输入和输出都是sequence的任务都是一种Sequence-to-sequence Learning,简称Seq2Seq。
Attention其实是一种Dynamic Conditional Generation。在前文描述的Conditional Generation中,我们在每个时间点都将Encoder输出的vector输入到Decoder中,其实我们可以进一步使得Decoder在每个时间点接收到的vector都是不一样的,这就是Attention。Attention有两个好处,第一是应对Encoder输出的vector无法充分有效地表示整个setence的情况,第二是使Decoder在不同时间点关注setence的不同部分(假如要把“机器学习”翻译为“machine learning”,那么在翻译“机器”时就不需要关注“学习”这个暂时无关的word)。
Machine Translation
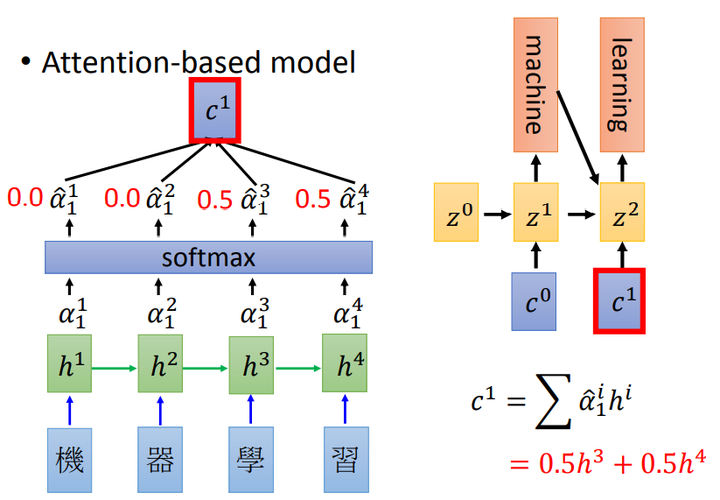
如上图所示,(h^1,h^2,h^3,h^4)是作为Encoder的RNN中隐藏层的输出,一种方法是(z)为Decoder的输出,(z^0)即时间点为0时的一个初始值。
-
使用
match函数计算(h^i)和(z^0)的匹配程度(alpha_0^1,alpha_0^2,alpha_0^3,alpha_0^4),举例来讲(alpha_0^1)中上标(1)表示(h^1)、下标(0)表示时间点为0。match函数是自定义的,它可以只是一个cosine similarity也可以是一个神经网络等等,如果match函数中包括参数,那这些参数也是可以通过学习得到的。 -
将(alpha_0^1,alpha_0^2,alpha_0^3,alpha_0^4)输入到softmax得到(hatalpha_0^1,hatalpha_0^2,hatalpha_0^3,hatalpha_0^4)
softmax使得这4个值之和为1,有人说这一步也可以不做
-
计算Encoder的输出(c^0=sumlimits_ihatalpha_0^ih^i)
若(hatalpha_0^1=hatalpha_0^2=0.5, hatalpha_0^3=hatalpha_0^4=0),则代表Encoder只考虑了“机器”二字而没有考虑“学习”二字,由此实现Attention
-
将(c^0)输入到Decoder得到
得到(z^1)后也就得到了“machine”
按照上述步骤,使用(h^i)和(z^1)计算出(alpha_1^1,alpha_1^2,alpha_1^3,alpha_1^4),再用softmax计算出(hatalpha_1^1,hatalpha_1^2,hatalpha_1^3,hatalpha_1^4),再计算出(c^1=sumlimits_ihatalpha_1^ih^i),再将(c^1)输入到Decoder得到(z^2),也就得到了“learning”。
重复上述过程直到生成句子的结束(句号)。
Speech Recognition
Attention也可以应用于语音识别。在语音识别中, 输入是声音信号(可以用vector sequence表示),输出是word sequence。
Attention在Speech Recognition中的应用类似于其在Machine Translation中的应用,算法步骤差不多,谷歌有一篇相关论文:《Listen, Attend and Spell》
Image Caption
Attention在Image Caption中的应用类似于其在Machine Translation中的应用,可以将图片的每个region视为Machine Translation任务中的一个character,有一篇相关文章是《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》。
Attention不只可以做单张Image的Caption,还可以做多张图片/视频的Caption,相关论文如《Describing Videos by Exploiting Temporal Structure》。
Memory Network
Memory Network是在Memory上做Attention。Memory Network最开始是被用在Reading Comprehension上, 也就是给机器看一个document,然后问机器一个question并让它给出answer。
-
将document表示为多个vector
document由很多个sentence组成,可以用一个vector表示一个sentence,因此一个document可以表示为(x^1,x^2,dots,x^N)
这一步可以和后面的DNN一起训练
-
将question表示为一个vector (q)
-
计算(q)和每个(x^n)之间match的分数(alpha_1,alpha_2,dots,alpha_N)
-
计算(e=sumlimits_{n=1}limits^Nalpha_nx^n)得到extracted information
这一步的作用是提取出和question相关的setence,由此实现Attention
-
将extracted information输入到DNN,输出对应的answer
Memory Network还有一个更加复杂的版本。可以将document表示为不同的两组vector,即使用两个vector (h^n)和(x^n)表示document中的每个sentence,然后计算(q)和每个(x^n)之间match的分数(a_n),此时extracted information为(e=sumlimits_{n=1}limits^Nalpha_nh^n)。将extracted information输入到DNN得到对应的answer,同时还可以将extracted information和问题(q)加起来更新(q)(这叫做Hopping)。Hopping可以重复很多次,这就像机器在反复思考。
相关论文:《End-To-End Memory Networks》
Neural Turing Machine
Neural Turing Machine不只是在Memory上做Attention、不只是可以读取memory,它还可以根据match 函数的结果修改存储在memory中的内容。
-
在Neural Turing Machine中,memory是一个vector sequence
-
在初始时,memory表示为(m_0^1,m_0^2,dots,m_0^N),然后有一组初始的attention weight:(hatalpha_0^1,hatalpha_0^2,dots,hatalpha_0^N),计算(r^0=sumhatalpha_0^im_0^i)
-
将(r^0)和第一个时间点的输入(x^1)输入到一个网络(f),得到输出(k^1,e^1,a^1)
这个网络(f)其实就是一个controller,它可以是一个DNN、LSTM、GRU等等都可以。
(k^1)的作用就是产生attention:(alpha^i_1=cos(m_0^i,k^1)),然后用softmax处理(alpha^i_1)即可得到(hatalpha_1^i),这里讲的生成attention的方法(alpha^i_1=cos(m_0^i,k^1))是简化过的版本,真正的通过(k^1)计算得到(alpha^i_1)的方法更为复杂。
根据attention weight (hatalpha_1^i)和(e^1,a^1)就可以修改memory,(e^1)的作用是把memory中的值清空(erase),(a^1)的作用是把新的值写到memory里。(m_1^i=m_0^i-hatalpha_1^ie^1odot m_0^i+hatalpha_1^ia^1),通常attention weight (hatalpha)的分布会比较sharp,即其中某一维接近1而其它维都接近0,因此可以控制(e^1,a^1)清空或写入memory中的哪个值。
Pointer Network
Pointer Network用来求解凸包(Convex Hull)。
求解凸包问题中,输入和输出都是一个point sequence。
假如使用Seq2Seq求解凸包问题,每个point用其x和y坐标表示,那输入就是多个point,输出则是point的索引,这样不可行。如果Encoder是RNN则可以处理point数量不确定的输入,但假如在训练时输入中最多只有50个point,而如果测试时需要输出100个point,那Decoder就无法输出51-100,因此这种方法是不可行的。
我们可以使用Attention Model,假设有一个key (z^0),使用(z^0)为输入中的每个point计算attention weight,选择attention weight最大的那个point,模型输出即该point的索引,这样不管输入了多少个point,都能正确输出point的索引。使用输出的point的x和y坐标计算得到(z^1),然后用(z^1)计算输入中每个point的attention weight,并选择attention weight最大的那个point,输出该point的索引。重复以上过程直到输出END。
-
Summarization
可以将summarization理解为求解凸包一样的问题:从一个document中选择几个word,详见《Get To The Point: Summarization with Pointer-Generator Networks》。
-
Machine Translation
比如在将英语翻译为法语时,一些word并不用进行翻译,通过Pointer Network提取出来直接用就好了。
-
Chat-bot
比如用户说“我叫臭咸鱼”,就可以通过Pointer Network将“臭咸鱼”这个word直接提取出来。
Recursive Network
Recursive Network是Recurrent Neural Network的泛化版本,Recurrent Neural Network其实是Recursive Network的subset。
如下图所示,以Sentiment Analysis为例,输入为一个word sequence,输出为sentiment(假设是5级),输入的word sequence(假设有4个word)经过word embedding可以表示为vector sequence (x^1, x^2, x^3, x^4),输出是一个5维的vector。
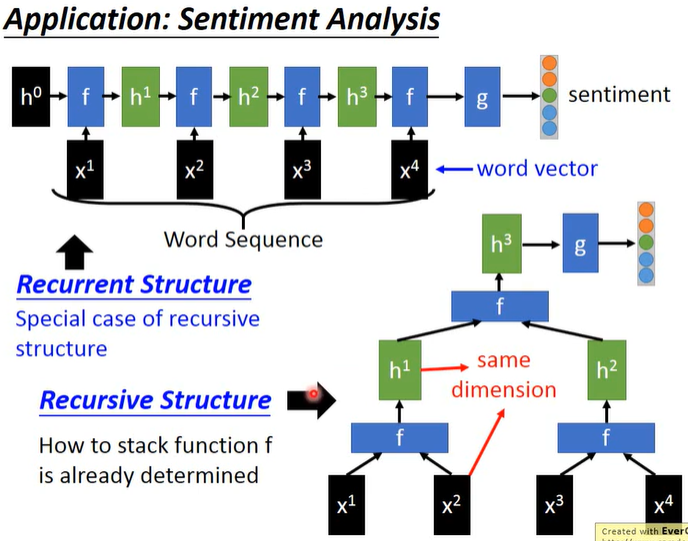
如上图所示,如果用Recurrent Neural Network实现Sentiment Analysis,初始有一个值(h^0),我们的RNN是(f),将(h^0,x^1)输入到(f)得到(h^1),再将(h^1,x^2)输入到(f)得到(h^2),再将(h^2,x^3)输入到(f)得到(h^3),再将(h^3,x^4)输入到(f)中得到(h^4),将(h^4)输入到模型(g)(可以是几个层)中得到最终的sentiment。
如上图所示,如果用Recursive Structure实现Sentiment Analysis,需要先确定word和模型输出之间的关系,比如(x^1)和(x^2)、(x^3)和(x^4)分别是两组,我们的模型是(f),将(x^1,x^2)输入到(f)中得到(h^1),将(x^3,x^4)输入到(f)中得到(h^2),将(h^1,h^2)输入到(f)中得到(h^3),再把(h^3)输入输入到模型(g)(可以是几个层)中得到最终的sentiment。因为模型(f)的输入可以是(x^i)或(h^i),所以需要使得(x^i)和(h^i)的维度相同。
与Recursive Network相关的模型有:Recursive Nerual Tensor Network、Matrix-Vector Recursive Network、Tree LSTM。
除了Sentiment Analysis,Recursive Network还可以用来处理其它与sentence相关的任务。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!