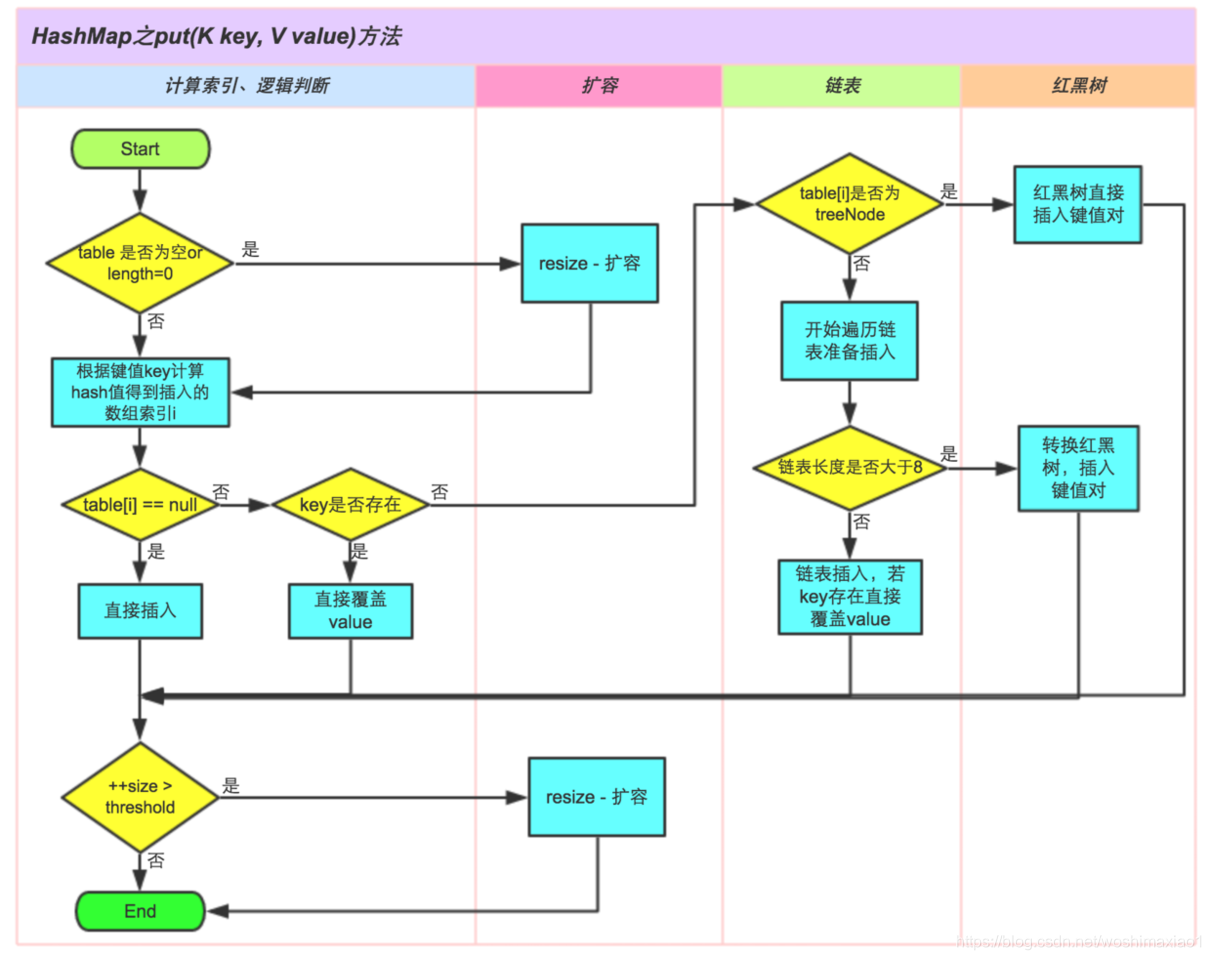
JDK 1.7和1.8中的HashMap区别
1.7中HashMap基于数组+线性链表的结构存储数据,核心内容有以下几点:
- 数组特点:通过指定下标查找时间复杂度为O(1),通过定值查找,需要遍历数组,逐一对比给定关键字和数组元素,时间复杂度为O(n)。当然,如果是有序数组,则可通过二分查找、插值查找、斐波那契查找等方式,优化查找复杂度为O(logn);对于一般插入删除操作,因为涉及数组的移动,其平均时间复杂度也为O(n);
- 线性链表特点:对于链表的新增、删除等操作(在找到指定操作位置后),仅需要处理结点的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一对比,复杂度为O(n);
- 默认数组大小为16,在插入新数据时可能会扩容,每次扩容的容量为2的次幂;之所以这样是因为要保证hash之后的数组存放均匀分布: 数组位置index= hash(value) & (n-1), n当前容量,为2的n次幂时,为111....11的结构,通过与运算,使得index的位置分布与hash正相关,尽管如此因为有hash冲突,所以相同的位置有链表依次存放节点数据;
- HashMap每次扩容,需要重新计算hash之后的存放位置index,比较损耗性能;
数组结构:
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
线性链表结构:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
1.8中HashMap当线性链表长度大于8时,会转换为红黑树结构(一种自平衡二叉查找树(AVL)的变体,左右子树高差可能大于1,对其进行插入,查找,删除等操作,平均复杂度均为O(logn))