目录
一、什么是elk. 1
二、ELK 常用架构及使用场景介绍... 2
1、最简单架构... 2
2、以Logstash 作为日志搜集器... 2
3、以Beats 作为日志搜集器... 3
4、引入消息队列模式... 3
三、基于 Filebeat+ELK架构的配置部署详解... 4
1、安装jdk. 5
2、安装elasticsearch. 5
3、安装kibana. 7
4、安装logstash. 8
5、安装filebeats. 9
一、什么是elk
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
- Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
- Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
- Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
- Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
二、ELK 常用架构及使用场景介绍
1、最简单架构
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
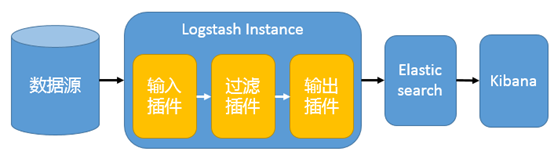
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作
2、以Logstash 作为日志搜集器

这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
3、以Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
- Packetbeat(搜集网络流量数据);
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
- Filebeat(搜集文件数据);
- Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
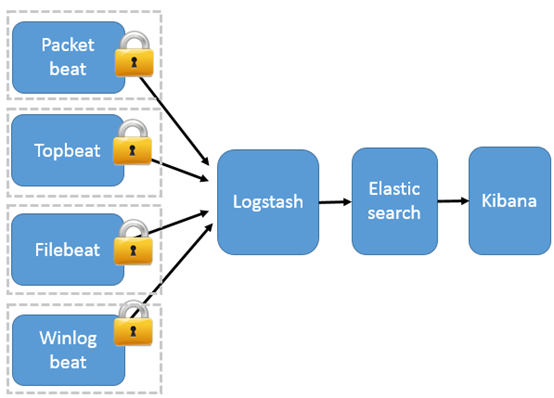
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
4、引入消息队列模式
Beats 还不支持输出到消息队列(新版本除外:5.0版本及以上),所以在消息队列前后两端只能是 Logstash 实例。logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
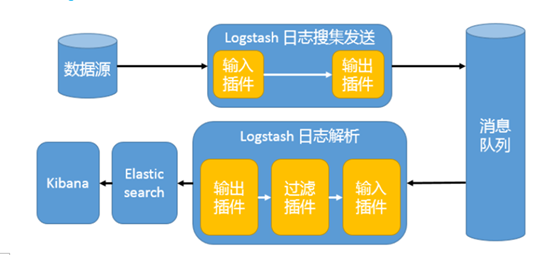
模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题
工作流程:Filebeat采集—> logstash转发到kafka—> logstash处理从kafka缓存的数据进行分析—> 输出到es—> 显示在kibana
三、基于 Filebeat+ELK架构的配置部署详解
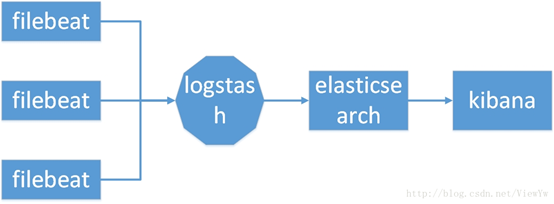
1、Filebeat负责收集应用写到磁盘上的日志,并将日志发送给logstash
2、logstash处理来自filebeat的日志,并将处理后的日志保存elasticsearch索引库。
3、elasticsearch存储来自logstash的日志。
4、kibana从elasticsearch搜索日志,并展示到页面。
系统环境及软件:
centos7.5,java8
Filebeat,logstash,elasticsearch,kibana(可以去官网下载,这里用的版本是6.8.1)
1、安装jdk
至少jdk 7以上。一般推荐使用 Oracle JDK 1.8 或者 OpenJDK 1.8。我们这里使用 Oracle JDK 1.8。
mkdir /usr/java tar xf jdk-8u171-linux-x64.tar.gz mv jdk1.8.0_171/ /usr/java/jdk1.8
#添加java环境变量
echo 'export JAVA_HOME=/usr/java/jdk1.8' >>/etc/profile echo 'export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar' >>/etc/profile echo 'export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH' >>/etc/profile source /etc/profile java -version
2、安装elasticsearch
2.1创建用户
出于安全考虑,elasticsearch默认不允许以root账号运行。
groupadd es useradd -g es es echo "123456"|passwd --stdin es
2.2 调整系统参数
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf sysctl -p
vim /etc/security/limits.conf ==》新增如下内容 * soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536
2.3 安装配置es
[root@linux01 ~]# tar xf elasticsearch-6.8.1.tar.gz [root@linux01 ~]# mv elasticsearch-6.8.1 /usr/local/elasticsearch [root@linux01 ~]# cd /usr/local/elasticsearch/config/ [root@linux01 config]# cp elasticsearch.yml elasticsearch.yml.bak [root@linux01 config]# > elasticsearch.yml [root@linux01 config]# vim elasticsearch.yml #配置文件修改成如下 cluster.name: "elasticsearch_petition" node.name: node-01 transport.host: 0.0.0.0 transport.publish_host: 0.0.0.0 transport.bind_host: 0.0.0.0 network.host: 0.0.0.0 http.port: 9200 path.data: /usr/local/elasticsearch/data path.logs: /usr/local/elasticsearch/logs http.cors.enabled: true http.cors.allow-origin: "*" [root@linux01 config]# mkdir /usr/local/elasticsearch/data [root@linux01 config]# mkdir /usr/local/elasticsearch/logs [root@linux01 ~]# chown -R es.es /usr/local/elasticsearch/
2.4启动
su - es /usr/local/elasticsearch/bin/elasticsearch & #启动比较慢,稍等几分钟
2.5 验证 elasticsearch
[es@linux01 ~]$ curl 127.0.0.1:9200 #出来以下内容,安装成功 { "name" : "node-01", "cluster_name" : "elasticsearch_petition", "cluster_uuid" : "jPmcOZu5Rfi5JOq1wsWUSQ", "version" : { "number" : "6.8.1", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "1fad4e1", "build_date" : "2019-06-18T13:16:52.517138Z", "build_snapshot" : false, "lucene_version" : "7.7.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
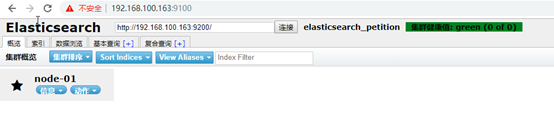
2.6 安装head插件(非必须安装)
elasticsearch-head是Elasticsearch的图形化界面,方便用户对数据进行增删改查,基于REST的进行数据交互。
head插件维护地址:https://github.com/mobz/elasticsearch-head
直接使用docker启动head
docker run -p 9100:9100 mobz/elasticsearch-head:5
访问:
3、安装kibana
3.1解压
[root@linux01 ~]# tar xf kibana-6.8.1-linux-x86_64.tar.gz [root@linux01 ~]# mv kibana-6.8.1-linux-x86_64 /usr/local/kibana
3.2修改配置文件
[root@linux01 ~]# grep '^[a-Z]' /usr/local/kibana/config/kibana.yml server.port: 5601 server.host: "0.0.0.0" #监听地址 elasticsearch.hosts: ["http://192.168.100.163:9200"] #es地址 kibana.index: ".kibana" #在es中添加.kibana索引 i18n.locale: "zh-CN" #设置为中文
3.3 后台运行 Kibana:
[root@linux01 ~]# /usr/local/kibana/bin/kibana &
3.4 浏览器访问:http://ip:5601
4、安装logstash
4.1解压文件
tar xf logstash-6.8.1.tar.gz mv logstash-6.8.1 /usr/local/logstash
4.2新增测试配置文件
[root@linux01 ~]# cat /usr/local/logstash/config/logstash-sample.conf input { beats { port => "5044"} } output { elasticsearch {hosts => "192.168.100.163:9200" } #elasticsearch服务地址 stdout { codec=> rubydebug } }
4.3 启动
[root@linux01 config]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/logstash-sample.conf
5、安装filebeats
5.1解压
[root@linux01 ~]# tar xf filebeat-6.8.1-linux-x86_64.tar.gz [root@linux01 ~]# mv filebeat-6.8.1-linux-x86_64 /usr/local/filebeat
5.2修改配置文件
cd /usr/local/filebeat/ vim filebeat.yml
#=========================== Filebeat inputs ==================== filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true #注意是否为true # Paths that should be crawled and fetched. Glob based paths. paths: - /var/log/messages #收集日志路径 #- c:programdataelasticsearchlogs* # Exclude lines. A list of regular expressions to match. It drops the lines that are # matching any regular expression from the list. #exclude_lines: ['^DBG'] #-------------------------- Elasticsearch output ------------------------------ # Elasticsearch这部分全部注释掉 #output.elasticsearch: # Array of hosts to connect to. #hosts: ["localhost:9200"] #----------------------------- Logstash output -------------------------------- output.logstash: #去掉注释 # The Logstash hosts hosts: ["192.168.100.163:5044"] #logstash地址
filebeat.yml 配置的主要有两个部分,一个是日志收集,一个是日志输出的配置。
配置解释:
type: log 读取日志文件的每一行(默认)
enabled: true 该配置是否生效,如果改为false,将不收集该配置的日志
paths: 要抓取日志的全路径
fields: 自定义属性,可以定义多个,继续往下排就行
multiline.pattern: 正则表达式
multiline.negate: true 或 false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
multiline.match: after 或 before,合并到上一行的末尾或开头
exclude_lines: ['DEBUG'] 该属性配置不收集DEBUG级别的日志,如果配置多行 这个配置也要放在多行的后面
192.168.100.163:5044 为输出到Logstash的地址和端口。
5.3 启动服务
./filebeat -e -c filebeat.yml
5.4 添加索引到kibana

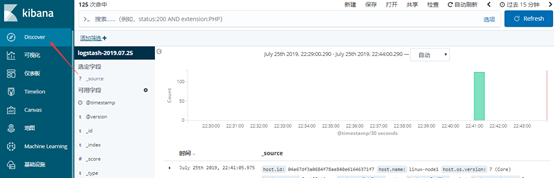
至此ELK+Filebeat已全部连通