1.报错背景
服务器:Linux集群 3台,32GB内存;
Kafka创建了大约140个Topic,和与Topic数目相同的Consumer,设置分区数量不祥;
每个Consumer都在GroupId,没有单独的standalone consumer;
项目在运行过程中突然出现了大量分区提交失败的现象。
2.报错现象
报错截图

报错日志(保密原因,groupId做过处理)
2020-04-28 at 16:59:36 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-1158, groupId=144rrr4001020008SYS18] Offset commit failed on partition 001020008SYS18-3 at offset 594: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-1330, groupId=144rrr4001020001SYS01] Offset commit failed on partition 001020001SYS01-1 at offset 12405: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-93, groupId=144rrr4001020012SYS02] Offset commit failed on partition 001020012SYS02-0 at offset 957: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-872, groupId=144rrr4001020010SYS20] Offset commit failed on partition 001020010SYS20-3 at offset 982: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-16, groupId=144rrr4001020012SYS03] Offset commit failed on partition 001020012SYS03-0 at offset 1045: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-820, groupId=144rrr4001020010SYS20] Offset commit failed on partition 001020010SYS20-3 at offset 982: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-912, groupId=144rrr4001020003SYS01] Offset commit failed on partition 001020003SYS01-1 at offset 12387: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-719, groupId=144rrr4001020002SYS01] Offset commit failed on partition 001020002SYS01-3 at offset 5274: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-250, groupId=144rrr4001020006SYS18] Offset commit failed on partition 001020006SYS18-2 at offset 312: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-66, groupId=144rrr4001020012SYS02] Offset commit failed on partition 001020012SYS02-0 at offset 957: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-277, groupId=144rrr4001020004SYS03] Offset commit failed on partition 001020004SYS03-3 at offset 390: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-880, groupId=144rrr4001020010SYS20] Offset commit failed on partition 001020010SYS20-3 at offset 982: The coordinator is not aware of this member. 2020-04-28 at 16:59:37 CST traceId:[] ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler 867 handle - [Consumer clientId=consumer-488, groupId=144rrr4001020009SYS01] Offset commit failed on partition 001020009SYS01-2 at offset 7875: The coordinator is not aware of this member.
3.报错原因
依据网上资料进行大胆猜测:
第一步
分析触发报错的直接原因:
Offset commit failed on partition 001020004SYS03-3 at offset 390: The coordinator is not aware of this member.
翻译过来:Offset提交失败,Kafka的group协调器不认识该成员。
第二步
分析造成Kafka的group协调器不认识该成员的原因:
参考资料:https://www.cnblogs.com/yoke/p/11405397.html
(1)Consumer中出现单独的standalone consume,而且standalone consume的名字和某个GroupId名字相同,这种现象就会触发报错,具体原因我未深究,因为本项目没有standalone consume存在;
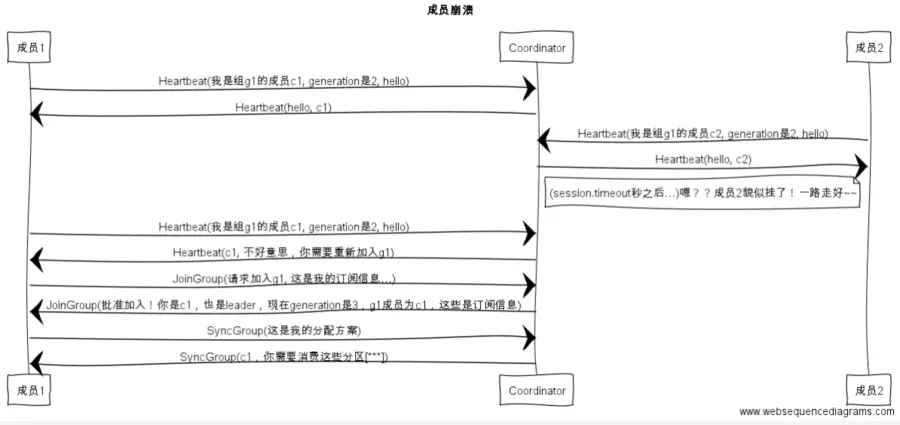
(2)组成员“崩溃”,造成kafka被动Rebalance,这样就会触发The coordinator is not aware of this member.报错,我猜测我的报错可能就是这个原因。
因为在崩溃时成员并不会主动地告知coordinator此事,coordinator有可能需要一个完整的session.timeout周期(心跳周期)才能检测到这种崩溃,这必然会造成consumer的滞后。可以说离开组是主动地发起rebalance;而崩溃则是被动地发起rebalance。
第三步
分析造成组成员“崩溃”的原因:
参考资料:https://blog.csdn.net/u013256816/article/details/82804525
他这里面的原因和我问题的原因可能不是相同,但是也可以作为一个排除点来看一下。
查看Linux的软硬连接限制数:
ulimit -Hn
ulimit -Sn
查看kafka创建链接数:
ls /proc/[kafka进程号]/fd | wc -l
看是否超出了Linux的最大限制

第四步
后来发现上面的原因分析有点走偏了,都开始找系统的错误了,肯定是我的某些地方做错了。
再分析,分析造成Kafka的group协调器不认识该成员的原因:
很有可能是因为心跳检测已经检测不到它了,所以小组管理员就默认它死掉了,但是它真的死了吗?可能还没有。有可能只是它在忙别的事情,没听到组长叫它,所以就认定死亡了,继而又被活埋了。造成了自动提交offset失败。
第五步
分析心跳检测失败的原因:
一般来说producer的生产消息的逻辑速度都会比consumer的消费消息的逻辑速度快,当producer在短时间内产生大量的数据丢进kafka的broker里面时,kafka的consumer会出现以下行为:
(1)kafka的consumer会从broker里面取出一批数据,给消费线程进行消费;
(2)由于取出的一批消息数量太大,consumer在session.timeout.ms时间之内没有消费完成;
(3)consumer coordinator 会由于没有接受到心跳而挂掉,并且出现一些日志(报错日志在上面);
(4)日志的意思大概是coordinator挂掉了,然后自动提交offset失败,然后重新分配partition给客户端;
(5)由于自动提交offset失败,导致重新分配了partition的客户端又重新消费之前的一批数据;
(6)接着consumer重新消费,又出现了消费超时,无限循环下去。
这应该是报错的一个重要原因。
4.报错解决
第一步
查看kafka的进程号
第二步
进入kafka的进程目录查看:
cd /proc/11298/fd

可以看到里面有很多软连接,而且绝大多数都是失效的软连接,这样就很懵逼了,不知道这是什么操作。但是可以看到里面还有几个正常的日志文件,挨个打开看一下。
第三步
查看log文件,看看有没有异常
查看controller.log
第四步
上面这条路走不通了! 换了一条路...
针对上面原因第五步,提出优化方案:
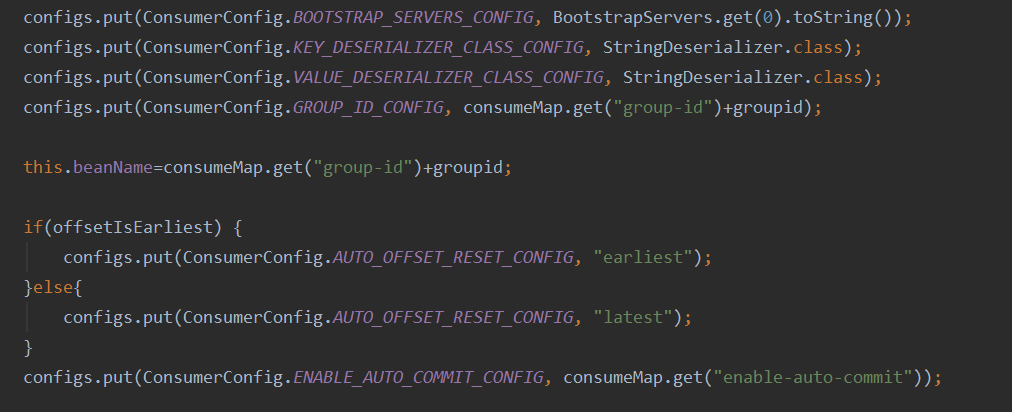
(1)配置方面,要使consumer和patition一一对应,如果有多个patition,最好要均衡每个patition的数据量,防止出现数据倾斜,导致某个consumer挂掉;
(2)配置方面,提高了partition的数量,从而提高了consumer的并行能力,从而提高数据的消费能力;
(3)配置方面,auto.commit.interval.ms 大一点,但是治标不治本;
(4)对于单partition的消费线程,增加了一个固定长度的阻塞队列和工作线程池进一步提高并行消费的能力(未验证过);
(5)代码方面,把kafka-client的enable.auto.commit设置成了false,表示禁止kafka-client自动提交offset,下面是我们项目中的自动提交设置,把它设置成flase,很有可能是一个优化点,但是这里设置成手动提交可能会有未知错误产生,要验证一下。