2020-04-22
关键字:socket通信时的底层调用流程
这篇文章简单记录一下在Linux环境下使用C语言做 socket 通信时的一些流程。
1、sockfd的由来
典型的C语言建立socket通信的第一行代码基本都如下所示:
int sockfd = socket(AF_INET, SOCK_DGRAM, 0); //UDP通信 int sockfd = socket(AF_INET, SOCK_STREAM, 0); //TCP通信
sockfd 就代表本次socket连接的文件句柄,后续的通信我们只需要像对待普通文件一样往这个文件句柄中读写数据即可实现socket通信的过程。
但这简简单单的一行语句,它的底层逻辑是怎样的呢?sockfd 到底是怎样分配出来的呢?
通过查询Linux中的编程手册
man socket
可以发现,socket 函数是一个系统调用函数。它的原型如下:
#include <sys/types.h> /* See NOTES */ #include <sys/socket.h> int socket(int domain, int type, int protocol);
既然是系统调用,就意味着它的源码实现在 kernel 层。
在Linux系统源码目录,或Android系统源码目录下,./kernel/net 目录的代码就是 socket 相关的源码实现。
其中,socket() 函数的源码实现位于:
./kernel/net/socket.c
因为 socket 源码在目前来说是一个应用相当广泛且成熟的代码体系,因此,可以认为所有基于Linux平台下的socket的实现都是一致的。
在 socket.c 文件的第 1361 行可以发现对 socket 函数声明为系统调用的代码实现,如下图所示:
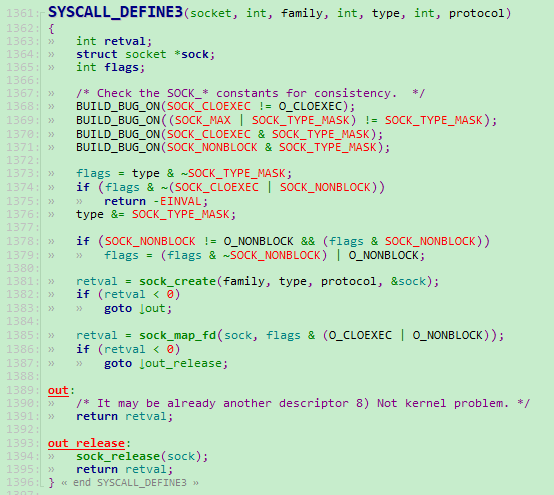
上图所示代码中的 SYSCALL_DEFINE3 是一个系统定义的宏。在这里我们没有必要深究它的实现原理,只需要知道经过这样的声明以后,系统中就多了一个函数名称为 socket 的系统调用函数了,且我们在用户态调用 socket() 函数时它最终会执行到这里来就可以了。
SYSCALL_DEFINE3 的定义位于以下文件中:
kernel/include/linux/syscalls.h
言归正传。
在上图所示代码中,我们可以发现在第 1385 行有一句 retval = sock_map_fd() 的代码。这句代码就是用来分配我们的 sockfd 以及创建一个对应文件并绑定标准的文件IO操作函数实现的地方了。我们跟进去看看。
sock_map_fd() 函数的实现也在 socket.c 代码文件中。它的源码较为简单,如下图所示:

上图中第390行根据函数的名称我们就能猜到它就是用于向系统申请一个可用的文件描述符fd的,也就是我们在应用程序中拿到的 sockfd 了。由于Linux系统会为每个进程都开辟一个文件描述符池专门用于保存管理在该进程中打开的所有文件的fd。因此,这个 get_unused_fd_flags() 函数的内部实现我们猜也能猜得到了,就是取出调用这个函数的进程的文件描述符池里最近的(或者说最小的)可用的文件描述符。若当前没有可用的fd,则返回一个负的值。因此,这个函数我们就不再细跟了。
这就是 sockfd 的由来。
但 sockfd 的本质仅仅是一个数字值而已。想要能响应标准的文件操作,如 open()、 read()、 write()、 close() 等,还得再绑定上一个标准的 file_operations 结构体实现才行。
这个操作就位于上图所示代码的第 394 行的 sock_alloc_file() 函数中。
sock_alloc_file() 函数的实现仍然在 socket.c 中,如下图所示:
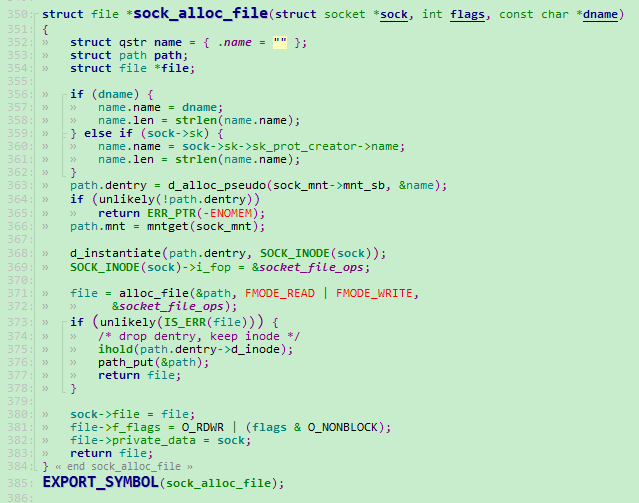
老实说,这个函数的目的也很明显,猜也猜得到它就是创建一个文件,然后再绑定上对应的文件操作函数就是了。
这个函数前面几行我们不必理会,它的目的是要为这个进程或者说这个socket确定一个保存即将要创建的文件的路径的。笔者没去研究过这块的详细实现,但看样子这个路径可能是一个虚拟路径,不会实际落地到设备磁盘上去的。
我们重点关注一下上图代码的第 371 行。它直接为 struct file 申请了一段内存。在Linux内核中用 struct file 来描述一个文件。第三个参数 socket_file_ops 就是一个标准的 struct file_operations 结构体了。它在这里的实现如下图所示:
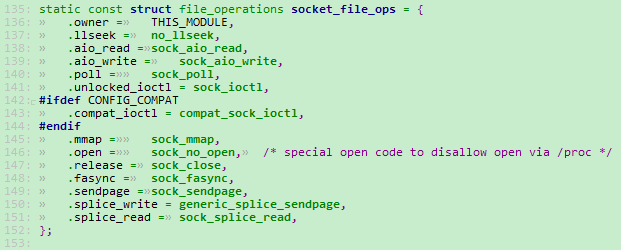
这下终于明了了。open、close、read、write都有了。
不过需要强调一下,sockfd 对读写的响应函数注册的是 .aio_read 和 .aio_write。它们是“异步读写”的意思。我们在用户态的应用程序中对 sockfd 写数据的时候,在socket底层是直接将用户态的数据转移到socket层的缓冲区中的,然后立即给应用程序返回结果。至于这些数据什么时候才通过网口发送出去就看下面的程序的调度了。不过其实socket的数据缓冲区也是有限的,当这个缓冲区满了的时候,应用层的write()调用还是会进入阻塞状态。它的这个“异步”准确来说只是数据到网口的“异步”而已。
2、数据在socket中的传递流程
前面讲到的 socket() 函数的调用,仅仅是在本地做一些通信前的准备而已。想要能真正实现通信,还得经过bind、connect等函数的调用。
不管是TCP还是UDP,在建立连接的时候都要先“探测路由”,TCP是发生在 connect() 被调用的时候,UDP是发生在每次要发送数据的时候。探测路由说白了就是发一些网络数据出去,看我的数据能否被接收端接收到。
这个“探测路由”就位于以下代码文件中:
./kernel/net/ipv4/route.c
这里我们只讨论 ipv4 情况下的 socket 通信。所有 ipv4 下的 socket 通信的代码实现都在 ./kernel/net/ipv4 目录下。
TCP下的发送数据流程大致如下,仅供参考:
tcp.c int tcp_sendmsg(...) ip_output.c int ip_output(...) static int ip_finish_output() static inline int ip_finish_output2() ./kernel/include/net/dst.h static inline int dst_neigh_output() ./kernel/include/net/beighbour.h static inline int neigh_hh_output() ./kernel/net/core/dev.c int dev_queue_xmit() static inline int __dev_xmit_skb() ./kernel/net/sched/sch_generic.c int sch_direct_xmit() ./kernel/net/core/dev.c int dev_hard_start_xmit()
最后在 dev.c 的 dev_hard_start_xmit() 函数中有一句代码 rc = ops->ndo_start_xmit(skb, dev); 会调到网卡驱动程序中的函数注册中去。
在写网卡驱动的时候必须要注册这个 ndo_start_xmit() 函数,如下图所示:

这个函数已经是最底层了,它要做的事应该就是直接将数据往网线里送了。毕竟当数据到达这个函数时,所有该封的协议都已经封装好了。ndo_start_xmit 函数已经属于“数据链路层”到“物理层”之间的过渡了。
以上就是TCP下发送数据的大致流程。至于接收和UDP的流程就不贴了,大同小异的。