2019-08-18
关键字:Linux集群、集群服务器、负载均衡集群、高可用集群
互联网的核心组件是各种服务站点。例如购物领域我们有淘宝、京东、拼多多等,出行领域我们有滴滴、首约、货拉拉等,通讯领域则有微信、QQ等。这些服务站点的背后是靠一台台性能出众的电脑来提供各种服务的。但随着互联网所覆盖的人群越来越广、在人们生活中的渗透越来越深,我们每时每刻所发起的服务请求都都是海量的,而单台计算机的计算能力又是极其有限的。为了满足日益增长的计算需求,就产生了一种被称为 “服务器集群” 的计算服务模式。这种 “服务器集群” 又可以提供一种被称为 “分布式计算” 的功能,使得有相关计算需求的企业或组织可以通过增加计算机数量的方式来曲线解决海量计算需求。可以说,服务器集群是每一家有大量计算需求企业的刚需。
什么是服务器集群?
服务器集群就是由多台计算机就某一特定的计算主题而组成的具有协同分工特性并对外表现为一个整体的计算模式。通常而言集群的共同宗旨都是在降低单台服务器计算压力的同时提升整体计算能力。
举个例子,假如你是一家大型图书馆的馆长。现在要对馆中图书做盘点。图书盘点就相当于大量计算需求,请一个人来做,就相当于将大量计算需求交由一台服务器来做,那这个人的工作压力肯定是异常巨大,很有可能做到一半他就不干了,就算能保证不中途罢工,那等他盘点完都不知道到猴年马月去了。所以,为了提升盘点效率,你必须聘请多个人来共同完成,给不同的人委派不同的盘点任务,这种模式才是最合理的图书盘点模式。服务器集群就是这个样子的。为了完成图书盘点的任务,聚集了多个人一起来完成,每个人做不同的任务,对你这个馆长来说,这一群人就是一个整体,因为你只下达了一个盘点图书的任务,过了一段时间盘点结果就呈现在你眼前了。
在集群中,每一台计算机都有一个专业称谓:节点。对于集群而言,它的优缺点也显而易见,它对业务的处理能力理论上可以无上限,能显著提升业务处理效率,也能实现业务无中断,但它同时也需要高昂的搭建与维护成本。
对集群而言,要提升计算能力也很简单,直接增加节点即可。对集群而言,不停服扩充节点是非常容易实现的,更有意思的是,集群对于节点性能的要求很宽松,我们完全可以将性能更好的计算机作为新节点添加进去,这对于集群而言,完全可以实现不停服就将节点进行大换血操作。
集群的分类
常见的集群共有三种:
1、负载均衡集群
2、高可用集群
3、高性能科学计算集群
负载均衡集群
负载均衡集群是最常见的,应用最广泛的服务器集群类型。它的宗旨是分担服务的总体压力。它的工作方式是根据一定的规则,将不同来源的请求分发到不同节点上进行处理。
负载均衡集群可以分为软件型和硬件型两种。软件型负载均衡主要有三种:1、LVS;2、NGINX;3、HAPROXY。硬件型一般接触的比较少。软件型中又数 LVS 和 NGINX 的用的比较多。目前 LVS 已经集成到 Linux 内核中去了。
负载均衡集群的架构通常如下图所示
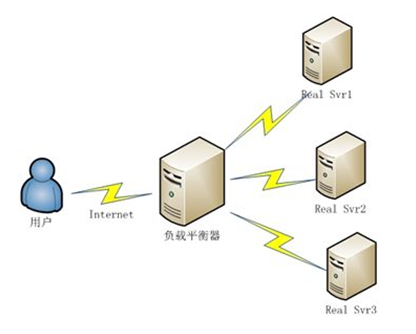
它主要由两种结构组成:
1、调度器;
2、业务处理节点;
负载均衡集群的工作模式是客户端的请求只发给调度器节点,调度器节点在收到请求以后会根据既定的规则来将这一请求转发给业务处理节点进行业务处理。虽然调度器节点不参与实际的业务处理,但是它的通信压力也是非常大的。
调度器
调度器中的核心部分在于调度算法。调度算法可以分为静态算法与动态算法。静态算法就是在分发请求时严格按照算法规则进行请求分发的模式,而动态算法则会在分发前先对当前集群各节点的负载情况进行调研,在综合了当前节点资源占用情况与算法本身以后再决定将客户端的请求委派给哪一个节点处理。显然,动态算法会有更好的表现,但同时它所占用的资源也会更多一点。
静态调度算法主要有:
1、轮询;
2、加权轮询;
3、源地址散列;
4、目标地址散列;
动态调度算法主要有:
1、最少连接算法;
2、加权最少连接算法;
3、最短期望延时;
4、永不排队;
轮询算法与最少连接算法是最简单最机械的算法了。前者是给节点依次派发请求,后者也差不多,区别就是哪个节点当前连接数最少就给谁派发,也就是谁的压力最小谁就能分到任务。
在轮询与最少连接的基础上有一个升级版的算法,就是加权型算法。所谓加权就是给每个节点设置一个 “评分”,这个评分通常是按照节点的性能来评的。因为不同节点有可能会有不同的计算能力,为了更好地平摊计算量,让集群资源利用的更合理,计算能力强的理应分得更多的计算任务,正所谓“能者多劳”嘛。
源地址散列则是将所有来源相同的请求都分发到同一个节点去处理,这种算法适用于需要验证登录凭据的场景。
目标地址散列则是将所有访问服务端相同资源的请求都发发到同一个节点。这种算法适用于业务处理节点需要从其它地方取数据的场景,这种情况下应用这种算法能提升缓存命中率,节约服务端的压力。
高可用集群
高可用集群的宗旨是最大限度地保证服务不中断。通常衡量一个高可用集群能力时用的都是多少个 9 的标准,就是一年当中能正常服务的时间比例。常见的几个标准有:
1、99%
2、99.9%
3、99.99%
4、99.999%
大多数高可用集群能做到三个 9 的标准就不错了,再往上所消耗的成本就比较高了。
高可用集群的目的就是要让服务不中断,即服务器不宕机,但事实上没人能保证某一台计算机能永远不宕机,所以要保证服务不中断,就只能是在服务中断后用最短的时间恢复它。因此高可用所使用的原理也比较简单,就是使用双机热备模式。在需要提供服务的服务器中开启两台业务数据一模一样的节点,最好就连硬件配置也一模一样。一台设为主机,即当前对外提供服务的,另一台设为从机,从机不对外提供任何服务,从机唯一的任务就是同步主机上的业务数据并监控主机的状态。当主机服务中断时,立即接过服务权,将自己设为主机,进而继续对外提供服务。而由于从机中的业务数据与主机几乎是一模一样的,所以这种切换机器的行为并不会对客户的服务造成多大的影响。
高可用集群的技术原理虽然比较简单,但是它同样有一个问题非常需要关注:脑裂现象。
那我们知道从机上位的唯一途径就是监测到当前主机的服务中断。但是,主机的服务是否中断并不是那种“非黑即白”模式的。你从机监测到主机服务中断了,实际上主机的服务并不一定真的就中断了的。如果因为从机错误的判断导致集群中出现多个主机,那就称为出现了脑列现象,脑裂现象的后果可是很严重的。而解决这一问题的办法主要要靠预防,必要时要靠人工干预。不过现在有硬件级防脑裂设备,例如电源交换机。这个东西就比较粗暴了,当从机上位时,它会切断原来主机的电源。
高性能科学计算集群
这种集群离普通人就非常遥远了。它一般是由国家控制的战略型计算资源,普通人是接触不到,也不可接触的集群。
关于服务器集群,还有非常非常多的知识,不过笔者仅仅是出于拓展视野的目的来学习的,到这也基本算是已经扫了个盲了,也就差不多了。