar -xf a.tar.gz -C /tmp # 指定解包路径
补充:
相对路径(cd ../):根据当前的位置决定;
绝对路径(cd /):不管什么时候位置都不会变化,从根(/)出发
grep
格式、参数
格式: grep -o better a.txt # grep+参数+关键词+文件名 参数: -c # 计算符合样式的列数 -l # 列出文件内容符合指定的样式的文件名称。 -v # 反着来,显示不包含匹配文本的所有行 -i # 忽略大小写 -o # 只显示匹配到的关键字 -n # 显示行号 -E # 使用正则表达式
正则表达式(部分)
表示方式:grep -E 与 egrep 是等价的
^ :匹配开头
$ :匹配结尾
[] :范围匹配
[a-z] :所有小写字母
[A-Z] :所有大写字母
[0-9] :所有数字
^ : 表示取反 eg :[^0-9] :所有非数字
. :表示任意一个字符(出现一次).* :表示任意一个字符出现多次,也就是所有的内容 eg:grep -E "." z.txt
* :表示 * 前面的内容出现0次或多次 eg :[a-z]* 表示0个或多个小写字母,[0-9][a-z]* 表示0个或多个小写字母,与 [0-9] 没有关系
+ :表示 + 前面的内容出现1次或多次 eg :[a-z]+ 表示至少出现1次小写字母
? :表示 ? 前面的内容出现0次或1次 eg :[a-z]? 表示出现0次或1次小写字母
cat a.txt |grep hat$ # 匹配以hat结尾的行 cat a.txt |grep ^hat # 匹配以hat开头的行 cat a.txt | grep -E "[0-9]*" # 匹配有0到多个数字的行 cat a.txt | grep -E "[0-9]+" # 匹配有至少有1个数字的行 cat a.txt | grep -E "[0-9]?" # 匹配有0到1个数字的行
补充:表示单独的符号,例如 " . " 点之类的,需要在前面添加反斜杠 " "
sed
sed : 流编辑器,一次处理一行内容
格式: sed [-nefr] [动作] [文件] sed+参数+动作+文件 选项与参数: -n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来 -e :直接在命令列模式上进行 sed 的动作编辑 -f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作 -r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法) -i :直接修改读取的文件内容,而不是输出到终端。 动作说明: [n1[,n2]] 动作: n1, n2 :不一定存在,一般代表选择进行动作的行数,比如,如果我的动作是需要在 10 到 20 行之间进行的,则10,20[动作行为] 动作: #a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行) #c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! #d :删除,因为是删除啊,所以 d 后面通常不接任何东西 sed "3d" file # 删除第三行 sed "1,3d" # 删除前三行 sed "1d;3d;5d" # 删除1、3、5行 sed "/^$/d" #删除空行 sed "/abc/d" #删除所有含有abc的行 sed "/abc/,/def/d" #删除abc 和 def 之间的行,包括其自身 sed "1,/def/d" #删除第一行到 def 之间的行,包括其自身 sed "/abc/,+3d " # 删除含有abc的行之后,在删除3行 sed "/abc/,~3d" #从含有abc的行开始,共删除3行 sed "1~2d" # 从第1行开始,每2行删除一行, 删除奇数行 sed "2~2d" # 从第2行开始,每2行删除一行, 删除奇数行 sed "$d" # 删除最后一行 sed "/dd|cc/d" # 删除有dd或者cc的行 #i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);与 a 相反 #p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行 sed -n "3p" file # 显示第三行 sed -n "1,3p" # 显示前三行 sed -n "2,+3p" # 显示第二行,及后面的三行 sed -n "$p" # 显示最后一行 sed -n "1p;3p;5p" # 只显示文件1、3、5行 sed -n "$=" # 显示文件行数 #s :替换,可以直接进行取代的工作。通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g g表示替换所有行 's/old/new/g' sed "s/(all)/bb/" sed -r "s/(all)/bb/"
补充:
动作 d 、s 用的较多
在引号(" ")中运用特殊字符,需要加反斜杠()使特殊字符有意义,而不是以文本的形式展现,例如 $ 前需要加
awk
awk : 一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。
简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
# 命令行调用方式 awk [-F field-separator] 'commands' input-file(s) # commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 # 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 # awk工作流程: # 读入有' '换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。 # 默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。 cat /etc/passwd |awk -F ':' '{print $1}' # $1指第一列,$0指所有行 cat /etc/passwd |awk -F ':' '{print $1" "$7}' awk 常用内置变量 ARGC 命令行参数个数 ARGV 命令行参数排列, ARGV[0] ARGV[1] ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 # 统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容: awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd # 使用printf替代print,可以让代码更加简洁,易读 awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s ",FILENAME,NR,NF,$0)}' /etc/passwd
vi/vim
vi/vim : 强大的编辑器
vim是vi的升级版,操作相同
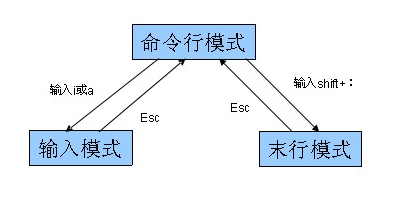
常用:
进入时默认是命令模式
: q ! 表示强制退出,: w 保存,: wq保存并退出,! 表示强制
u 指撤销 Ctrl+r 指重做
d:删至行尾
r:替换当前字符
x(小写):删除当前位置的一个字符
set nu (临时)显示行号

命令
进入vi的命令
vi filename :打开或新建文件,并将光标置于第一行首
vi +n filename :打开文件,并将光标置于第n行首
vi + filename :打开文件,并将光标置于最后一行首
vi +/pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处
vi -r filename :在上次正用vi编辑时发生系统崩溃,恢复filename
vi filename....filename :打开多个文件,依次进行编辑
移动光标类命令
h :光标左移一个字符
l :光标右移一个字符
space:光标右移一个字符
Backspace:光标左移一个字符
k或Ctrl+p:光标上移一行
j或Ctrl+n :光标下移一行
Enter :光标下移一行
w或W :光标右移一个字至字首
b或B :光标左移一个字至字首
e或E :光标右移一个字至字尾
) :光标移至句尾
( :光标移至句首
}:光标移至段落开头
{:光标移至段落结尾
nG:光标移至第n行首
n+:光标下移n行
n-:光标上移n行
n:光标移至第n行尾
H:光标移至屏幕顶行
M:光标移至屏幕中间行
L:光标移至屏幕最后行
0:(注意是数字零)光标移至当前行首
屏幕翻滚类命令
Ctrl+u:向文件首翻半屏
Ctrl+d:向文件尾翻半屏
Ctrl+f:向文件尾翻一屏
Ctrl+b;向文件首翻一屏
nz:将第n行滚至屏幕顶部,不指定n时将当前行滚至屏幕顶部
插入文本类命令
i :在光标前
I :在当前行首
a:光标后
A:在当前行尾
o:在当前行之下新开一行
O:在当前行之上新开一行
r:替换当前字符
R:替换当前字符及其后的字符,直至按ESC键
s:从当前光标位置处开始,以输入的文本替代指定数目的字符
S:删除指定数目的行,并以所输入文本代替之
ncw或nCW:修改指定数目的字
nCC:修改指定数目的行
删除命令
ndw或ndW:删除光标处开始及其后的n-1个字
do:删至行首
d:删至行尾
ndd:删除当前行及其后n−1行
Ctrl+u:删除输入方式下所输入的文本搜索及替换命令
x(小写):删除当前位置的一个字符
X(大写):删除当期位置之前的一个字符
最后行方式命令
:n1,n2 co n3:将n1行到n2行之间的内容拷贝到第n3行下
:n1,n2 m n3:将n1行到n2行之间的内容移至到第n3行下
:n1,n2 d :将n1行到n2行之间的内容删除
:w :保存当前文件
:e filename:打开文件filename进行编辑
:x:保存当前文件并退出
:q:退出vi
:q!:不保存文件并退出vi
:!command:执行shell命令command
:n1,n2 w!command:将文件中n1行至n2行的内容作为command的输入并执行之,若不指定n1,n2,则表示将整个文件内容作为command的输入
:r!command:将命令command的输出结果放到当前行
寄存器操作
"?nyy:将当前行及其下n行的内容保存到寄存器?中,其中?为一个字母,n为一个数字
"?nyw:将当前行及其下n个字保存到寄存器?中,其中?为一个字母,n为一个数字
"?nyl:将当前行及其下n个字符保存到寄存器?中,其中?为一个字母,n为一个数字
"?p:取出寄存器?中的内容并将其放到光标位置处。这里?可以是一个字母,也可以是一个数字
ndd:将当前行及其下共n行文本删除,并将所删内容放到1号删除寄存器中
文本
一、插入文本
i 在当前字符前插入文本
I 在行首插入文本
a 在当前字符后添加文本
A 在行末添加文本
o 在当前行后面插入一空行
O 在当前行前面插入一空行
R 以改写方式输入文本
二、移动光标
j或下箭头 向下移动一行
k或上箭头 向上移动一行
h或左箭头 左移一个字符
l或右箭头 右移一个字符
w 右移一个词
W 右移一个以空格分隔的词
b 左移一个词
B 左移一个以空格分隔的词
0 移到行首
Ctrl-F 向前翻页
Ctrl-B 向后翻页
nG 到第n行
G 到最后一行
三、替换文本
$ 到行尾
( 到句子的开头
) 到句子的末尾
{ 到段落的开头
} 到段落的末尾
四、删除文本
r 替换一个字符
c 修改文本直到按下Esc健
cw 修改下一个词
cnw 修改接下来的n个词
五、文本编辑
yy 将一行文本移到缺省缓冲区中
yn 将下一个词移到缺省缓冲区中
ynw 将后面的n个词移到缺省缓冲区中
p (小写) 如果缺省缓冲区中包含一行文本,则在当前行后面插入一个空行并将缺省缓冲区中的内容粘贴到这一行中;如果缺省缓冲区中包含多个词,把这些词粘贴到光标的右边
P (大写) 如果缺省缓冲区中包含一行文本,则正当前行前面插入一个空行并将缺省缓冲区中的内容粘贴到这一行中;如果缺省缓冲区中包含多个词,把这些词粘贴到光标的左边
六、保存退出
zz 保存并退出
:w filename 写入文件
:W 写入文件
:x 保存(如果当前文件修改过)并退出
:q! 不保存文件,直接退出
:q 退出vi
操作
vi编辑器的启动与退出
$ vi 直接进入编辑环境
$ vi myfile 进入编辑环境并打开(新建)文件
:q! 退出vi编辑环境,输入末行命令放弃对文件的修改,并退出编辑器
:w 保存文件,保存对vi编辑器中已打开文件的修改
:w myfile 另存为文件,将vi编辑器中的内容另存为指定文件名
退出vi编辑器的多种方法
:q 未修改退出,没有对vi编辑器中打开的文件进行修改,或已对修改进行了保存,直接退出vi编辑器
:wq 对vi编辑器中的文件进行保存并退出vi编辑器
:q! 不保存退出,放弃对文件内容的修改,并退出vi编辑器
光标的移动和翻页操作
h 向左移动光标
l 向右移动光标
k 向上移动光标
j 向下移动光标
翻页Ctrl + f向前翻整页
Ctrl + b向后翻整页
Ctrl + u向前翻半页
Ctrl + d向后翻半页
行内快速跳转
^ 将光标快速跳转到本行的行首字符
$ 将光标快速跳转到本行的行尾字符
w 将光标快速跳转到当前光标所在位置的后一个单词的首字母
b 将光标快速跳转到当前光标所在位置的前一个单词的首字母
e 将光标快速跳转到当前光标所在位置的后一个单词的尾字母
文件内行间快速跳转
命令功能
:set nu 在编辑器中显示行号
:set nonu 取消编辑器中的行号显示
1G 跳转到文件的首行
G 跳转到文件的末尾行
#G 跳转到文件中的第#行
进入输入模式
i 在当前光标处进入插入状态
a 在当前光标后进入插入状态
A 将光标移动到当前行的行末,并进入插入状态
o 在当前行的下面插入新行,光标移动到新行的行首,进入插入状态
O 在当前行的上面插入新行,光标移动到新行的行首,进入插入状态
cw 删除当前光标到所在单词尾部的字符,并进入插入状态
c$ 删除当前光标到行尾的字符,并进入插入状态
c^ 命令删除当前光标之前(不包括光标上的字符)到行首的字符,并进入插入状态
输入模式的编辑键操作
方向键进行上下左右方向的光标移动
Home 快速定位光标到行首
End 快速定位光标到行尾
PageUp 进行文本的向上翻页
PageDown 进行文本的向下翻页
Backspace 删除光标左侧的字符
Del 删除光标位置的字符
删除操作
x 删除光标处的单个字符
dd 删除光标所在行
dw 删除当前字符到单词尾(包括空格)的所有字符
de 删除当前字符到单词尾(不包括单词尾部的空格)的所有字符
d$ 删除当前字符到行尾的所有字符
d^ 删除当前字符到行首的所有字符
J 删除光标所在行行尾的换行符,相当于合并当前行和下一行的内容
替换操作
:s/old/new 将当前行中查找到的第一个字符“old” 串替换为“new”
:s/old/new/g 将当前行中查找到的所有字符串“old” 替换为“new”
:#,#s/old/new/g 在行号“#,#”范围内替换所有的字符串“old”为“new”
:%s/old/new/g 在整个文件范围内替换所有的字符串“old”为“new”
:s/old/new/c 在替换命令末尾加入c命令,将对每个替换动作提示用户进行确认
撤消操作
u 取消最近一次的操作,并恢复操作结果,可以多次使用u命令恢复已进行的多步操作
U 取消对当前行进行的所有操作
Ctrl + r 对使用u命令撤销的操作进行恢复
复制与粘贴操作
yy 复制当前行整行的内容到vi缓冲区
yw 复制当前光标到单词尾字符的内容到vi缓冲区
y$ 复制当前光标到行尾的内容到vi缓冲区
y^ 复制当前光标到行首的内容到vi缓冲区
p 读取vi缓冲区中的内容,并粘贴到光标当前的位置(不覆盖文件已有的内容)
字符串查找操作
/word从上而下在文件中查找字符串“word”
?word 从下而上在文件中查找字符串“word”
n定位下一个匹配的被查找字符串
N定位上一个匹配的被查找字符串